Star 历史趋势
数据来源: GitHub API · 生成自 Stargazers.cn
README.md
Awesome-Self-Evolving-Agents
![]()
![]()

![]()
🤖 We're still cooking — Stay tuned! 🤖
⭐ Give us a star if you like it! ⭐
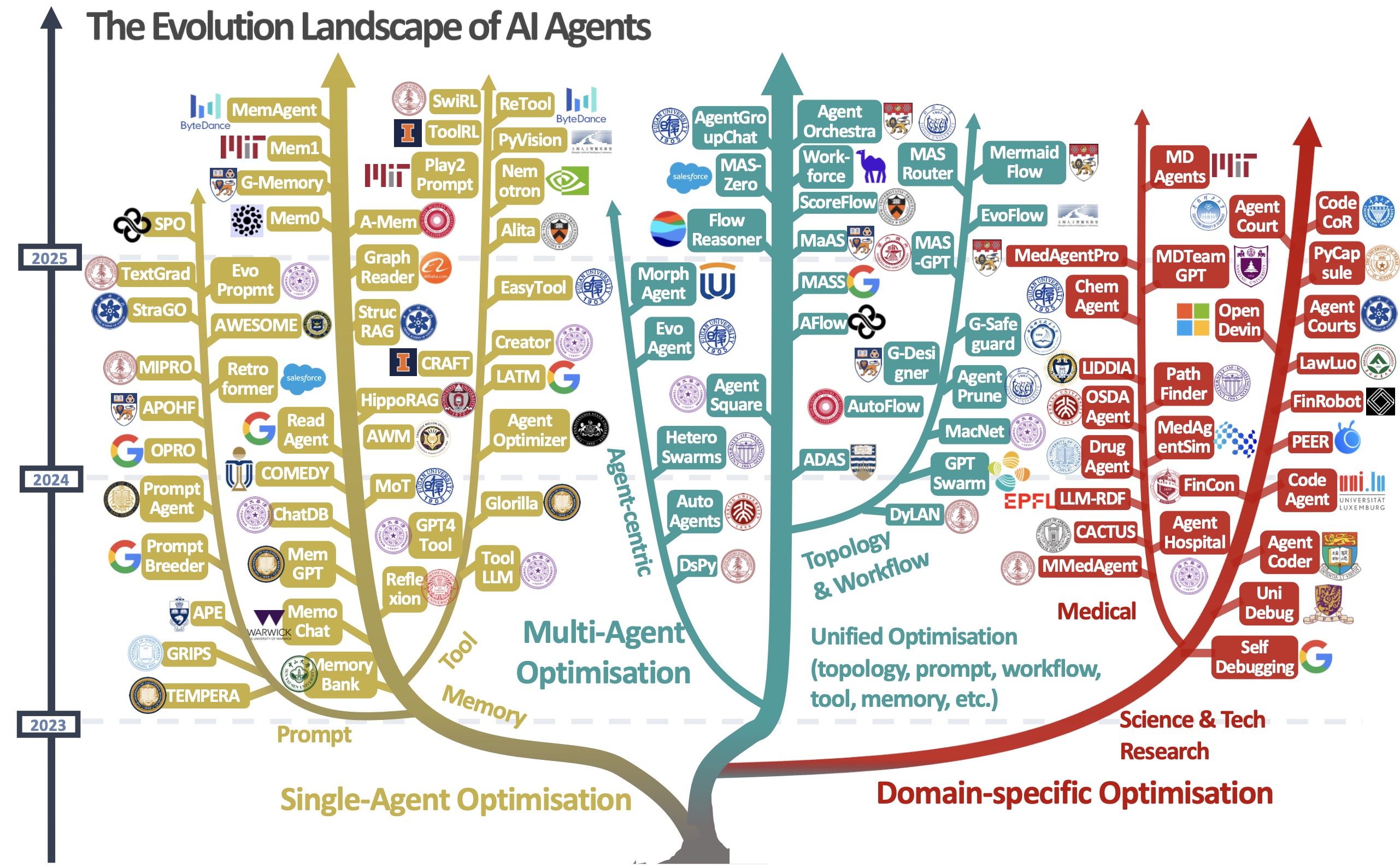
Figure: A visual taxonomy of AI agent evolution and optimisation techniques, categorised into three major directions: single-agent optimisation, multi-agent optimisation, and domain-specific optimisation. The tree structure illustrates the development of these approaches from 2023 to 2025, including representative methods within each branch.
