LingBot-Map: Geometric Context Transformer for Streaming 3D Reconstruction
Robbyant Team




https://github.com/user-attachments/assets/fe39e095-af2c-4ec9-b68d-a8ba97e505ab
🗺️ Meet LingBot-Map! We've built a feed-forward 3D foundation model for streaming 3D reconstruction! 🏗️🌍
LingBot-Map has focused on:
- Geometric Context Transformer: Architecturally unifies coordinate grounding, dense geometric cues, and long-range drift correction within a single streaming framework through anchor context, pose-reference window, and trajectory memory.
- High-Efficiency Streaming Inference: A feed-forward architecture with paged KV cache attention, enabling stable inference at ~20 FPS on 518×378 resolution over long sequences exceeding 10,000 frames.
- State-of-the-Art Reconstruction: Superior performance on diverse benchmarks compared to both existing streaming and iterative optimization-based approaches.
📑 Table of Contents
Click to expand
📰 News
- 2026-06-28 — Fixed an SDPA KV cache bug. The SDPA backend now performs better on long sequences. We still recommend the FlashInfer backend for the best performance.
- 2026-05-25 — 📊 Evaluation benchmark released. We released the evaluation scripts for KITTI and Oxford Spires — see benchmark/ for the pipeline, and run
preprocess/oxford.pyto prepare Oxford Spires data before evaluation. - 2026-04-29 — 📹 Long-video demo released. We released a very-long-video example (~25 000 frames, 13-minute indoor walkthrough) rendered with the offline pipeline — see Worked Example for the command, flag rationale, and rendered output.
- 2026-04-27 — 🚀 LingBot-Map accelerated. Pull the latest
mainand runpython demo.py --compile ...orpython gct_profile.py --backend flashinfer --dtype bf16 --compileto verify on your hardware. - 2026-04-24 — Fixed a FlashInfer KV cache bug where
--keyframe_interval > 1silently cached non-keyframes. You should now see better pose and reconstruction quality when running with more than 320 frames.
📋 TODO
- ✅ Release evaluation benchmark
- ✅ Oxford Spires dataset
- ✅ KITTI dataset
- ✅ VBR dataset
- ✅ Droid-W dataset
- ✅ TUM-D dataset
- ✅ 7-scenes dataset
- ✅ ETH3D dataset
- ✅ Tanks and Temples dataset
- ✅ NRGBD dataset
- ✅ Release demo scripts
- ✅ Indoor long-video demo (Featured indoor walkthrough)
- ✅ Outdoor long-video demo
- ✅ LingBot-World demo
- ✅ Aerial long-video demo
⚙️ Installation
1. Create conda environment
conda create -n lingbot-map python=3.10 -y
conda activate lingbot-map2. Install PyTorch (CUDA 12.8)
pip install torch==2.8.0 torchvision==0.23.0 --index-url https://download.pytorch.org/whl/cu128PyTorch 2.8.0 is the recommended version because NVIDIA Kaolin (required by the batch rendering pipeline) has prebuilt wheels for
torch-2.8.0_cu128. If you only needdemo.pyyou may use a newer PyTorch, but the batch renderer then requires building Kaolin from source. For other CUDA versions, see PyTorch Get Started.
3. Install lingbot-map
pip install -e .4. Install FlashInfer (recommended)
FlashInfer provides paged KV cache attention for efficient streaming inference. It is a pure-Python package that JIT-compiles CUDA kernels on first use, so a single wheel works across CUDA/PyTorch versions:
pip install --index-url https://pypi.org/simple flashinfer-python
--index-url https://pypi.org/simpleis only needed if your default pip index is an internal mirror that doesn't haveflashinfer-python. (Optional) For faster first-use, you can additionally install a CUDA-specific JIT cache:pip install flashinfer-jit-cache -f https://flashinfer.ai/whl/cu128/flashinfer-jit-cache/. See FlashInfer installation for details. If FlashInfer is not installed, the model falls back to SDPA (PyTorch native attention) via--use_sdpa.
5. Visualization dependencies (optional)
pip install -e ".[vis]"📦 Model Download
| Model Name | Huggingface Repository | ModelScope Repository | Description |
|---|---|---|---|
| lingbot-map-long | robbyant/lingbot-map | Robbyant/lingbot-map | Better suited for long sequences and large scale scenes (Recommend). |
| lingbot-map | robbyant/lingbot-map | Robbyant/lingbot-map | Balanced checkpoint — trade off all-around performance across short and long sequences. |
| lingbot-map-stage1 | robbyant/lingbot-map | Robbyant/lingbot-map | Stage-1 training checkpoint of lingbot-map — can be loaded into the VGGT model for bidirectional inference (c2w). |
🚧 Coming soon: we're training an stronger model that supports longer sequences — stay tuned.
