Awesome RL-VLA for Robotic Manipulation 🤖
[Paper]
A curated list of papers and resources on Reinforcement Learning of Vision-Language-Action (RL-VLA) models for Robotic Manipulation. This repository provides a comprehensive overview of training paradigms, methodologies, and state-of-the-art approaches in RL-VLA research.
📢 Latest News
🔥 [November 2025] Our comprehensive survey paper "A Survey on Reinforcement Learning of Vision-Language-Action Models for Robotic Manipulation" is now available on TechRxiv! Stay tuned for future updates.
📖 Table of Contents
- Awesome RL-VLA for Robotic Manipulation 🤖
🔍 Overview
RL training is crucial for enabling VLAs to generalize out-of-distribution (OOD) from large-scale pre-trained data. Existing RL-VLA training paradigms can be categorized into three types based on how agents obtain and utilize feedback from the environment:
- Online RL-VLA: Direct interaction with the environment during training
- Offline RL-VLA: Learning from static datasets without further environmental interaction
- Test-time RL-VLA: Models adapt their behavior during deployment without altering parameters
🚀 Training Paradigms
Offline RL-VLA
Offline RL trains VLA models on pre-collected static datasets, enabling learning independently from environment interactions. This paradigm is suitable for high-risk or resource-constrained deployment scenarios.
Key Research Directions:
- Data Utilization: Effective utilization of static datasets for policy improvement
- Objective Modification: Customizing RL objectives for novel architectures and data augmentation
Online RL-VLA
Online RL-VLA enables interactive policy learning through continuous environment interaction, empowering pre-trained VLAs with adaptive closed-loop control capability for real-world OOD environments.
Key Research Directions:
- Policy Optimization: Direct policy improvement based on environmental rewards
- Sample Efficiency: Learning effective policies with limited interaction budget
- Active Exploration: Efficient exploration strategies for higher performance gains
- Training Stability: Ensuring consistent policy updates and convergence
- Infrastructure: Scalable frameworks for online RL-VLA training
Test-time RL-VLA
Test-time RL-VLA adapts behavior during deployment through lightweight updates, addressing the expensive cost of full model fine-tuning in real-world scenarios.
Key Adaptation Mechanisms:
- Value Guidance: Using pre-trained value functions to influence action selection
- Memory Buffer Guidance: Retrieving relevant historical experiences during inference
- Planning-guided Adaptation: Explicit reasoning over future action sequences
📚 Paper Collection
Legend
- Action: AR (Autoregressive), Diffusion, Flow (Flow-matching)
- Reward: D (Dense Reward), S (Sparse Reward)
- Model Type: MB (Model-based), MF (Model-free)
- Environment: Sim. (Simulation), Real (Real-world)
- Task: MT (Multi-task), ST (Single-task)
Offline RL-VLA
| Method | Date | Publication | Sim. | Real | Base VLA Model | Action | Reward | Algorithm | Type | Project |
|---|---|---|---|---|---|---|---|---|---|---|
| Q-Transformer | 2023.10 | CoRL23🔗 | ✓ | ✗ | Transformer | AR | S | CQL | MF | 🔗 |
| PAC | 2024.02 | ICML24🔗 | ✓ | ✓ | Perceiver-Actor-Critic | AR | S | AC | MF | 🔗 |
| GeRM(Quadruped Robot) | 2024.03 | IROS24🔗 | ✓ | ✗ | Transformer-MoE | AR | S | CQL | MF | 🔗 |
| MoRE(Quadruped Robot) | 2025.03 | ICRA25🔗 | ✗ | ✓ | MLLM-MoE | AR | S | CQL | MF | - |
| ReinboT | 2025.05 | ICML25🔗 | ✓ | ✓ | ReinboT | AR | D | DT + RTG | MF | 🔗 |
| CO-RFT | 2025.08 | - | ✗ | ✓ | RoboVLMs | AR | D | Cal-QL + TD3 | MF | - |
| ARFM | 2025.09 | AAAI26🔗 | ✓ | ✓ | π₀ | Flow | D | ARFM | MF | - |
| $π^*_{0.6}$ | 2025.11 | - | ✗ | ✓ | $π_{0.6}$ | Flow | D | RECAP | MF | 🔗 |
| NORA-1.5 | 2025.11 | - | ✓ | ✓ | NORA-1.5 | AR / Flow | D | DPO | MB | 🔗 |
| GigaBrain-0.5M* | 2026.2 | - | ✗ | ✓ | GigaBrain-0.5 | Flow | D | RAMP | MB | 🔗 |
| ARM | 2026.4 | - | ✗ | ✓ | GR00T N1.5 | Flow | D | AW-BC | MF | 🔗 |
Online RL-VLA
| Method | Date | Publication | Sim. | Real | Base VLA Model | Action | Reward | Algorithm | Type | Project |
|---|---|---|---|---|---|---|---|---|---|---|
| FLaRe | 2024.09 | ICRA25🔗 | ✓ (ST) | ✓ (ST) | SPOC | AR | S | PPO | MF | 🔗 |
| PA-RL | 2024.12 | ICLR25 Workshop🔗 | ✓ (ST) | ✓ (ST) | OpenVLA | AR | S | PA-RL | MF | 🔗 |
| RLDG | 2024.12 | RSS25🔗 | ✗ | ✓ (ST) | OpenVLA / Octo | AR / Diffusion | S | RLPD | MF | 🔗 |
| iRe-VLA | 2025.01 | ICRA25🔗 | ✓ (MT) | ✓ (MT) | iRe-VLA | AR | S | SACfD + SFT | MF | - |
| GRAPE | 2025.02 | ICRA25 Poster🔗 | ✓ (MT) | ✓ (MT) | OpenVLA | AR | D | TPO | MF | 🔗 |
| SafeVLA | 2025.03 | NeurIPS25 Poster🔗 | ✓ (ST) | ✗ | SPOC | AR | S | PPO | MF | 🔗 |
| RIPT-VLA | 2025.05 | - | ✓ (MT) | ✗ | QueST / OpenVLA-OFT | AR | S | LOOP | MF | 🔗 |
| VLA-RL | 2025.05 | - | ✓ (MT) | ✗ | OpenVLA | AR | D | PPO | MF | 🔗 |