AI Agents Development Path
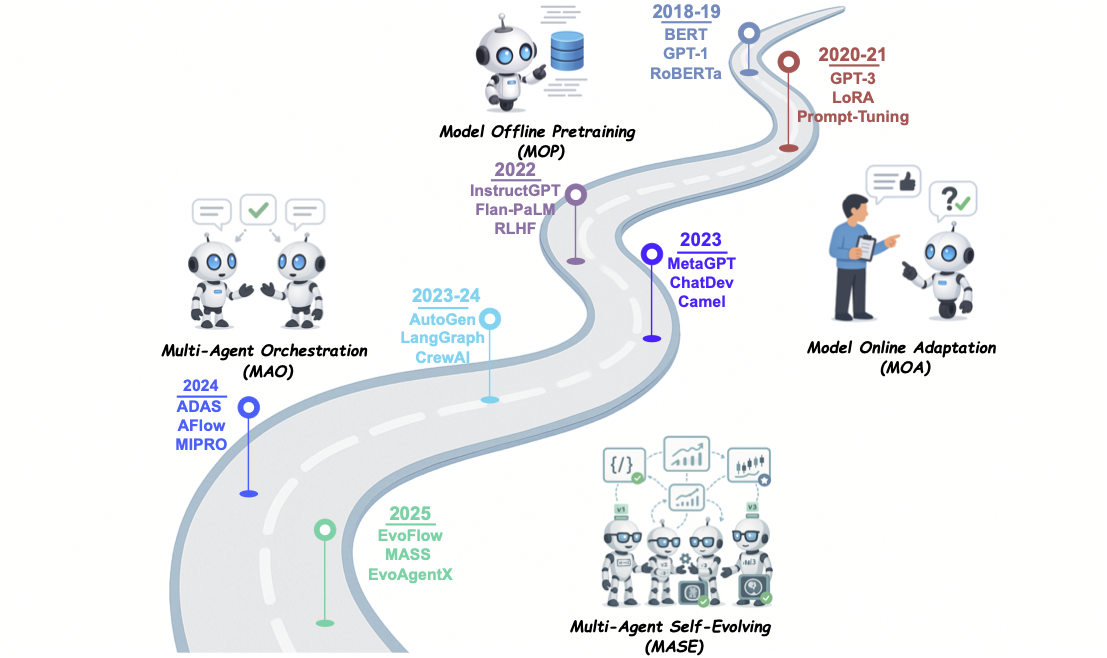
Conceptual Framework of the Self-Evolving AI Agents
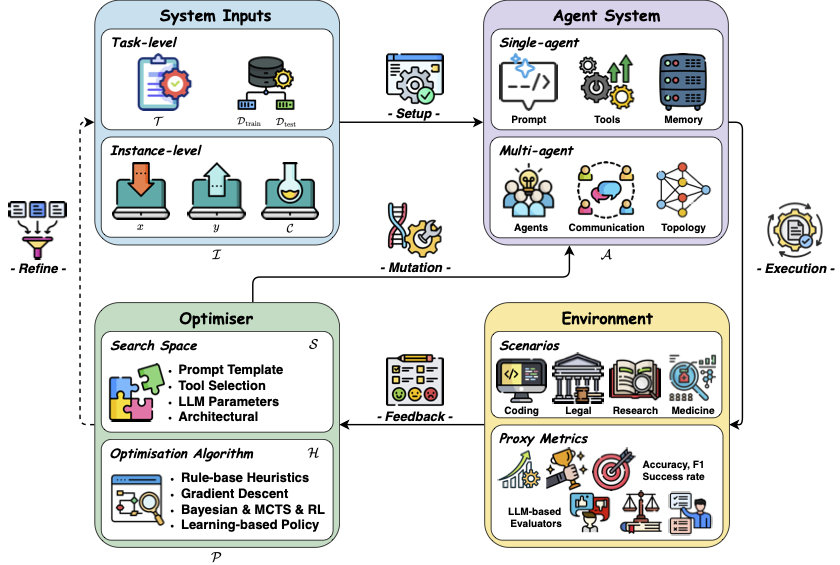
Open-Source Framework
- (EMNLP'25 Demo) EvoAgentX: An Automated Framework for Evolving Agentic Workflows [💻 Code] [📝 Paper]
- (Arxiv'25) MASLab: A Unified and Comprehensive Codebase for LLM-based Multi-Agent Systems [📝 Paper] [💻 Code]
1. Single-Agent Optimisation
1.1 🤖 LLM Behaviour Optimisation
1.1.1 📌 Training-Based Behaviour Optimisation
(1) 🔧 Supervised Fine-Tuning Approaches
- (ICLR'24) ToRA: A tool-integrated reasoning agent for mathematical problem solving [📝 Paper] [💻 Code]
- (NeurIPS'22) STaR : Bootstrapping reasoning with reasoning [📝 Paper] [💻 Code]
- (Arxiv'24) NExT: Teaching large language models to reason about code execution [📝 Paper]
- (EMNLP'24) MuMath-Code: Combining Tool-Use Large Language Models with Multi-perspective Data Augmentation for Mathematical Reasoning [📝 Paper]
- (ICML'25) MAS-GPT: Training LLMs to build LLM-based multi-agent systems [📝 Paper] [💻 Code]
(2) 🔧 Reinforcement Learning Approaches
- (ICML'24) Self-Rewarding Language Models [📝 Paper] [💻 Code]
- (Arxiv'24) Tulu 3: Pushing Frontiers in Open Language Model Post-Training [📝 Paper] [💻 Code]
- (EMNLP'24) Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing [📝 Paper] [💻 Code]
- (Arxiv'24) Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents [📝 Paper]
- (Arxiv'24) DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data [📝 Paper]
- (ICML'25) Diving into Self-Evolving Training for Multimodal Reasoning [📝 Paper] [💻 Code]
- (Arxiv'25) Absolute Zero: Reinforced Self-play Reasoning with Zero Data [📝 Paper]
- (Arxiv'25) R-Zero: Self-Evolving Reasoning LLM from Zero Data [📝 Paper] [💻 Code]
- (Arxiv'25) SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning [📝 Paper] [💻 Code]
- (Arxiv'25) DistFlow: A Fully Distributed RL Framework for Scalable and Efficient LLM Post-Training [📝 Paper] [💻 Code]
- (Arxiv'25) Vision-Zero: Scalable VLM Self-Improvement via Strategic Gamified Self-Play [📝 Paper] [💻 Code]
- (Arxiv'25) Parallel-R1: Towards Parallel Thinking via Reinforcement Learning [📝 Paper] [💻 Code]
- (Arxiv'25) SSRL: Self-Search Reinforcement Learning [📝 Paper] [💻 Code]
- (Arxiv'25) SeRL: Self-Play Reinforcement Learning for Large Language Models with Limited Data [📝 Paper] [💻 Code]
1.1.2 📌 Test-Time Behaviour Optimisation
(1) 🔧 Feedback-Based Approaches
- (ICLR'23) CodeT: Code Generation with Generated Tests [📝 Paper] [💻 Code]
- (ICML'23) LEVER: Learning to Verify Language-to-Code Generation with Execution [📝 Paper] [💻 Code]
- (ESEC/FSE'23) Baldur: Whole-Proof Generation and Repair with Large Language Models [📝 Paper]
- (ACL'24) Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations [📝 Paper]
- (EMNLP'24) Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing [📝 Paper] [💻 Code]
- (Arxiv'24) Skywork-Reward: Bag of Tricks for Reward Modeling in LLMs [📝 Paper]
- (ICLR'25) Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning [📝 Paper]
- (Arxiv'25) Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy [📝 Paper] [💻 Code]
(2) 🔧 Search-Based Approaches
- (ICLR'23) Self-consistency improves chain of thought reasoning in language models [📝 Paper]
- (ACL'23) Solving Math Word Problems via Cooperative Reasoning induced Language Models [📝 Paper] [💻 Code]
