JaxGCRL
![]()

![]()
![]()
Installation | Quick Start | Environments | Baselines | Citation
Accelerating Goal-Conditioned RL Algorithms and Research
arXiv link: https://arxiv.org/abs/2408.11052
We provide blazingly fast goal-conditioned environments based on MJX and BRAX for quick experimentation with goal-conditioned self-supervised reinforcement learning.
- Blazingly Fast Training - Train 10 million environment steps in 10 minutes on a single GPU, up to $22\times$ faster than prior implementations.
- Comprehensive Benchmarking - Includes 10+ diverse environments and multiple pre-implemented baselines for out-of-the-box evaluation.
- Modular Implementation - Designed for clarity and scalability, allowing for easy modification of algorithms.
Installation 📂
Editable Install (Recommended)
After cloning the repository, run one of the following commands.
With GPU on Linux:
pip install -e . -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
[!NOTE]
Make sure you have the correct CUDA version installed, i.e. CUDA >= 12.3. You can check your CUDA version withnvcc --versioncommand. If you have an older version, you can create a new conda environment with the correct version of CUDA and JaxGCRL package using the following command:conda env create -f environment.yml
With CPU on Mac:
export SDKROOT="$(xcrun --show-sdk-path)" # may be needed to build brax dependencies pip install -e .
PyPI
The package is also available on PyPI:
pip install jaxgcrl -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
Quick Start 🚀
To verify the installation, run a test experiment:
jaxgcrl crl --env ant
The jaxgcrl command is equivalent to invoking python run.py with the same arguments
[!NOTE]
If you haven't yet configuredwandb, you may be prompted to log in.
See scripts/train.sh for an example config.
A description of the available agents can be generated with jaxgcrl --help.
Available configs can be listed with jaxgcrl {crl,ppo,sac,td3} --help.
Common flags you may want to change include:
- env=...: replace "ant" with any environment name. See
jaxgcrl/utils/env.pyfor a list of available environments. - Removing --log_wandb: omits logging, if you don't want to use a wandb account.
- --total_env_steps: shorter or longer runs.
- --num_envs: based on how many environments your GPU memory allows.
- --contrastive_loss_fn, --energy_fn, --h_dim, --n_hidden, etc.: algorithmic and architectural changes.
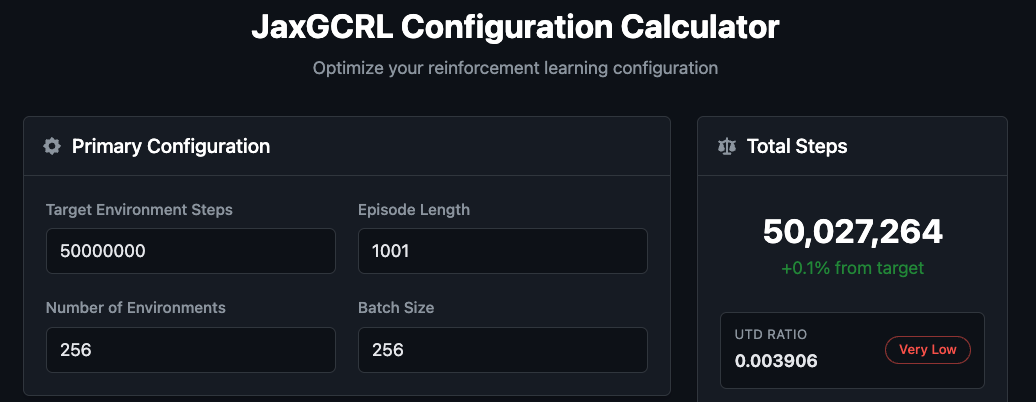
[!Note] We recommend using calculator by @riiswa for checking the correctness of hyperparameters:
Environment Interaction
Environments can be controlled with the reset and step functions. These methods return a state object, which is a dataclass containing the following fields:
state.pipeline_state: current, internal state of the environment
state.obs: current observation
state.done: flag indicating if the agent reached the goal
state.metrics: agent performance metrics
state.info: additional info
The following code demonstrates how to interact with the environment:
import jax from utils.env import create_env key = jax.random.PRNGKey(0) # Initialize the environment env = create_env('ant') # Use JIT compilation to make environment's reset and step functions execute faster jit_env_reset = jax.jit(env.reset) jit_env_step = jax.jit(env.step) NUM_STEPS = 1000 # Reset the environment and obtain the initial state state = jit_env_reset(key) # Simulate the environment for a fixed number of steps for _ in range(NUM_STEPS): # Generate a random action key, key_act = jax.random.split(key, 2) random_action = jax.random.uniform(key_act, shape=(8,), minval=-1, maxval=1) # Perform an environment step with the generated action state = jit_env_step(state, random_action)
Wandb support 📈
We strongly recommend using Wandb for tracking and visualizing results (Wandb support). Enable Wandb logging with the --log_wandb flag. The following flags are also available to organize experiments:
--project_name--group_name--exp_name
The --log_wandb flag logs metrics to Wandb. By default, metrics are logged to a CSV.
- Run example
sweep:
wandb sweep --project example_sweep ./scripts/sweep.yml
- Then run
wandb agentwith :
wandb agent <previous_command_output>
We also render videos of the learned policies as wandb artifacts.