| RLVLA | 2025.05 | NeurIPS25 Poster🔗 | ✓ (MT) | ✗ | OpenVLA | AR | S | PPO / GRPO / DPO | MF | 🔗 |
| RFTF | 2025.05 | - | ✓ (MT) | ✗ | GR-MG, Seer | AR | D | PPO | MF | - |
| TGRPO | 2025.06 | - | ✓ (ST) | ✗ | OpenVLA | AR | D | GRPO | MF | - |
| RLRC | 2025.06 | - | ✓ (MT) | ✗ | OpenVLA | AR | S | PPO | MF | 🔗 |
| ThinkAct | 2025.07 | NeurIPS25 Poster🔗 | ✓ (MT) | ✗ | MLLM + DiT | AR / Diffusion | D | GRPO (System 2) | MF | 🔗 |
| SimpleVLA-RL | 2025.09 | ICLR26 Poster🔗 | ✓ (MT) | ✓ (ST) | OpenVLA-OFT | AR | S | GRPO | MF | 🔗 |
| Dual-Actor FT | 2025.09 | IROS25 Workshop Extended Abstract🔗 | ✓ (MT) | ✓ (MT) | Octo / SmolVLA | Diffusion | S | QL + BC | MF | 🔗 |
| Generalist | 2025.09 | NeurIPS25 Poster🔗 | ✓ (MT) | ✓ (MT) | PaLI 3B | AR | D | REINFORCE | MF | 🔗 |
| VLAC | 2025.09 | - | ✗ | ✓ (MT) | VLAC | AR | D | PPO | MF | 🔗 |
| Robo-Dopamine | 2025.12 | CVPR26🔗 | ✓ (MT) | ✓ (MT) | Pi0.5 | Flow | D | PPO | MF | 🔗 |
| AC PPO | 2025.09 | - | ✓ (ST) | ✗ | Octo-small | AR | S | PPO+BC | MF | - |
| VLA-RFT | 2025.10 | - | ✓ (MT) | ✗ | VLA-Adapter | Flow | D | GRPO | MB | 🔗 |
| RLinf-VLA | 2025.10 | - | ✓ (MT) | ✓ (MT) | OpenVLA / OpenVLA-OFT | AR | S | PPO / GRPO | MF | 🔗 |
| FPO | 2025.10 | - | ✓ (MT) | ✗ | π₀ | Flow | S | FPO | MF | - |
| ReSA | 2025.10 | - | ✓ (MT) | ✗ | OpenVLA | AR | D | PPO + SFT | MF | - |
| π_RL | 2025.10 | - | ✓ (MT) | ✗ | π₀ / π₀.₅ | Flow | S | PPO / GRPO | MF | 🔗 |
| PLD | 2025.10 | ICLR26 Poster🔗 | ✓ (MT) | ✓ (MT) | OpenVLA / π₀ / Octo | AR / Flow | S | Cal-QL + SAC | MF | 🔗 |
| DeepThinkVLA | 2025.10 | - | ✓ (MT) | ✗ | π₀-Fast | AR | S | GRPO | MF | 🔗 |
| World-Env | 2025.11 | - | ✓ (ST) | ✓ (ST) | OpenVLA-OFT | AR | D | PPO | MB | 🔗 |
| RobustVLA | 2025.11 | - | ✓ (MT) | ✗ | OpenVLA-OFT | AR | D | PPO | MF | - |
| WMPO | 2025.11 | ICLR26 Poster🔗 | ✓ (MT) | ✓ (MT) | OpenVLA-OFT | AR | S | GRPO | MB | 🔗 |
| ProphRL | 2025.11 | - | ✓ (ST) | ✓ (ST) | VLA-Adapter / π0.5 / OpenVLA-OFT(flow action) | Flow | S | FA-GRPO | MB | 🔗 |
| EVOLVE-VLA | 2025.12 | - | ✓ (MT) | ✗ | OpenVLA-OFT | AR | D | GRPO | MB(VLAC) | 🔗 |
| SOP | 2026.1 | - | ✗ | ✓ (MT) | π0.5 | Flow | S | HG-DAgger / RECAP | MF | 🔗 |
| Green-VLA | 2026.1 | - | ✓ (MT) | ✓ (MT) | Green-VLA | Flow | S | IQL + actor-critic | MF | 🔗 |
| SA-VLA | 2026.1 | - | ✓ (MT) | ✗ | π0.5 | Flow | D | PPO | MF | 🔗 |
| World-Gymnast | 2026.2 | ICLR26 Workshop🔗 | ✓ (MT) | ✓ (MT) | OpenVLA-OFT | AR | S | GRPO | MB | 🔗 |