- (NeurIPS'23) Tree of thoughts: Deliberate problem solving with large language models [📝 Paper] [💻 Code]
- (NeurIPS'24) Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models [📝 Paper] [💻 Code]
- (COLM'24) Deductive Beam Search: Decoding Deducible Rationale for Chain-of-Thought Reasoning [📝 Paper] [💻 Code]
- (AAAI'24) Graph of thoughts: Solving elaborate problems with large language models [📝 Paper] [💻 Code]
- (ICML'25) Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning [📝 Paper] [💻 Code]
(3)🔧 Reasoning-Based Approaches
- (EMNLP’25) START: Self‑taught Reasoner with Tools [📝 Paper]
- (ArXiv’25) CoRT: Code‑integrated Reasoning within Thinking [📝 Paper] [💻 Code]
1.2 💬 Prompt Optimisation
1.2.1 📌 Edit-Based Prompt Optimisation
- (EMNLP'22) GPS: Genetic Prompt Search for Efficient Few-shot Learning [📝 Paper] [💻 Code]
- (EACL'23) GrIPS: Gradient-free, Edit-based Instruction Search for Prompting Large Language Models [📝 Paper] [💻 Code]
- (ICLR'23) TEMPERA: Test-Time Prompting via Reinforcement Learning [📝 Paper] [💻 Code]
- (ACL'24) Plum: Prompt Learning using Metaheuristic [📝 Paper] [💻 Code]
1.2.2 📌 Evolutionary Prompt Optimisation
- (ICLR'24) EvoPrompt: Connecting LLMs with Evolutionary Algorithms Yields Powerful Prompt Optimizers [📝 Paper] [💻 Code]
- (ICML'24) Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution [📝 Paper]
- (Arxiv'25) GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning [📝 Paper]
1.2.3 📌 Generative Prompt Optimisation
- (ICLR'23) Large Language Models Are Human-Level Prompt Engineers [📝 Paper] [💻 Code]
- (ICLR'24) PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization [📝 Paper] [💻 Code]
- (ICLR'24) Large Language Models as Optimizers [📝 Paper] [💻 Code]
- (ICLR'24) Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization [📝 Paper] [💻 Code]
- (EMNLP'24) Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs [📝 Paper] [💻 Code]
- (Arxiv'24) Prompt Optimization with Human Feedback [📝 Paper] [💻 Code]
- (Arxiv'24) StraGo: Harnessing Strategic Guidance for Prompt Optimization [📝 Paper]
- (Arxiv'25) Self-Supervised Prompt Optimization [📝 Paper]
1.2.4 📌 Text Gradient-Based Prompt Optimisation
- (EMNLP'23) Automatic Prompt Optimization with "Gradient Descent" and Beam Search [📝 Paper] [💻 Code]
- (Arxiv'24) TextGrad: Automatic "Differentiation" via Text [📝 Paper] [💻 Code]
- (Arxiv'24) How to Correctly do Semantic Backpropagation on Language-based Agentic Systems [📝 Paper] [💻 Code]
- (Arxiv'24) GRAD-SUM: Leveraging Gradient Summarization for Optimal Prompt Engineering [📝 Paper]
- (AAAI'25) Unleashing the Potential of Large Language Models as Prompt Optimizers: Analogical Analysis with Gradient-based Model Optimizers [📝 Paper] [💻 Code]
- (ICML'25) REVOLVE: Optimizing AI Systems by Tracking Response Evolution in Textual Optimization [📝 Paper] [💻 Code]
- (Arxiv'25) PersonaAgent: When Large Language Model Agents Meet Personalization at Test Time [📝 Paper]
1.3 🧠 Memory Optimization
- (ICML'24) A Human-Inspired Reading Agent with Gist Memory of Very Long Contexts [📝 Paper]
- (ICML'24) Agent Workflow Memory [📝 Paper]
- (AAAI'24) MemoryBank: Enhancing Large Language Models with Long-Term Memory [📝 Paper]
- (EMNLP'24) GraphReader: Building graph-based agent to enhance long-context [📝 Paper]
- (Arxiv'24) "My agent understands me better": Integrating Dynamic Human-like Memory Recall and Consolidation in LLM-Based Agents [📝 Paper]