🚀 Quick Start
After installation, run your first scene with one command:
python demo.py --model_path /path/to/lingbot-map-long.pt \
--image_folder example/courthouse --mask_skyThis launches an interactive viser viewer at http://localhost:8080. See Interactive Demo below for the full set of scenes and flags, or jump to Offline Rendering Pipeline for long-sequence batch rendering.
🎬 Interactive Demo (demo.py)
Run demo.py for interactive 3D visualization via a browser-based viser viewer (default http://localhost:8080).
Try the Example Scenes
We provide four example scenes in example/ that you can run out of the box:
# courthouse scene
python demo.py --model_path /path/to/lingbot-map-long.pt \
--image_folder example/courthouse --mask_skyhttps://github.com/user-attachments/assets/aa10f7ab-8024-43c7-92f8-d56159ec85c8
# University scene
python demo.py --model_path /path/to/lingbot-map-long.pt \
--image_folder example/university --mask_skyhttps://github.com/user-attachments/assets/212a1744-6ff5-4ccf-9bd4-728608248b57
# Loop scene (loop closure trajectory)
python demo.py --model_path /path/to/lingbot-map-long.pt \
--image_folder example/loophttps://github.com/user-attachments/assets/5ae0a292-b081-40c6-838c-b7c1a0538d75
# Oxford scene with sky masking (outdoor, large scale scene)
python demo.py --model_path /path/to/lingbot-map-long.pt \
--image_folder example/oxford --mask_skyhttps://github.com/user-attachments/assets/6b8daa95-9ed4-40b2-9902-7435779b886d
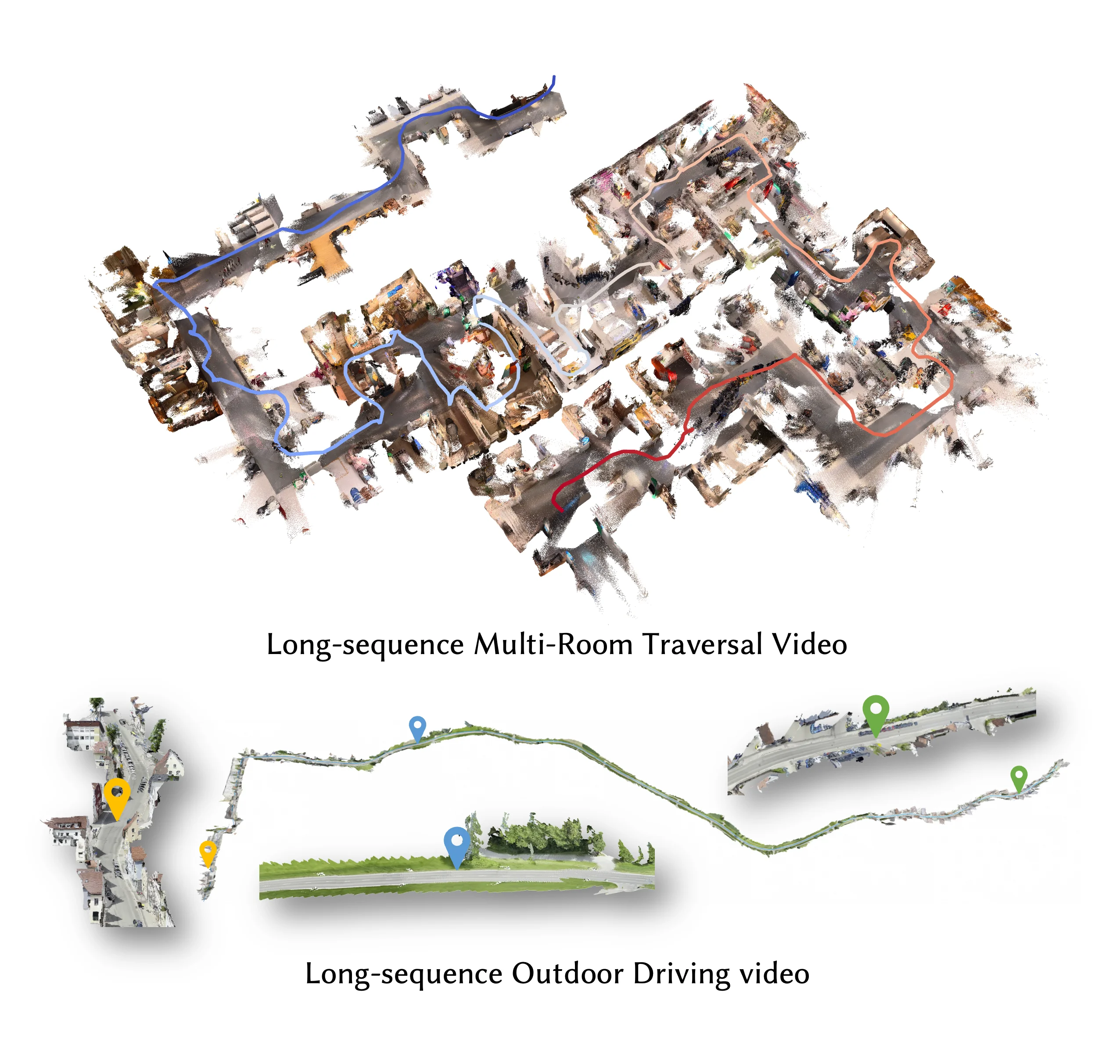
🎯 Featured: indoor walkthrough (~25 000 frames, 13 minutes)
Sequence is too long for the interactive viser viewer — this clip was rendered with the Offline Rendering Pipeline. See that section for the full command.
