AI News Radar
24小时AI更新雷达|伯乐Skill
伯乐Skill(Scout Skill)帮你从一堆信源里选出千里马,并把分散消息合并成可追踪的AI故事线。


![]()
30秒选边上车
① 只想看AI日报 → 不用装任何东西,直接打开在线页面。
② 想让Agent替你读 → 装雷达Skill(ai-radar),零API、零Key、零服务器:
npx skills add LearnPrompt/ai-news-radar -s ai-radar -g装完对Agent说一句:今天AI圈有什么?
③ 想要一个完全属于自己的雷达 → fork本仓库,让内置的伯乐Skill帮你录入信源、部署GitHub Pages。信源你选,数据归你。
三层是一条路:看报 → 让Agent读报 → 自己办报。
这是什么
AI News Radar是一个自动更新的24小时AI更新雷达。它不只是把AI新闻抓回来,会先判断信息源质量,把同一个事件合并成故事线,最后用伯乐Skill精选、AI标签、源健康和AI占比帮你判断,
什么信息值得看,什么值得深挖,什么只是噪音。
普通用户直接打开网页,看最近24小时AI、模型、开发者工具和技术生态更新。开发者可以fork这个仓库,接入自己的OPML/RSS、公开feed、静态页面或AgentMail邮箱。Codex / Claude Code这类 Agent 可以使用项目内置的 伯乐Skill,继续帮你判断新的信息源、维护抓取逻辑、部署 GitHub Pages。
这个项目永远都不会是“又一个新闻网页”。
它的核心逻辑是伯乐Skill,帮你从一堆信源里选出千里马。哪些源值得长期追踪,哪些源适合做成RSS/OPML,哪些源只能接付费的API,哪些源看起来更新很多但实际上跟你长期关注的方面比方AI只占了里面的5%不到。
先判断清楚,再接入。
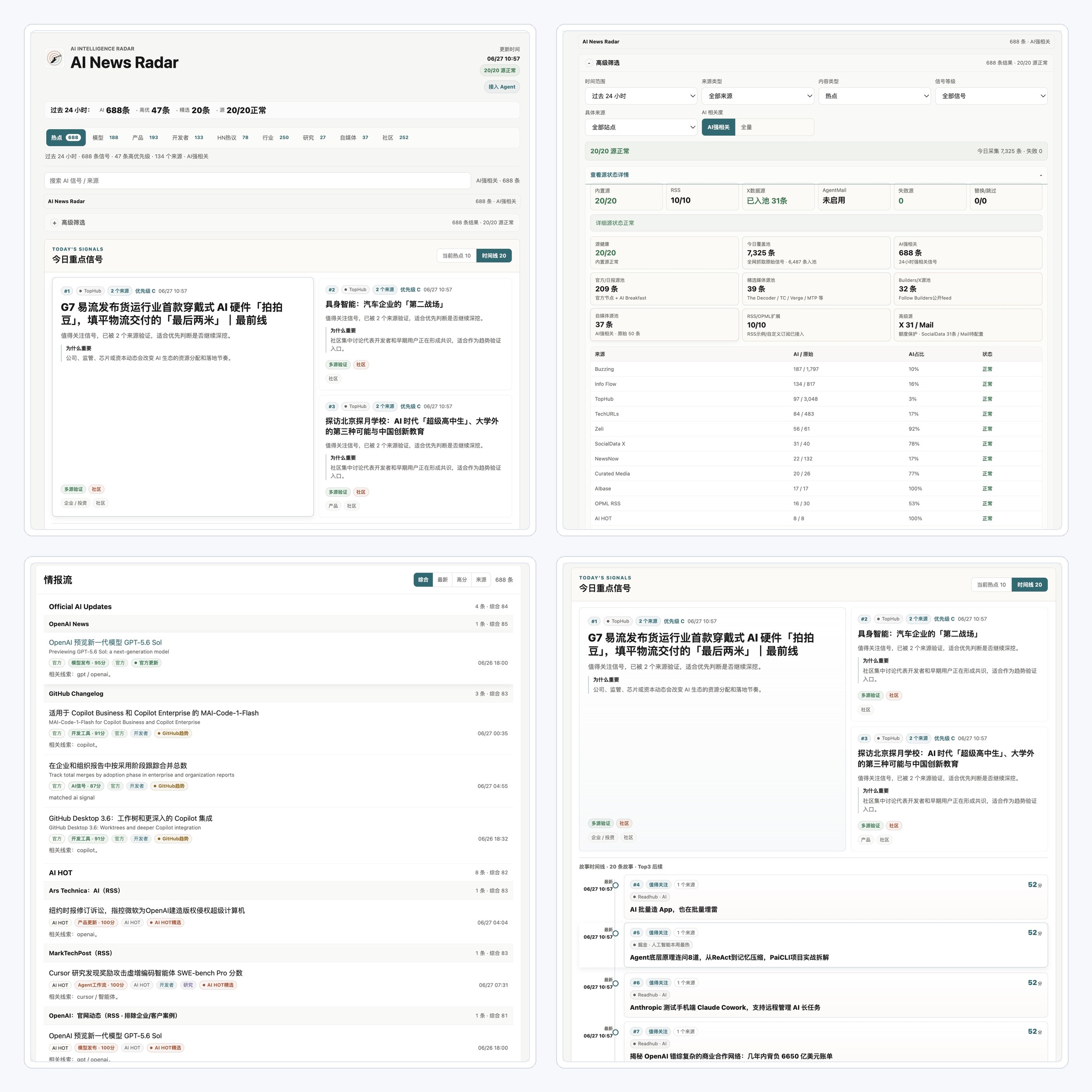
为什么需要伯乐Skill
好新闻分散在各处,
官方博客发一点,更新日志发一点,X上有人提前爆料,聚合站又把同一个新闻转来转去。
我以为的自己在追前沿,实际每天都在重复三件事,