- (ICLR'25) Compress to Impress: Unleashing the Potential of Compressive Memory in Real-World Long-Term Conversations [📝 Paper]
- (ICLR'25) Boosting knowledge intensive reasoning of llms via inference-time hybrid information [📝 Paper] [💻 Code]
- (ACL'25) Improving factuality with explicit working memory [📝 Paper]
- (Arxiv'25) A-MEM: Agentic Memory for LLM Agents [📝 Paper]
- (Arxiv'25) Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory [📝 Paper]
- (Arxiv'25) Memento: Fine‑tuning LLM Agents without Fine‑tuning LLMs [📝 Paper] [💻 Code]
- (Arxiv'25) Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning [📝 Paper]
- (Arxiv'25) Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory [📝 Paper] [💻 Code]
- (Arxiv'25) PersonaAgent: When Large Language Model Agents Meet Personalization at Test Time [📝 Paper]
1.4 🧰 Tool Optimization
1.4.1 📌 Training-Based Tool Optimisation
(1) Supervised Fine-Tuning for Tool Optimisation
- (NeurIPS'23) GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction [📝 Paper] [💻 Code]
- (ICLR'24) ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs [📝 Paper] [💻 Code]
- (ACL'24) LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error [📝 Paper] [💻 Code]
- (AAAI'24) Confucius: Iterative tool learning from introspection feedback by easy-to-difficult curriculum [📝 Paper] [💻 Code]
- (ICLR'25) Learning Evolving Tools for Large Language Models [📝 Paper] [💻 Code]
- (ICLR'25) Facilitating Multi-turn Function Calling for LLMs via Compositional Instruction Tuning [📝 Paper] [💻 Code]
- (ICLR'25) Multi-modal Agent Tuning: Building a VLM-Driven Agent for Efficient Tool Usage [📝 Paper] [💻 Code]
- (Arxiv'25) Magnet: Multi-turn Tool-use Data Synthesis and Distillation via Graph Translation [📝 Paper]
- (ICML'25) Adapting While Learning: Grounding LLMs for Scientific Problems with Intelligent Tool Usage Adaptation [📝 Paper] [💻 Code]
(2) Reinforcement Learning for Tool Optimisation
- (Arxiv'25) ReTool: Reinforcement Learning for Strategic Tool Use in LLMs [📝 Paper] [💻 Code]
- (Arxiv'25) ToolRL: Reward is All Tool Learning Needs [📝 Paper] [💻 Code]
- (Arxiv'25) Nemotron-Research-Tool-N1: Exploring Tool-Using Language Models with Reinforced Reasoning [📝 Paper] [💻 Code]
- (Arxiv'25) Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use [📝 Paper]
- (Arxiv'25) Iterative Tool Usage Exploration for Multimodal Agents via Step-wise Preference Tuning [📝 Paper] [💻 Code]
- (Arxiv'25) Tool-Star: Empowering LLM-Brained Multi-Tool Reasoner via Reinforcement Learning [📝 Paper] [💻 Code]
- (Arxiv'25) Agentic Reinforced Policy Optimization [📝 Paper] [💻 Code]
- (Arxiv'25) AutoTIR: Autonomous Tools Integrated Reasoning via Reinforcement Learning [📝 Paper] [💻 Code]
1.4.2 📌 Inference-Time Tool Optimisation
(1) Prompt-Based Optimisation
- (NAACL'25) EASYTOOL: Enhancing LLM-based Agents with Concise Tool Instruction [📝 Paper] [💻 Code]
- (ICLR'25) From Exploration to Mastery: Enabling LLMs to Master Tools via Self-Driven Interactions [📝 Paper] [💻 Code]
- (ACL'25) Zero-shot Tool Instruction Optimization for LLM Agents via Tool Play [📝 Paper] [💻 Code]
(2) Reasoning-Based Optimisation
- (ICLR'24) ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs [📝 Paper] [💻 Code]
- (ICLR'24) ToolChain*: Efficient Action Space Navigation in Large Language Models with A* Search [📝 Paper]