We will provide more examples in the follow-up.
Streaming with Keyframe Interval
Use --keyframe_interval to reduce KV cache memory by only keeping every N-th frame as a keyframe. Non-keyframe frames still produce predictions but are not stored in the cache. This is useful for long sequences which exceed 320 frames (We train with video RoPE on 320 views, so performance degrades when the KV cache stores more than 320 views. Using a keyframe strategy allows inference over longer sequences.).
Dataset: Download the demo sequences from robbyant/lingbot-map-demo on Hugging Face.
Example run on the travel sequence from the dataset above (sky masking on, 4 camera optimization iterations, keyframe every 2 frames):
python demo.py \
--image_folder /path/to/lingbot-map-demo/travel/ \
--model_path /path/to/lingbot-map-long.pt \
--mask_sky \
--camera_num_iterations 4 \
--keyframe_interval 2https://github.com/user-attachments/assets/d350b590-d036-4363-af8c-7af3918338ef
Note on inference range. Our method does not perform state resetting by default, so the maximum inference range is bounded by the longest distance seen during training on the dataset. Beyond that distance, state resetting becomes necessary. If you observe pose collapse, switch to windowed mode (
--mode windowed) — in most cases tuning--keyframe_intervalalone is enough and the rest of the windowed parameters can stay at their defaults.
Windowed Inference (for long sequences, >3000 frames)
python demo.py --model_path /path/to/lingbot-map-long.pt \
--video_path video.mp4 --fps 10 \
--mode windowed --window_size 128 --overlap_keyframes 16 --keyframe_interval 2 Sky Masking
Sky masking uses an ONNX sky segmentation model to filter out sky points from the reconstructed point cloud, which improves visualization quality for outdoor scenes.
Setup:
# Install onnxruntime (required)
pip install onnxruntime # CPU
# or
pip install onnxruntime-gpu # GPU (faster for large image sets)The sky segmentation model (skyseg.onnx) will be automatically downloaded from HuggingFace on first use.
Usage:
python demo.py --model_path /path/to/checkpoint.pt \
--image_folder /path/to/images/ --mask_skySky masks are cached in <image_folder>_sky_masks/ so subsequent runs skip regeneration. You can also specify a custom cache directory with --sky_mask_dir, or save side-by-side mask visualizations with --sky_mask_visualization_dir:
python demo.py --model_path /path/to/checkpoint.pt \
--image_folder /path/to/images/ --mask_sky \
--sky_mask_dir /path/to/cached_masks/ \
--sky_mask_visualization_dir /path/to/mask_viz/Visualization Options
| Argument | Default | Description |
|---|---|---|
--port | 8080 | Viser viewer port |
--conf_threshold | 1.5 | Visibility threshold for filtering low-confidence points |
--point_size | 0.00001 | Point cloud point size |
--downsample_factor | 10 | Spatial downsampling for point cloud display |
Performance & Memory
Without FlashInfer (SDPA fallback)
python demo.py --model_path /path/to/checkpoint.pt \
--image_folder /path/to/images/ --use_sdpaRunning on Limited GPU Memory
If you run into out-of-memory issues, try one (or both) of the following:
--offload_to_cpu— offload per-frame predictions to CPU during inference (on by default; use--no-offload_to_cpuonly if you have memory to spare).--num_scale_frames 2— reduce the number of bidirectional scale frames from the default 8 down to 2, which shrinks the activation peak of the initial scale phase.
Faster Inference
Lower the number of iterative refinement steps in the camera head to trade a small amount of pose accuracy for wall-clock speed:
python demo.py --model_path /path/to/checkpoint.pt \
--image_folder /path/to/images/ --camera_num_iterations 1--camera_num_iterations defaults to 4; setting it to 1 skips three refinement passes in the camera head (and shrinks its KV cache by 4×).