打开几十个页面,肉眼+人脑过滤重复内容,猜哪条值得看。
让伯乐Skill先替你完成第一轮判断,哪些信源是千里马,哪些是噪音。
你可以随意增加信息源,还可以把一个信息源纳入输入范围,先让它在单独运行一周,再判断要不要录入。
AI News Radar从来都不是单纯把信息抓回来,
它更像是一条轻量的新闻pipeline,把来源判断、抓取、去重、AI强相关过滤、信息源健康状态和静态网页发布串起来,上线后不消耗模型额度。
能做什么
给普通读者
- 打开在线页面,直接看最近24小时AI、模型、Agent、开发者工具和技术生态更新
- 通过“伯乐精选”先看高价值故事线,再不用从几百条消息里肉眼筛选
- 在“AI信号流”里继续查看完整AI强相关消息
- 用站点、关键词、时间和来源筛选快速定位信息
- 看到每条消息的AI标签、AI相关性分数、来源平台和发布时间
- 通过源健康和AI占比判断:哪些源是真有料,哪些源更新很多但AI含量低
给内容创作者
- 保留原始来源链接,方便继续深挖、核对事实和做选题
- 把同一个事件的多个来源聚合到一起,减少重复阅读
- 用AI标签快速判断一条消息适合做图文、短视频、还是工具实测
- 用多源重合、官方一手、单源观察等信号判断选题可信度和优先级
给开发者和Agent
- 默认不需要 API Key、不需要登录态、不需要 LLM额度
- 支持官方 RSS/changelog、精选 AI 媒体 RSS、OPML/RSS、公开 GitHub feed/JSON、静态页面、AgentMail 等来源类型
- GitHub Actions自动生成
data/*.json并发布到 GitHub Pages - Codex / Claude Code / Hermes / OpenClaw 可以通过项目内置的伯乐Skill继续维护信源、抓取逻辑和页面
- 高级来源可以通过 GitHub Secrets或本地环境变量接入,避免把 token、cookies、私有 OPML 和邮箱正文写进仓库
v0.7:从时间线到热点雷达
v0.6 把分散的消息合并成了故事线。v0.7 回答的是下一个问题:
故事多了之后,怎么知道现在什么最热?