- (ICLR'25) Tool-Planner: Task Planning with Clusters across Multiple Tools [📝 Paper] [💻 Code]
- (Arxiv'25) MCP-Zero: Active Tool Discovery for Autonomous LLM Agents [📝 Paper][💻 Code]
1.4.3 📌 Tool Functionality Optimisation
- (EMNLP'23) CREATOR : Tool creation for disentangling abstract and concrete reasoning of large language model [📝 Paper] [💻 Code]
- (ICML'24) Offline Training of Language Model Agents with Functions as Learnable Weights [📝 Paper]
- (CVPR'24) CLOVA: A Closed-Loop Visual Assistant with Tool Usage and Update [📝 Paper] [💻 Code]
- (Arxiv'25) Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution [📝 Paper] [💻 Code]
1.5 🧰 Unified Optimization
- (Arxiv'25) Building Self-Evolving Agents via Experience-Driven Lifelong Learning: A Framework and Benchmark [📝 Paper] [💻 Code]
- (Arxiv'25) EvoAgent: Self-evolving Agent with Continual World Model for Long-Horizon Tasks [📝 Paper]
2. Multi-Agent Optimisation
2.1 ⚙️ Automatic Multi-Agent Construction
- (ICML'25) MetaAgent: Automatically Constructing Multi-Agent Systems Based on Finite State Machines [📝 Paper] [💻 Code]
2.2 🚀 MAS Optimisation
- (Arxiv' 25) R&D-Agent: Automating Data-Driven AI Solution Building Through LLM-Powered Automated Research, Development, and Evolution [📝 Paper] [💻 Code]
- (ICML'25) Multi-Agent Architecture Search via Agentic Supernet [📝 Paper] [💻Code]
- (ICML'25) MA-LoT: Multi-Agent Lean-based Long Chain-of-Thought Reasoning enhances Formal Theorem Proving [📝 Paper]
- (ICLR'25) AFlow: Automating Agentic Workflow Generation [📝 Paper] [💻 Code]
- (ICLR'25) WorkflowLLM: Enhancing Workflow Orchestration Capability of Large Language Models [📝 Paper]
- (ICLR'25) Flow: Modularized Agentic Workflow Automation [📝 Paper]
- (ICLR'25) Automated Design of Agentic Systems [📝 Paper] [💻 Code]
- (Arxiv'25) FlowReasoner: Reinforcing Query-Level Meta-Agents [📝 Paper]
- (Arxiv'25) AgentNet: Decentralized Evolutionary Coordination for LLM-Based Multi-Agent Systems [📝 Paper]
- (Arxiv'25) MAS-GPT: Training LLMs to Build LLM-Based Multi-Agent Systems [📝 Paper]
- (Arxiv'25) FlowAgent: Achieving Compliance and Flexibility for Workflow Agents [📝 Paper]
- (Arxiv'25) ScoreFlow: Mastering LLM Agent Workflows via Score-Based Preference Optimization [📝 Paper] [💻 Code]
- (Arxiv'25) Multi-Agent Design: Optimizing Agents with Better Prompts and Topologies [📝 Paper]
- (Arxiv'25) MAS-ZERO: Designing Multi-Agent Systems with Zero Supervision [📝 Paper]
- (Arxiv'25) MermaidFlow: Redefining Agentic Workflow Generation via Safety-Constrained Evolutionary Programming [📝 Paper]
- (ICML'24) GPTSwarm: Language Agents as Optimizable Graphs [📝 Paper] [Code]
- (ICLR'24) DSPy: Compiling Declarative Language Model Calls into State-of-the-Art Pipelines [📝 Paper] [💻 Code]
- (ICLR'24) AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors [📝 Paper] [💻 Code]
- (ICLR'24) MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework [📝 Paper] [💻 Code]
- (COLM'24) A Dynamic LLM-Powered Agent Network for Task-Oriented Agent Collaboration [📝 Paper]
- (COLM'24) AutoGen: Enabling next-Gen LLM Applications via Multi-Agent Conversations [📝 Paper] [💻 Code]
- (Arxiv'24) G-Designer: Architecting Multi-Agent Communication Topologies via Graph Neural Networks [📝 Paper]
- (Arxiv'24) AutoFlow: Automated Workflow Generation for Large Language Model Agents [📝 Paper] [💻 Code]
- (Arxiv'24) Symbolic Learning Enables Self-Evolving Agents [📝 Paper] [💻 Code]