| RL-VLA3 | 2026.2 | ICLR26 Workshop🔗 | ✓ (MT) | ✗ | π0 / π0.5 / GR00T N1.5 / OpenVLA-OFT | Flow / AR | S | - | MF | — |
| World-VLA-Loop | 2026.2 | - | ✓ (ST) | ✓ (ST) | OpenVLA-OFT | AR | S | GRPO | MB | 🔗 |
| RISE | 2026.2 | - | ✗ | ✓ (ST) | π0.5 | Flow | D | RISE | MB | 🔗 |
| WoVR | 2026.2 | - | ✓ (MT) | ✓ (MT) | OpenVLA-OFT | AR | S | GRPO | MB | 🔗 |
| ALOE | 2026.2 | - | ✗ | ✓ (ST) | π₀.₅ | Flow | S | AWR(Advantage-Weighted Regression) | MF | 🔗 |
| TwinRL-VLA | 2026.2 | - | ✗ | ✓ (ST) | Octo | Diffusion | S | Actor-Critic | MF | — |
| RL-Co | 2026.3 | - | ✓ (ST) | ✓ (ST) | OpenVLA / π0.5 | AR / Flow | D | ReinFlow / GRPO | MF | — |
| π_StepNFT | 2026.3 | - | ✓ (MT) | ✗ | π₀ / π₀.₅ | Flow | S | NFT | MF | 🔗 |
| ROBOMETER | 2026.3 | - | ✗ | ✓ (MT) | π₀ | Flow | D | DSRL | MF | 🔗 |
| AtomVLA | 2026.3 | - | ✓ (MT) | ✓ (ST) | AtomVLA | Flow | D | GRPO | MB | — |
| NS-VLA | 2026.3 | - | ✓ (MT) | ✗ | NS-VLA | AR | D | GRPO | MF | 🔗 |
Offline + Online RL-VLA
| Method | Date | Publication | Sim. | Real | Base VLA Model | Action | Reward | Algorithm | Type | Project |
|---|---|---|---|---|---|---|---|---|---|---|
| ConRFT | 2025.4 | RSS26🔗 | ✗ | ✓ | Octo-small | Diffusion | S | Cal-QL + BC | MF | 🔗 |
| DiffusionRL-VLA | 2025.9 | - | ✓ | ✗ | π₀ | Flow | S | PPO(DP) + BC(VLA) | MF | - |
| SRPO | 2025.11 | - | ✓ | ✓ | OpenVLA* / π₀ / π₀-Fast | AR / Flow | D | SRPO | MF (MB-Reward but MF-RL) | 🔗 |
| DLR | 2025.11 | - | ✓ | ✗ | π₀ / OpenVLA | Flow / AR | S | PPO(MLP) + SFT(VLA) | MF | - |
| GR-RL | 2025.12 | - | ✗ | ✓ | GR-3 | Flow | S | TD3 / DSRL | MF | 🔗 |
| STARE-VLA | 2025.12 | - | ✓ | ✗ | OpenVLA / π₀.₅ | AR / Flow | D | PPO / TPO / SFT | MF | 🔗 |
| IG-RFT | 2026.2 | - | ✗ | ✓ | π₀.₅ | Flow | D | IG-AWR | MF | — |
Test-time RL-VLA
| Method | Date | Publication | Sim. | Real | Base VLA Model | Action | Reward | Algorithm | Type | Project |
|---|---|---|---|---|---|---|---|---|---|---|
| V-GPS | 2024.10 | CoRL25🔗 | ✓(MT) | ✓(MT) | Octo / RT-1 / OpenVLA | AR / Diffusion | D | Cal-QL | MF | 🔗 |
| Hume | 2025.5 | - | ✓(MT) | ✓(MT) | Hume | Flow | S | Value Guidance | MF | 🔗 |
| DSRL | 2025.6 | CoRL25🔗 | ✓(MT) | ✓(MT) | DP / π₀ | Diffusion / Flow | S | Diffusion Steering | MF | 🔗 |
| VLA-Reasoner | 2025.9 | ICRA26🔗 | ✓(ST) | ✓(ST) | OpenVLA / SpatialVLA / π₀-Fast | AR / Diffusion | D | MCTS | MB | 🔗 |
| VLAPS | 2025.11 | CoRL25 Workshop🔗 | ✓(ST) | ✗ | Octo | Diffusion | S | MCTS | MB | 🔗 |