v0.7 重点能力包括:
- 当前热点视图:伯乐精选新增热点模式,按多源聚簇 × 时间衰减排序——几个独立信源同时在说的事,才配叫热点。没有足够多源热点时,这个视图自动隐藏。
- 社区分类:原“中文”栏目升级为“社区”,收纳 WaytoAGI、AIbase、中文媒体/公众号、Follow Builders/X 等社区型信号;WaytoAGI 不再作为首页常驻大板块,而是在社区栏目里展示最近更新日和近 7 日记录。
- 头条式 Top3:Top3 不只按时间或单一 AI 相关度排序,而是综合 AI HOT 原站分/内部相关度、官方/精选源权重、多源确认、48 小时新鲜度衰减和同源惩罚,尽量接近“先看什么”的编辑排序。
- 宁缺毋滥门槛:精选席位必须靠多源确认或高分挣来,安静的日子精选区直接消失,不留空壳,页面回到纯时间轴。
- 评分回测工具:
scripts/backtest_scoring.py把任意两个版本的评分逻辑在历史档案上重放对比。立下规矩:动评分必须附带 ≥14 天回测报告。 - ai-radar 消费Skill:装上后对Agent说"今天AI圈有什么",它直接读本站公开JSON出中文简报——零API、零Key,数据管道可fork。
v0.6 引入的故事线合并、AI标签分数、源健康与AI占比,仍是这一切的地基。历次改动见 Releases。
工作原理
flowchart LR
source["信息源清单"] --> classify["伯乐Skill判断信源类型"]
classify --> official["官方 RSS / changelog"]
classify --> opml["私人 OPML / RSS"]
classify --> publicFeed["公开 GitHub feed / JSON"]
classify --> staticPage["公开页面 / Jina 兜底"]
classify --> privateMail["AgentMail 邮箱订阅"]
classify --> skip["跳过高风险来源"]
official --> fetch["抓取与结构化"]
opml --> fetch
publicFeed --> fetch
staticPage --> fetch
privateMail --> fetch
fetch --> dedup["去重与归一化"]
dedup --> score["AI相关性评分与标签"]
score --> story["故事合并与多源证据聚合"]
score --> status["源健康与AI占比统计"]
story --> brief["伯乐精选 / daily-brief.json"]
story --> merged["stories-merged.json / merge-log.json"]
status --> sourceData["source-status.json"]
score --> latest["latest-24h.json / latest-24h-all.json"]
brief --> pages["GitHub Pages网页"]
merged --> pages
sourceData --> pages
latest --> pages
pages --> agent["伯乐Skill:Agent 继续维护信源"]
pages --> radar["ai-radar Skill:Agent 读报出简报"]AI News Radar学习了现代新闻学的技术,不是简单堆信息源,一次性放几万条信息出来等于没用,所以我选择把新闻处理拆成稳定pipeline,抓取,去重,过滤,补充状态,生成静态站点。
在保证稳定性的同时追求轻量化,公开版不要求用户配置LLM API Key,不依赖登录态,cookies,X API和邮箱。需要这些进阶能力时,可以通过伯乐Skill用GitHub Secrets或本地环境变量接入。
数据产物
每次更新会生成一组静态JSON文件,页面只读取这些文件,不需要后端服务。
核心文件包括:
data/latest-24h.json:最近24小时AI强相关消息data/latest-24h-all.json:最近24小时全量消息data/source-status.json:来源抓取状态、成功率、站点覆盖和源健康data/daily-brief.json:伯乐精选故事线,供首页 Top 3 优先级和高价值入口使用data/stories-merged.json:故事合并后的完整事件集合,页面会在精选故事之后继续接入完整故事池data/merge-log.json:故事合并过程和命中记录,方便调试与审计
如果 daily-brief.json 暂时不存在,页面会回退到候选信号列表;如果 stories-merged.json 存在,页面会用完整故事池补齐后续故事线,避免只有少量精选故事被接入。
快速开始
普通用户不用安装,直接打开在线页面即可。
想fork改造新版本,可以本地运行:
git clone https://github.com/LearnPrompt/ai-news-radar.git
cd ai-news-radar
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
