{
"cells": [
{
"cell_type": "markdown",
"id": "3c5d72f4",
"metadata": {},
"source": [
"# DistilBERT Classifier as Feature Extractor"
]
},
{
"cell_type": "markdown",
"id": "bb9d0299-8fc0-48f0-9b02-4c19214d479a",
"metadata": {},
"source": [
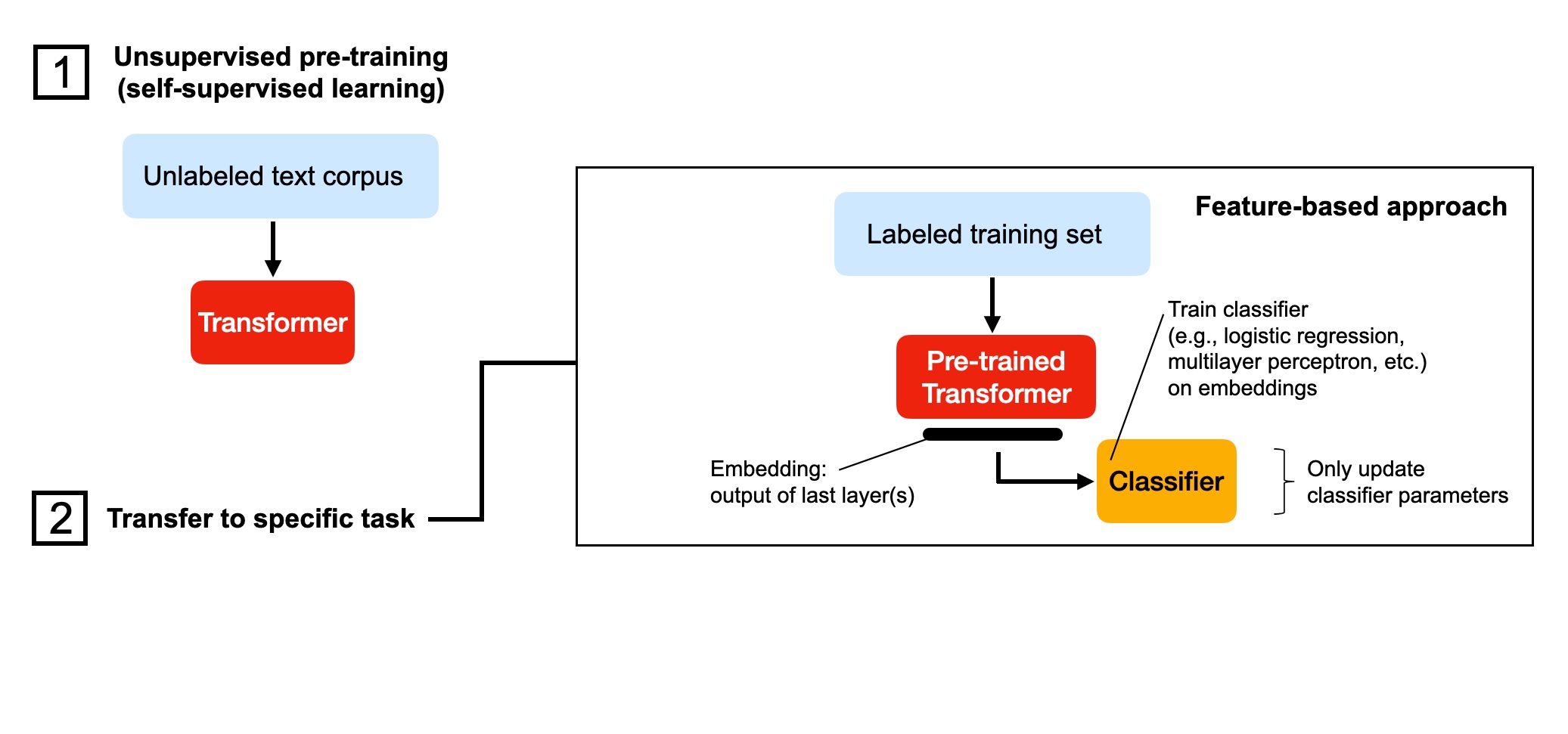
"In this feature-based approach, we are using the embeddings from a pretrained transformer to train a random forest and logistic regression model in scikit-learn:\n",
"\n",
""
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "6fd9cda8",
"metadata": {},
"outputs": [],
"source": [
"# pip install transformers datasets"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "df18e3de-577a-43c5-8b9d-868397a6d7da",
"metadata": {},
"outputs": [],
"source": [
"# conda install sklearn --yes"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "033b75c5",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"torch : 1.12.1\n",
"transformers: 4.23.1\n",
"datasets : 2.6.1\n",
"sklearn : 0.0\n",
"\n",
"conda environment: dl-fundamentals\n",
"\n"
]
}
],
"source": [
"%load_ext watermark\n",
"%watermark --conda -p torch,transformers,datasets,sklearn"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "602ba8a0",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"cuda:0\n"
]
}
],
"source": [
"import torch\n",
"\n",
"device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n",
"print(device)"
]
},
{
"cell_type": "markdown",
"id": "4cfd724d",
"metadata": {},
"source": [
"# 1 Loading the Dataset"
]
},
{
"cell_type": "markdown",
"id": "fd06d930",
"metadata": {},
"source": [
"The IMDB movie review dataset consists of 50k movie reviews with sentiment label (0: negative, 1: positive)."
]
},
{
"cell_type": "markdown",
"id": "60fe0b76",
"metadata": {},
"source": [
"## 1a) Load from `datasets` Hub"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "447e24bb",
"metadata": {},
"outputs": [],
"source": [