- (Arxiv'24) Adaptive In-Conversation Team Building for Language Model Agents [📝 Paper]
- (ICLR'25) Self-Evolving Multi-Agent Collaboration Networks for Software Development [📝 Paper] [💻 Code]
- (Arxiv'25) Chain‑of‑Agents: End‑to‑End Agent Foundation Models via Multi‑Agent Distillation and Agentic RL [📝 Paper] [💻 Code]
- (Arxiv’25) Agent KB: Leveraging Cross‑Domain Experience for Agentic Problem Solving [📝 Paper] [💻 Code]
3. Domain-Specific Optimisation
3.1 🧬 Biomedicine
3.1.1 📌 Medical Diagnosis
- (EMNLP'24) MMedAgent: Learning to Use Medical Tools with Multi-modal Agent [📝 Paper] [💻 Code]
- (NeurIPS'24) MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making [📝 Paper] [💻 Code]
- (Arxiv'25) HealthFlow: A Self-Evolving AI Agent with Meta Planning for Autonomous Healthcare Research [📝 Paper][💻 Code]
- (Arxiv'25) STELLA: Self-Evolving LLM Agent for Biomedical Research [📝 Paper][💻 Code]
- (MICCAI'25) MedAgentSim: Self-Evolving Multi-Agent Simulations for Realistic Clinical Interactions [📝 Paper] [💻 Code]
- (Arxiv'25) PathFinder: A Multi-Modal Multi-Agent System
for Medical Diagnostic Decision-Making Applied to Histopathology
[📝 Paper] - (Arxiv'25) MDTeamGPT: A Self-Evolving LLM-based Multi-Agent Framework for Multi-Disciplinary Team Medical Consultation
[📝 Paper] [💻 Code] - (Arxiv'25) MedAgent-Pro: Towards Evidence-based Multi-modal
Medical Diagnosis via Reasoning Agentic Workflow
[📝 Paper] [💻 Code] - (Arxiv'25) Structural Entropy Guided Agent for Detecting and Repairing Knowledge Deficiencies in LLMs [📝 Paper] [💻 Code]
3.1.2 📌 Molecular Discovery
- (ACS omega'24) CACTUS: Chemistry Agent Connecting Tool-Usage to Science [📝 Paper] [💻 Code]
- (NMI'24) ChemCrow: Augmenting large language models with chemistry tools [📝 Paper] [💻 Code]
- (ICLR'25) ChemAgent: Self-updating Library in Large Language Models Improves Chemical Reasoning[📝 Paper] [💻 Code]
- (ICLR'25) OSDA Agent: Leveraging Large Language Models for De Novo Design of Organic Structure Directing Agents [📝 Paper]
- (Arxiv'25) DrugAgent: Automating AI-aided Drug Discovery Programming through LLM Multi-Agent Collaboration [📝 Paper]
- (Arxiv'25) LIDDIA: Language-based Intelligent Drug Discovery Agent [📝 Paper]
- (Arxiv'25) GenoMAS: A Multi-Agent Framework for Scientific Discovery via Code-Driven Gene Expression Analysis
[📝 Paper] [💻 Code]
3.2 💻 Programming
3.2.1 📌 Code Refinement
- (Arxiv'23) AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation [📝 Paper] [💻 Code]
- (Arxiv'23) Self-Refine: Iterative Refinement with Self-Feedback [📝 Paper] [💻 Code]
- (EMNLP'24) CodeAgent: Autonomous Communicative Agents for Code Review [📝 Paper] [💻 Code]
- (ICLR'25) OpenHands: An Open Platform for AI Software Developers as Generalist Agents [📝 Paper] [💻 Code]
- (Arxiv'25) CodeCoR: An LLM-Based Self-Reflective Multi-Agent Framework for Code Generation [📝 Paper]
- (Arxiv’25) AlphaEvolve: A coding agent for scientific and algorithmic discovery [📝 Paper]
- (Arxiv'25) Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents [📝 Paper] [💻 Code]
- (Software'25) OpenEvolve: an open-source evolutionary coding agent [📝 Instructions] [💻 Code]
- (ICLR'25) Self-Evolving Multi-Agent Collaboration Networks for Software Development [📝 Paper] [💻 Code]
3.2.2 📌 Code Debugging
- (ACL'23) Self-Edit: Fault-Aware Code Editor for Code Generation [📝 Paper]