python scripts/update_news.py --output-dir data --window-hours 24
python -m http.server 8080打开:
http://localhost:8080如果你有自己的 OPML:
cp feeds/follow.example.opml feeds/follow.opml
# 把自己的订阅源写进 feeds/follow.opml,不提交这个文件
python scripts/update_news.py --output-dir data --window-hours 24 --rss-opml feeds/follow.opml给Agent看的教程
如果你想让Codex / Claude Code / OpenClaw / Hermes帮你搭自己的版本,可以直接说:
请使用伯乐Skill,先问我要信息源清单,然后帮我判断每个信源该用RSS、公开feed、静态页面、Jina兜底、AgentMail邮箱还是跳过。目标是部署一个不需要服务器、能用GitHub Actions自动更新的 AI 日报网站。不要把任何API Key、cookies、token、私有邮件内容写入仓库。项目内置两个 Skill,分工是「雷达管读,伯乐管选」:
skills/radar/:ai-radar 雷达Skill(消费侧)——不用fork就能装,自然语言问AI资讯,读本站公开JSON出简报skills/ai-news-radar/:伯乐Skill(维护侧)——fork后用它录入信源、维护抓取逻辑、部署 GitHub Pages
新Agent接手验收时,推荐先读:
README.mdREADME.en.mddocs/GPT_HANDOFF.mddocs/SOURCE_COVERAGE.mddocs/V2_PRODUCT_BRIEF.md
GitHub 自动更新
.github/workflows/update-news.yml 已经配置好定时任务。
- 支持手动触发
workflow_dispatch;需要忽略 TikHub 的正常付费源间隔时,显式传入force_tikhub=true - 默认每 30 分钟运行一次:
*/30 * * * * - 自动生成并提交
data/*.json;工作流使用git add data/,避免新增 JSON 文件因为白名单遗漏而停留在旧更新时间 - 如果没有设置
FOLLOW_OPML_B64,线上工作流会自动使用公开示例feeds/follow.example.opml,让页面展示 RSS/OPML 能力 - 如果设置
FOLLOW_OPML_B64,会优先自动解码为私有feeds/follow.opml - 如果设置
EMAIL_DIGEST_ENABLED=1、AGENTMAIL_API_KEY、AGENTMAIL_INBOX_ID,会生成脱敏邮箱摘要 - 只有额外设置
EMAIL_DIGEST_PUBLISH=1,才会提交data/email-digest.json - 如果设置
X_API_ENABLED=1、X_BEARER_TOKEN和预算变量,会在每日指定UTC窗口用官方X API抓取少量公开Post;默认关闭,且当前X API按返回资源计费 - 如果设置
SOCIALDATA_ENABLED=1、SOCIALDATA_API_KEY和预算变量,会按SOCIALDATA_RUN_INTERVAL_HOURS(默认12小时)通过 SocialData.tools 抓取少量公开 X/Twitter 搜索结果;默认关闭,API Key 只应放在本地环境变量或 GitHub Secrets - 如果设置
TIKHUB_ENABLED=1、TIKHUB_API_KEY和预算变量,会按TIKHUB_RUN_INTERVAL_HOURS(默认24小时)通过 TikHub 抓取少量抖音/小红书关键词搜索结果;默认关闭,API Key 只应放在本地环境变量或 GitHub Secrets - SocialData/TikHub 的拉取间隔会记录在
data/paid-source-state.json,只保存上次运行时间、结果数和错误名,不保存 API Key;半小时工作流跳过付费源时,旧条目仍保留在data/archive.json,不会因为本轮未拉取就被清空
默认情况下,本项目不需要任何API Key就能跑核心流程。
线上页面右上角显示的“更新时间”来自 data/latest-24h.json 的 generated_at。如果页面长时间停在旧时间,优先检查 GitHub Actions 最近一次 Update AI News Snapshot 是否运行、是否有抓取错误、以及仓库 Pages 是否部署到包含最新 data/ 提交的分支。
高级源配置模板见 examples/advanced-sources.env.example,
预算说明见 docs/research/advanced-source-free-tier-budget-2026-05-10.md,
本地测试 TikHub 抓取时可以先小流量强制跑一次:
export TIKHUB_ENABLED=1
export TIKHUB_API_KEY='你的 TikHub API Key'