Environments 🌎
We currently support a variety of continuous control environments:
- Locomotion: Half-Cheetah, Ant, Humanoid
- Locomotion + task: AntMaze, AntBall (AntSoccer), AntPush, HumanoidMaze
- Simple arm: Reacher, Pusher, Pusher 2-object
- Manipulation: Reach, Grasp, Push (easy/hard), Binpick (easy/hard)
| Environment | Env name | Code |
|---|---|---|
| Reacher | reacher | link |
| Half Cheetah | cheetah | link |
| Pusher | pusher_easy pusher_hard | link |
| Ant | ant | link |
| Ant Maze | ant_u_maze ant_big_maze ant_hardest_maze | link |
| Ant Soccer | ant_ball | link |
| Ant Push | ant_push | link |
| Humanoid | humanoid | link |
| Humanoid Maze | humanoid_u_maze humanoid_big_maze humanoid_hardest_maze | link |
| Arm Reach | arm_reach | link |
| Arm Grasp | arm_grasp | link |
| Arm Push | arm_push_easy arm_push_hard | link |
| Arm Binpick | arm_binpick_easy arm_binpick_hard | link |
To add new environments: add an XML to envs/assets, add a python environment file in envs, and register the environment name in utils.py.
Baselines 🤖
We currently support following algorithms:
| Algorithm | How to run | Code |
|---|---|---|
| CRL | python run.py crl ... | link |
| PPO | python run.py ppo ... | link |
| SAC | python run.py sac ... | link |
| SAC + HER | python run.py sac ... --use_her | link |
| TD3 | python run.py td3 ... | link |
| TD3 + HER | python run.py td3 ... --use_her | link |
Code Structure 📝
The core structure of the codebase is as follows:
run.py: Takes the name of an agent and runs with the specified configs.
agents/
├── agents/
│ ├── crl/
│ │ ├── crl.py CRL algorithm
│ │ ├── losses.py contrastive losses and energy functions
│ │ └── networks.py CRL network architectures
│ ├── ppo/
│ │ └── ppo.py PPO algorithm
│ ├── sac/
│ │ ├── sac.py SAC algorithm
│ │ └── networks.py SAC network architectures
│ └── td3/
│ ├── td3.py TD3 algorithm
│ ├── losses.py TD3 loss functions
│ └── networks.py TD3 network architectures
├── utils/
│ ├── config.py Base run configs
│ ├── env.py Logic for rendering and environment initialization
│ ├── replay_buffer.py: Contains replay buffer, including logic for state, action, and goal sampling for training.
│ └── evaluator.py: Runs evaluation and collects metrics.
├── envs/
│ ├── ant.py, humanoid.py, ...: Most environments are here.
│ ├── assets: Contains XMLs for environments.
│ └── manipulation: Contains all manipulation environments.
└── scripts/train.sh: Modify to choose environment and hyperparameters.
The architecture can be adjusted in networks.py.
Contributing 🏗️
Help us build JaxGCRL into the best possible tool for the GCRL community. Reach out and start contributing or just add an Issue/PR!
- Add Franka robot arm environments. [Done by SimpleGeometry]
- Get around 70% success rate on Ant Big Maze task. [Done by RajGhugare19]
- Add more complex versions of Ant Sokoban.
- Integrate environments:
- Overcooked
- Hanabi
- Rubik's cube
- Sokoban
To run tests (make sure you have access to a GPU):
python -m pytest
Citing JaxGCRL 📜
If you use JaxGCRL in your work, please cite us as follows:@inproceedings{bortkiewicz2025accelerating, author = {Bortkiewicz, Micha\l{} and Pa\l{}ucki, W\l{}adek and Myers, Vivek and Dziarmaga, Tadeusz and Arczewski, Tomasz and Kuci\'{n}ski, \L{}ukasz and Eysenbach, Benjamin}, booktitle = {{International Conference} on {Learning Representations}}, title = {{Accelerating Goal-Conditioned RL Algorithms} and {Research}}, url = {https://arxiv.org/pdf/2408.11052}, year = {2025}, }
Questions ❓
If you have any questions, comments, or suggestions, please reach out to Michał Bortkiewicz (michalbortkiewicz8@gmail.com).
See Also 🙌
There are a number of other libraries which inspired this work, we encourage you to take a look!
JAX-native algorithms:
- Mava: JAX implementations of IPPO and MAPPO, two popular MARL algorithms.
- PureJaxRL: JAX implementation of PPO, and demonstration of end-to-end JAX-based RL training.
- Minimax: JAX implementations of autocurricula baselines for RL.
- JaxIRL: JAX implementation of algorithms for inverse reinforcement learning.
JAX-native environments:
- Gymnax: Implementations of classic RL tasks including classic control, bsuite and MinAtar.
- Jumanji: A diverse set of environments ranging from simple games to NP-hard combinatorial problems.
- Pgx: JAX implementations of classic board games, such as Chess, Go and Shogi.
- Brax: A fully differentiable physics engine written in JAX, features continuous control tasks.
- XLand-MiniGrid: Meta-RL gridworld environments inspired by XLand and MiniGrid.
- Craftax: (Crafter + NetHack) in JAX.
- JaxMARL: Multi-agent RL in Jax.