
![]()



NVIDIA NeMo Curator
GPU-accelerated data curation for training better AI models, faster. Scale from laptop to multi-node clusters with modular pipelines for text, images, video, and audio.
Part of the NVIDIA NeMo software suite for managing the AI agent lifecycle.
What You Can Do
| Modality | Key Capabilities | Get Started |
|---|---|---|
| Text | Deduplication • Classification • Quality Filtering • Language Detection | Text Guide |
| Image | Aesthetic Filtering • NSFW Detection • Embedding Generation • Deduplication | Image Guide |
| Video | Scene Detection • Clip Extraction • Motion Filtering • Deduplication | Video Guide |
| Audio | ASR Transcription • Quality Assessment • WER Filtering | Audio Guide |
Quick Start
# Install for your modality uv pip install "nemo-curator[text_cuda12]" # Run the quickstart example python tutorials/quickstart.py
Full setup: Installation Guide • Docker • Tutorials
Features by Modality
Text Curation
Process and curate high-quality text datasets for large language model (LLM) training with multilingual support.
| Category | Features | Documentation |
|---|---|---|
| Data Sources | Common Crawl • Wikipedia • ArXiv • Custom datasets | Load Data |
| Quality Filtering | 30+ heuristic filters • fastText classification • GPU-accelerated classifiers for domain, quality, safety, and content type | Quality Assessment |
| Deduplication | Exact • Fuzzy (MinHash LSH) • Semantic (GPU-accelerated) | Deduplication |
| Processing | Text cleaning • Language identification | Content Processing |
Image Curation
Curate large-scale image datasets for vision language models (VLMs) and generative AI training.
| Category | Features | Documentation |
|---|---|---|
| Data Loading | WebDataset format • Large-scale image-text pairs | Load Data |
| Embeddings | CLIP embeddings for semantic analysis | Embeddings |
| Filtering | Aesthetic quality scoring • NSFW detection | Filters |
Video Curation
Process large-scale video corpora with distributed, GPU-accelerated pipelines for world foundation models (WFMs).
| Category | Features | Documentation |
|---|---|---|
| Data Loading | Local paths • S3-compatible storage • HTTP(S) URLs | Load Data |
| Clipping | Fixed-stride splitting • Scene-change detection (TransNetV2) | Clipping |
| Processing | GPU H.264 encoding • Frame extraction • Motion filtering • Aesthetic filtering | Processing |
| Embeddings | Cosmos-Embed1 for clip-level embeddings | Embeddings |
| Deduplication | K-means clustering • Pairwise similarity for near-duplicates | Deduplication |
Audio Curation
Prepare high-quality speech datasets for automatic speech recognition (ASR) and multimodal AI training.
| Category | Features | Documentation |
|---|---|---|
| Data Loading | Local files • Custom manifests • Public datasets (FLEURS) | Load Data |
| ASR Processing | NeMo Framework pretrained models • Automatic transcription | ASR Inference |
| Quality Assessment | Word Error Rate (WER) calculation • Duration analysis • Quality-based filtering | Quality Assessment |
| Integration | Text curation workflow integration for multimodal pipelines | Text Integration |
Why NeMo Curator?
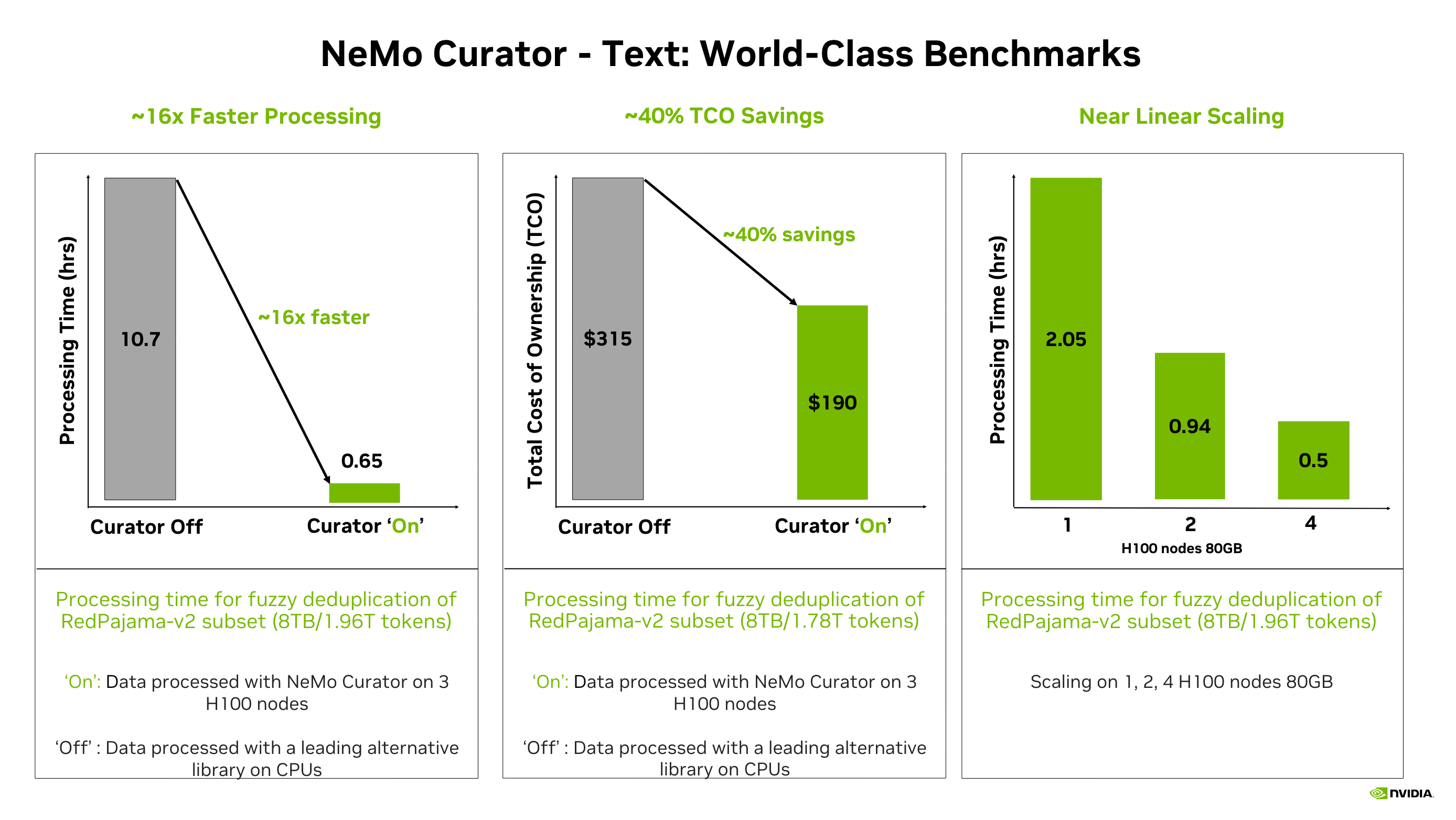
Performance at Scale
NeMo Curator leverages NVIDIA RAPIDS™ libraries such as cuDF, cuML, and cuGraph along with Ray to scale workloads across multi-node, multi-GPU environments.