export TIKHUB_FORCE_RUN=1
export TIKHUB_QUERY='OpenAI,Claude,大模型,Agent,AI工具,人工智能,AI'
export TIKHUB_PLATFORMS=douyin,xiaohongshu
export TIKHUB_MAX_RESULTS=10
export TIKHUB_DAILY_ITEM_LIMIT=10
python3 scripts/probe_tikhub.py --query 'OpenAI,Claude,大模型,Agent,AI工具,人工智能,AI' --platforms douyin,xiaohongshu --max-results 10
python3 scripts/update_news.py --output-dir /tmp/ai-news-radar-tikhub --window-hours 24 --archive-days 3
python3 - <<'PY'
import json
from collections import Counter
status = json.load(open("/tmp/ai-news-radar-tikhub/source-status.json"))
latest = json.load(open("/tmp/ai-news-radar-tikhub/latest-24h-all.json"))
print("failed_sites =", status.get("failed_sites"))
print("empty_advanced_sources =", status.get("empty_advanced_sources"))
print("tikhub_status =", [s for s in status.get("sites", []) if str(s.get("site_id", "")).startswith("tikhub")])
counts = Counter(i.get("site_id") for i in latest.get("items_all_raw", []))
print("tikhub_24h_counts =", {k: counts[k] for k in sorted(counts) if str(k).startswith("tikhub")})
PY远端需要用当前 master 立即重跑 TikHub 时:
gh workflow run update-news.yml --ref master -f force_tikhub=true自媒体栏目使用独立的 7 天热榜池,不改变其他栏目的 24 小时窗口。抖音和 小红书搜索都优先请求“一周内最多点赞”,再从响应中提取点赞、收藏、评论 和分享数。榜单分数由 85% 互动热度和 15% 的 24 小时新鲜度加分组成;因此 真正的周内爆款优先,但刚开始起量的新内容仍有机会进入 Top 3。
小红书按“先搜索、后详情”处理。搜索阶段使用 App V2 的最多点赞排序和
7 天筛选,并再次在本地校验发布时间:可信 API 时间优先;0、未来时间
或缺失时间会回退到 note id 的时间前缀;仍无法确认或早于 7 天的笔记会被
跳过。通过时间门禁后,如需补齐图文详情,可按需调用官方详情接口:
import os
import requests
headers = {"Authorization": f"Bearer {os.environ['TIKHUB_API_KEY']}"}
search = requests.get(
"https://api.tikhub.io/api/v1/xiaohongshu/app_v2/search_notes",
headers=headers,
params={
"keyword": "AI",
"page": 1,
"sort_type": "popularity_descending",
"note_type": "不限",
"time_filter": "一周内",
},
timeout=30,
)
search.raise_for_status()
# Only request details after the search result passes the local 7-day time gate.
detail = requests.get(
"https://api.tikhub.io/api/v1/xiaohongshu/app_v2/get_image_note_detail",
headers=headers,
params={"note_id": "通过时间校验的 note_id"},
timeout=30,
)
detail.raise_for_status()
print(detail.json())视频笔记使用 get_video_note_detail。详情接口用于补充作者、互动量、图片、
标签等结构化字段,不替代搜索阶段的发布时间判断。
X API演示配置见 docs/guides/x-api-demo-config.md;
单账号/单newsletter演示见 docs/guides/rileybrown-alphasignal-demo.md。