- (ICLR'24) Teaching Large Language Models to Self-Debug [📝 Paper]
- (ICA'24) RGD: Multi-LLM based agent debugger via refinement and generation guidance. [📝 Paper]
- (Arxiv'25) Large Language Model Guided Self-Debugging Code Generation [📝 Paper]
3.3 Scientific Research
- (Arxiv’25) PiFlow: Principle‑aware Scientific Discovery with Multi‑Agent Collaboration [📝 Paper] [💻 Code]
3.4 💰📚 Financial and Legal Research
3.4.1 📌 Financial Decision-Making
- (Arxiv'25) R&D-Agent-Quant: A Multi-Agent Framework for Data-Centric Factors and Model Joint Optimization [📝 Paper] [💻 Code]
- (Arxiv'24) FinRobot: an open-source ai agent platform for financial applications using large language models [📝 Paper] [💻 Code]
- (Arxiv'24) PEER: Expertizing domain-specific tasks with a multi-agent framework and tuning methods [📝 Paper] [💻 Code]
- (NeurIPS'25) Fincon: A synthesized llm multi-agent system with conceptual verbal reinforcement for enhanced financial decision making [📝 Paper] [💻 Code]
3.4.2 📌 Legal Reasoning
- (Arxiv'24) LawLuo: A Multi-Agent Collaborative Framework for Multi-Round Chinese Legal Consultation [📝 Paper]
- (ICIC'24) Legalgpt: Legal chain of thought for the legal large language model multi-agent framework [📝 Paper]
- (Arxiv'24) LawGPT: A Chinese Legal Knowledge-Enhanced Large Language Model [📝 Paper] [💻 Code]
- (ACL Findings'25) AgentCourt: Simulating Court with Adversarial Evolvable Lawyer Agents [📝 Paper] [💻 Code]
3.5 🧩 Other Domain-Specific Optimisation
- (Arxiv'25) Agents of Change: Self-Evolving LLM Agents for Strategic Planning [📝 Paper]
- (Arxiv'25) EarthLink: A Self-Evolving AI Agent for Climate Science [📝 Paper] [🖥️ System]
- (Arxiv'25) SEAgent: Self-Evolving Computer Use Agent with Autonomous Learning from Experience [📝 Paper][💻 Code]
4. Evaluation
4.1 📈 Benchmark-Based Evaluation
- (NeurIPS'23) OpenAGI: When LLM Meets Domain Experts [📝 Paper] [💻 Code]
- (Arxiv'25) Building Self-Evolving Agents via Experience-Driven Lifelong Learning: A Framework and Benchmark [📝 Paper]
- (Arxiv'25) MLGym: A New Framework and Benchmark for Advancing AI Research Agents [📝 Paper] [💻 Code]
- (Arxiv'25) X-MAS: Towards Building Multi-Agent Systems with Heterogeneous LLMs [📝 Paper] [💻 Code]
4.1.1 📌 Tool and API-Driven Agents
- (Arxiv'23) On the Tool Manipulation Capability of Open-source Large Language Models [📝 Paper] [💻 Code]
- (EMNLP'23) API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs [📝 Paper] [💻 Code]
- (NeurIPS'23) ToolQA: A Dataset for LLM Question Answering with External Tools [📝 Paper] [💻 Code]
- (ICLR'24) MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use [📝 Paper] [💻 Code]
- (Arxiv'25) Enhancing Open-Domain Task-Solving Capability of LLMs via Autonomous Tool Integration from GitHub [📝 Paper] [💻 Code]
- (Arxiv'25) LiveMCP-101: Stress Testing and Diagnosing MCP-enabled Agents on Challenging Queries [📝 Paper]
4.1.2 📌 Web Navigation and Browsing Agents
- (ICLR'24) WebArena: A Realistic Web Environment for Building Autonomous Agents [📝 Paper] [💻 Code]
- (Arxiv'25) BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents [📝 Paper] [💻 Code]
- (ACL'25) WebWalker: Benchmarking LLMs in Web Traversal [📝 Paper] [💻 Code]
4.1.3 📌 Coding Agents
- (ICLR'24) SWE-bench: Can Language Models Resolve Real-World GitHub Issues? [📝 Paper] [💻 Code]
- (ICLR'25) Self-Evolving Multi-Agent Collaboration Networks for Software Development [📝 Paper] [💻 Code]