"from datasets import list_datasets, load_dataset"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "2baf2f16",
"metadata": {},
"outputs": [],
"source": [
"# list_datasets()"
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "6310d5bf",
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"Found cached dataset imdb (/home/raschka/.cache/huggingface/datasets/imdb/plain_text/1.0.0/2fdd8b9bcadd6e7055e742a706876ba43f19faee861df134affd7a3f60fc38a1)\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "620d4c29e27a4082927c2102e80b2e66",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
" 0%| | 0/3 [00:00
The acting is horrendous... serious amateur hour. Throughout the movie I thought that it was interesting that they found someone who speaks and looks like Michael Madsen, only to find out that it is actually him! A new low even for him!!
The plot is terrible. People who claim that it is original or good have probably never seen a decent movie before. Even by the standard of Hollywood action flicks, this is a terrible movie.
Don't watch it!!! Go for a jog instead - at least you won't feel like killing yourself.\",\n",
" 'label': 0}"
]
},
"execution_count": 8,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"imdb_data[\"train\"][99]"
]
},
{
"cell_type": "markdown",
"id": "40bdb9c5",
"metadata": {},
"source": [
"## 1b) Load from local directory"
]
},
{
"cell_type": "markdown",
"id": "9103ec2d",
"metadata": {},
"source": [
"The IMDB movie review set can be downloaded from http://ai.stanford.edu/~amaas/data/sentiment/. After downloading the dataset, decompress the files.\n",
"\n",
"A) If you are working with Linux or MacOS X, open a new terminal window cd into the download directory and execute\n",
"\n",
" tar -zxf aclImdb_v1.tar.gz\n",
"\n",
"B) If you are working with Windows, download an archiver such as 7Zip to extract the files from the download archive."