Proven Results:
- 16× faster fuzzy deduplication on 8 TB RedPajama v2 (1.78 trillion tokens)
- 40% lower total cost of ownership (TCO) compared to CPU-based alternatives
- Near-linear scaling from one to four H100 80 GB nodes (2.05 hrs → 0.50 hrs)
Quality Improvements
Data curation modules measurably improve model performance. In ablation studies using a 357M-parameter GPT model trained on curated Common Crawl data:
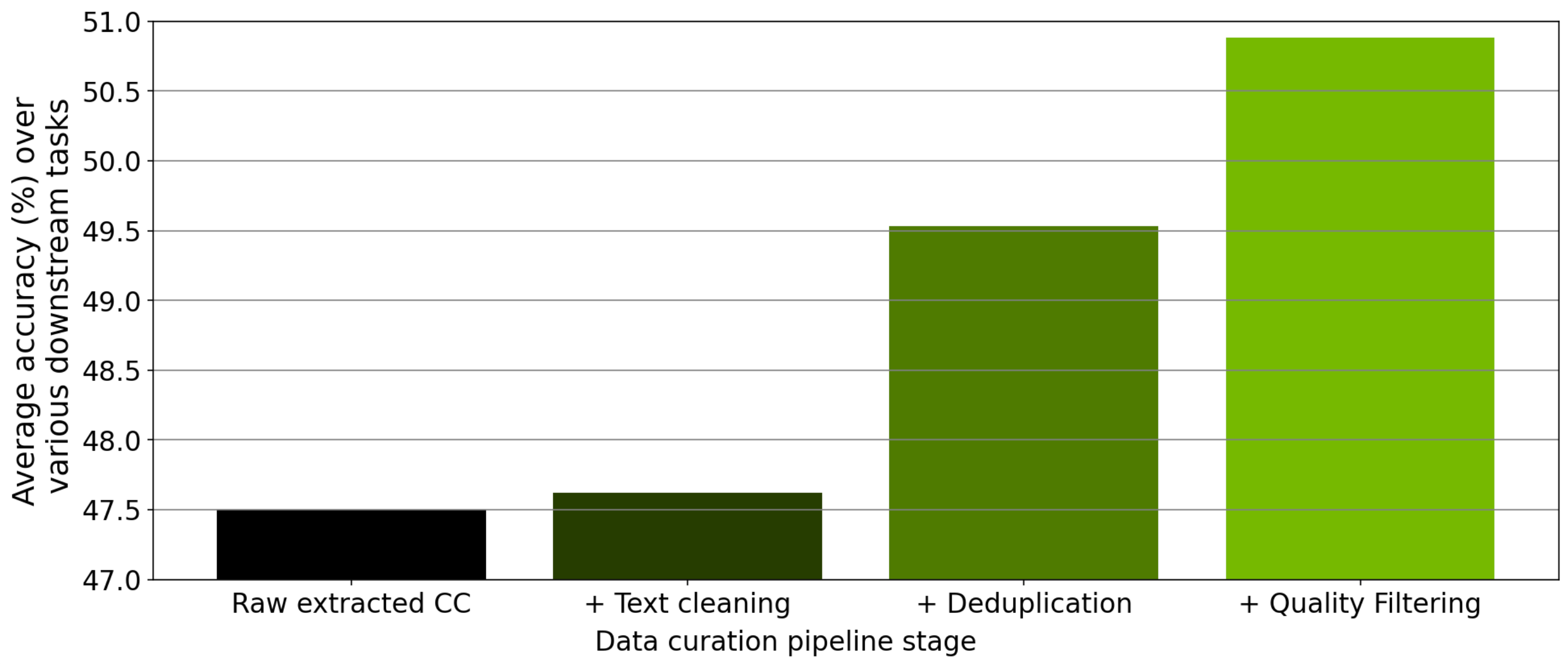
Results: Progressive improvements in zero-shot downstream task performance through text cleaning, deduplication, and quality filtering stages.
Learn More
| Resource | Links |
|---|---|
| Documentation | Main Docs • API Reference • Concepts |
| Tutorials | Text • Image • Video • Audio |
| Deployment | Installation • Infrastructure |
| Community | GitHub Discussions • Issues |
Contribute
We welcome community contributions! Please refer to CONTRIBUTING.md for guidelines.