4.1.4 Scientific Research Agents
4.1.4 📌 Multi-Agent Collaboration and Generalists
- (ICLR'23) GAIA: a benchmark for General AI Assistants [📝 Paper] [💻 Code]
- (ICLR'24) AgentBench: Evaluating LLMs as Agents [📝 Paper] [💻 Code]
- (Arxiv'25) MultiAgentBench: Evaluating the Collaboration and Competition of LLM agents [📝 Paper] [💻 Code]
- (Arxiv'25) Benchmarking LLMs' Swarm intelligence [📝 Paper] [💻 Code]
4.1.5 📌 GUI and Multimodal Environment Agents
- (ACL'24) Mobile-Bench: An Evaluation Benchmark for LLM-based Mobile Agents [📝 Paper] [💻 Code]
- (NeurIPS'24) OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments [📝 Paper] [💻 Code]
- (ICLR'25) AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents [📝 Paper] [💻 Code]
4.2 ⚖️ LLM-Based Evaluation
4.2.1 📌 LLM-as-a-Judge
- (Arxiv'24) Towards Better Human-Agent Alignment: Assessing Task Utility in LLM-Powered Applications [📝 Paper]
- (Arxiv'24) LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods [📝 Paper]
- (Arxiv'25) LiveIdeaBench: Evaluating LLMs’ Divergent Thinking for Scientific Idea Generation with Minimal Context [📝 Paper] [💻 Code]
- (ACL'25) Auto-Arena: Automating LLM Evaluations with Agent Peer Debate and Committee Voting [📝 Paper] [💻 Code]
- (Arxiv'25) MCTS-Judge: Test-Time Scaling in LLM-as-a-Judge for Code Correctness Evaluation [📝 Paper]
4.2.2 📌 Agent-as-a-Judge
4.3 🛡 Safety, Alignment, and Robustness for Lifelong / Self-Evolving Agents
- (Arxiv'24) AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents [📝 Paper ]
- (NeurIPS'24 – Datasets & Benchmarks) RedCode: Risky Code Execution and Generation [📝 Paper ]
- (Arxiv'24) MobileSafetyBench: Evaluating Safety of Autonomous Agents in Mobile Device Control [📝 Paper] [💻 Code]
- (Arxiv'23) Do the Rewards Justify the Means? Measuring Trade-Offs Between Rewards and Ethical Behavior in the MACHIAVELLI Benchmark [📝 Paper ]
- (Arxiv'24) R-Judge: Benchmarking Safety Risk Awareness for LLM Judges [📝 Paper] [💻 Code]
- (ACL'25) SafeLawBench: Towards Safe Alignment of Large Language Models [📝 Paper ]
- (Arxiv'25) Accuracy Paradox in Large Language Models: Regulating Hallucination Risks in Generative AI [📝 Paper ]
- (ICLR'25 Spotlight) AutoDAN-Turbo: A Lifelong Agent for Strategy Self-Exploration to Jailbreak LLMs [📝 Paper] [💻 Code]
- (ACL'25) AGrail: A Lifelong Agent Guardrail with Effective and Adaptive Safety Detection [📝 Paper] [💻 Code]
📚 Citation
If you find this survey useful in your research and applications, please cite using this BibTeX:
@article{fang2025comprehensive,
title={A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems},
author={Fang, Jinyuan and Peng, Yanwen and Zhang, Xi and Wang, Yingxu and Yi, Xinhao and Zhang, Guibin and Xu, Yi and Wu, Bin and Liu, Siwei and Li, Zihao and others},
journal={arXiv preprint arXiv:2508.07407},
year={2025}
}
☕ Acknowledgement
We would like to thank Shuyu Guo for his valuable contributions to the early-stage exploration and literature review on agent optimisation.
✉️ Contact Us
If you have any questions or suggestions, please feel free to contact us via:
Email: j.fang.2@research.gla.ac.uk and zaiqiao.meng@gmail.com
关于 About
[Survey] A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems
agentagentic-aiaillmsmulti-agent-systemsnatural-language-processingself-evolving
语言 Languages
提交活跃度 Commit Activity
代码提交热力图
过去 52 周的开发活跃度58
Total Commits峰值: 18次/周
LessMore