]
},
{
"cell_type": "markdown",
"id": "ac508bb8",
"metadata": {},
"source": [
"C) Use the following code to download and unzip the dataset via Python"
]
},
{
"cell_type": "markdown",
"id": "241ecc96",
"metadata": {},
"source": [
"**Download the movie reviews**"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "02aeade4",
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"import sys\n",
"import tarfile\n",
"import time\n",
"import urllib.request\n",
"\n",
"source = \"http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz\"\n",
"target = \"aclImdb_v1.tar.gz\"\n",
"\n",
"if os.path.exists(target):\n",
" os.remove(target)\n",
"\n",
"\n",
"def reporthook(count, block_size, total_size):\n",
" global start_time\n",
" if count == 0:\n",
" start_time = time.time()\n",
" return\n",
" duration = time.time() - start_time\n",
" progress_size = int(count * block_size)\n",
" speed = progress_size / (1024.0**2 * duration)\n",
" percent = count * block_size * 100.0 / total_size\n",
"\n",
" sys.stdout.write(\n",
" f\"\\r{int(percent)}% | {progress_size / (1024.**2):.2f} MB \"\n",
" f\"| {speed:.2f} MB/s | {duration:.2f} sec elapsed\"\n",
" )\n",
" sys.stdout.flush()\n",
"\n",
"\n",
"if not os.path.isdir(\"aclImdb\") and not os.path.isfile(\"aclImdb_v1.tar.gz\"):\n",
" urllib.request.urlretrieve(source, target, reporthook)"
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "2a867dcc",
"metadata": {},
"outputs": [],
"source": [
"if not os.path.isdir(\"aclImdb\"):\n",
"\n",
" with tarfile.open(target, \"r:gz\") as tar:\n",
" tar.extractall()"
]
},
{
"cell_type": "markdown",
"id": "9318d4d0",
"metadata": {},
"source": [
"**Convert them to a pandas DataFrame and save them as CSV**"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "464e587c",
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"100%|███████████████████████████████████████████████████████| 50000/50000 [00:55<00:00, 901.12it/s]\n"
]
}
],
"source": [
"import os\n",
"import sys\n",
"\n",
"import numpy as np\n",
"import pandas as pd\n",
"from packaging import version\n",
"from tqdm import tqdm\n",
"\n",
"# change the `basepath` to the directory of the\n",
"# unzipped movie dataset\n",
"\n",
"basepath = \"aclImdb\"\n",
"\n",
"labels = {\"pos\": 1, \"neg\": 0}\n",
"\n",
"df = pd.DataFrame()\n",
"\n",
"with tqdm(total=50000) as pbar:\n",
" for s in (\"test\", \"train\"):\n",
" for l in (\"pos\", \"neg\"):\n",
" path = os.path.join(basepath, s, l)\n",
" for file in sorted(os.listdir(path)):\n",
" with open(os.path.join(path, file), \"r\", encoding=\"utf-8\") as infile:\n",
" txt = infile.read()\n",
"\n",
" if version.parse(pd.__version__) >= version.parse(\"1.3.2\"):\n",
" x = pd.DataFrame(\n",
" [[txt, labels[l]]], columns=[\"review\", \"sentiment\"]\n",
" )\n",
" df = pd.concat([df, x], ignore_index=False)\n",
"\n",
" else:\n",
" df = df.append([[txt, labels[l]]], ignore_index=True)\n",
" pbar.update()\n",
"df.columns = [\"text\", \"label\"]"
]
},
{
"cell_type": "code",
"execution_count": 12,
"id": "02649593",
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"np.random.seed(0)\n",
"df = df.reindex(np.random.permutation(df.index))"
]
},
{
"cell_type": "markdown",
"id": "59ca0386",
"metadata": {},
"source": [
"**Basic datasets analysis and sanity checks**"
]
},
{
"cell_type": "code",
"execution_count": 13,
"id": "c2db547a",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Class distribution:\n"
]
},
{
"data": {
"text/plain": [
"array([25000, 25000])"
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"print(\"Class distribution:\")\n",
"np.bincount(df[\"label\"].values)"
]
},
{
"cell_type": "code",
"execution_count": 14,
"id": "a007e612",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(4, 173.0, 2470)"
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"text_len = df[\"text\"].apply(lambda x: len(x.split()))\n",