| VLA-Pilot | 2025.11 | - | ✗ | ✓(ST) | DiVLA / RDT | AR / Diffusion | D | Value GuidanceT | MB(MLLM) | 🔗 |
| TACO | 2025.12 | - | ✓ | ✓(ST) | π₀ / OpenVLA et al. | Flow | S | CNF estimation | MF | 🔗 |
| TT-VLA | 2026.1 | - | ✓(ST) | ✓(ST) | Nora / OpenVLA / TraceVLA | AR | D | PPO (Value-free) | MF | - |
| VLS | 2026.2 | - | ✓(MT) | ✓(MT) | OpenVLA / π₀ / π₀.₅ | Flow | D | gradient-based steer | MB(VLM) | 🔗 |
Note: The 🔗 symbol in the Project column indicates papers with available project pages, GitHub repositories, or demo websites.
🔗 Useful Resources
🎯 RL-VLA Action Optimization
Different VLA architectures require distinct RL optimization strategies based on their action generation mechanisms:
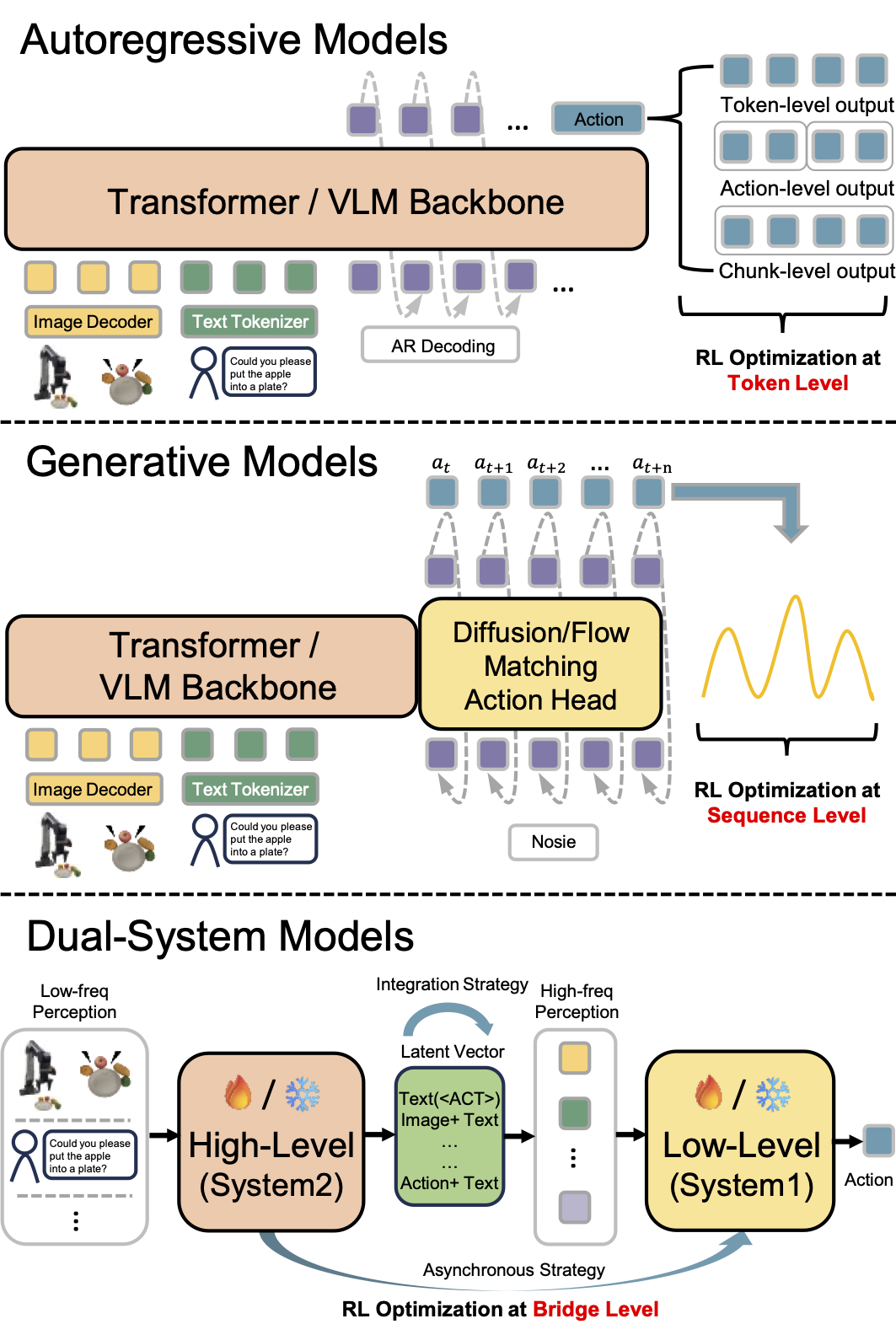
|
|
Base VLA Models
- GR00T-N1 - NVIDIA series
- π0 - PI series
- OpenVLA - Open-source VLA model
- Octo - Generalist robot policy
- RT-1 - Robotics Transformer
Datasets & Benchmarks
- Open X-Embodiment - Large-scale robotic datasets
- LIBERO - Benchmark for lifelong robot learning
- SimplerEnv - Benchmark for real-sim robot learning
- RoboTwin - Benchmark for bimanual robot learning
- DeepPHY - Benchmark for physical reasoning
Frameworks & Tools
- RLinf - Infrastructure for online RL fine-tuning of VLAs
- RLinfv0.2 - Infrastructure for real world RL
🤝 Contributing
We welcome contributions to this awesome list! Please feel free to:
- Add new papers: Submit a PR with new RL-VLA papers following the existing format
- Update information: Correct any errors or update paper information
- Suggest improvements: Propose better organization or additional sections
Contribution Guidelines
- Ensure papers are relevant to RL-VLA research
- Include paper links, project pages (if available), and key details
- Follow the existing table format for consistency
- Add a brief description for new paradigms or significant methodological contributions
📄 Citation
If you find this repository useful, please consider citing:
@article{pine2025rlvla, title={A Survey on Reinforcement Learning of Vision-Language-Action Models for Robotic Manipulation}, author={Haoyuan Deng, Zhenyu Wu, Haichao Liu, Wenkai Guo, Yuquan Xue, Ziyu Shan, Chuanrui Zhang, Bofang Jia, Yuan Ling, Guanxing Lu, and Ziwei Wang}, journal={TechRxiv}, year={2025}, doi={10.36227/techrxiv.176531955.54563920/v1}, note={Preprint} }
⭐ Star History
Star this repository if you find it helpful!