"text_len.min(), text_len.median(), text_len.max() "
]
},
{
"cell_type": "markdown",
"id": "00f4b04d",
"metadata": {},
"source": [
"**Split data into training, validation, and test sets**"
]
},
{
"cell_type": "code",
"execution_count": 15,
"id": "ff703901",
"metadata": {},
"outputs": [],
"source": [
"df_shuffled = df.sample(frac=1, random_state=1).reset_index()\n",
"\n",
"df_train = df_shuffled.iloc[:35_000]\n",
"df_val = df_shuffled.iloc[35_000:40_000]\n",
"df_test = df_shuffled.iloc[40_000:]\n",
"\n",
"df_train.to_csv(\"train.csv\", index=False, encoding=\"utf-8\")\n",
"df_val.to_csv(\"validation.csv\", index=False, encoding=\"utf-8\")\n",
"df_test.to_csv(\"test.csv\", index=False, encoding=\"utf-8\")"
]
},
{
"cell_type": "markdown",
"id": "2bd5f770",
"metadata": {},
"source": [
"**Load the dataset via `load_dataset`**"
]
},
{
"cell_type": "code",
"execution_count": 16,
"id": "a1aa66c7",
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"Using custom data configuration default-3ba780b1f6e4b45e\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Downloading and preparing dataset csv/default to /home/raschka/.cache/huggingface/datasets/csv/default-3ba780b1f6e4b45e/0.0.0/6b34fb8fcf56f7c8ba51dc895bfa2bfbe43546f190a60fcf74bb5e8afdcc2317...\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "7083a3ff6d604445bf7e8ab46b848116",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"Downloading data files: 0%| | 0/3 [00:00\n",
" self.handle.detach()\n",
"ResourceWarning: Enable tracemalloc to get the object allocation traceback\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"0 tables [00:00, ? tables/s]"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"/home/raschka/miniforge3/envs/dl-fundamentals/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py:714: FutureWarning: the 'mangle_dupe_cols' keyword is deprecated and will be removed in a future version. Please take steps to stop the use of 'mangle_dupe_cols'\n",
" return pd.read_csv(xopen(filepath_or_buffer, \"rb\", use_auth_token=use_auth_token), **kwargs)\n",
"/home/raschka/miniforge3/envs/dl-fundamentals/lib/python3.9/site-packages/pandas/io/common.py:122: ResourceWarning: unclosed file <_io.BufferedReader name='/home/raschka/scratch/deeplearning-models/pytorch_ipynb/transformer/validation.csv'>\n",
" self.handle.detach()\n",
"ResourceWarning: Enable tracemalloc to get the object allocation traceback\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"0 tables [00:00, ? tables/s]"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"/home/raschka/miniforge3/envs/dl-fundamentals/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py:714: FutureWarning: the 'mangle_dupe_cols' keyword is deprecated and will be removed in a future version. Please take steps to stop the use of 'mangle_dupe_cols'\n",
" return pd.read_csv(xopen(filepath_or_buffer, \"rb\", use_auth_token=use_auth_token), **kwargs)\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Dataset csv downloaded and prepared to /home/raschka/.cache/huggingface/datasets/csv/default-3ba780b1f6e4b45e/0.0.0/6b34fb8fcf56f7c8ba51dc895bfa2bfbe43546f190a60fcf74bb5e8afdcc2317. Subsequent calls will reuse this data.\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"/home/raschka/miniforge3/envs/dl-fundamentals/lib/python3.9/site-packages/pandas/io/common.py:122: ResourceWarning: unclosed file <_io.BufferedReader name='/home/raschka/scratch/deeplearning-models/pytorch_ipynb/transformer/test.csv'>\n",
" self.handle.detach()\n",
"ResourceWarning: Enable tracemalloc to get the object allocation traceback\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "225d62e325d54b6b9d2d3d7a0da23f31",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
" 0%| | 0/3 [00:00