🎥 Offline Rendering Pipeline (demo_render/batch_demo.py)
Use this pipeline when your sequence is too long for the interactive viser viewer — for example, the indoor walkthrough featured above. demo_render/batch_demo.py is the all-in-one offline entry point: feed it a video or a folder of images and it will run model inference and produce a headless point-cloud flythrough MP4 in a single command. It shares the same PyTorch / FlashInfer / checkpoint stack as demo.py.
For those constrained by limited VRAM or GPU usage, you may also refer to the implementation at: https://github.com/ureeey/lingbot-map-rtx4060-8g/commit/eeee84a89cc97c1e39b736b46df4ee315275700b
Install (extends the main install)
1. Rendering Python dependencies
pip install -e ".[vis,render]"render pulls in open3d>=0.19 and pyyaml (the core numpy<2 constraint comes from the base lingbot-map install). Sky masking in this pipeline uses onnxruntime-gpu for batched segmentation; install it if you don't already have the CPU onnxruntime:
pip install onnxruntime-gpu2. Kaolin — matches the PyTorch 2.8.0 + CUDA 12.8 recommended above:
pip install --index-url https://pypi.org/simple \
kaolin -f https://nvidia-kaolin.s3.us-east-2.amazonaws.com/torch-2.8.0_cu128.html
--index-url https://pypi.org/simplebypasses any internal mirror that might otherwise serve the PyPI placeholder wheel (which raisesImportErroron import). NVIDIA Kaolin does not publish prebuilt wheels for PyTorch 2.9.x — if you're on 2.9 for other reasons, build Kaolin from source (pip install --no-build-isolation git+https://github.com/NVIDIAGameWorks/kaolin.git, needs local CUDA toolkit). For other torch/CUDA combinations see NVIDIA Kaolin installation.
3. ffmpeg
sudo apt install ffmpeg # or: brew install ffmpeg4. CUDA extensions (required before first run)
cd demo_render/render_cuda_ext && python setup.py build_ext --inplace && cd ../..This builds voxel_morton_ext and frustum_cull_ext in place — both are imported by rgbd_render for GPU voxelization and frustum culling.
Worked Example — long indoor walkthrough (~25 000 frames, 13 minutes)
Dataset: Download the example video from robbyant/lingbot-map-demo on Hugging Face.
python demo_render/batch_demo.py \
--video_path /data/demo_videos/indoor_travel.MP4 \
--output_folder /data/outputs/indoor_travel/ \
--model_path /path/to/lingbot-map.pt \
--config demo_render/config/indoor.yaml \
--mode windowed --window_size 128 \
--keyframe_interval 13 --overlap_keyframes 8 \
--sky_mask_dir /data/outputs/sky_masks \
--sky_mask_visualization_dir /data/outputs/sky_mask_viz \
--camera_vis default --keyframes_only_points \
--frame_tag --frame_tag_position top_right \
--save_predictionsFlag-by-flag rationale:
| Flag | Why it's there |
|---|---|
--mode windowed --window_size 128 | Sliding-window inference is required once the sequence exceeds the ~320-frame RoPE training range; each window resets the KV cache. window_size counts KV-cache slots, not actual frames — the first num_scale_frames (=8) slots hold the scale frames and the remaining 128 − 8 = 120 slots hold keyframes. With keyframe_interval = 13, one window therefore covers 8 + 120 × 13 = 1568 actual frames. |
--keyframe_interval 13 | Cache only every 13th frame as a keyframe. Non-keyframes still emit per-frame predictions but don't grow the KV cache |
--overlap_keyframes 8 | Adjacent windows share 8 keyframes of context, resolved internally to max(num_scale_frames, 8 × keyframe_interval) = 8 × 13 = 104 actual frames of overlap. Recommended whenever keyframe_interval > 1, to keep cross-window pose alignment stable. |
--config demo_render/config/indoor.yaml | Seed render/scene/camera/overlay defaults from the indoor preset (short depth, tighter follow cam). Any CLI flag the user explicitly passes still overrides the YAML value. |
--sky_mask_dir / --sky_mask_visualization_dir | Persist sky masks and their side-by-side visualizations to disk so subsequent reruns reuse them instead of re-running ONNX segmentation. (The render pipeline only consumes them when sky masking is enabled — by the YAML preset or by --mask_sky.) |
--camera_vis default | Overlay the trajectory trail + recent-frame points on the rendered video. |
--keyframes_only_points | Only unproject keyframe depth into the point cloud; non-keyframes still contribute their pose to the trajectory/frustum overlay. Keeps the cloud sparse for very long sequences. |
--frame_tag --frame_tag_position top_right | Stamp a <i> / <N> Frames counter in the top-right corner of the MP4. |
--save_predictions | Persist per-frame NPZs alongside the MP4. Useful for inspection or for re-rendering with different camera/overlay settings later. |
Worked Example — outdoor drive scene
Dataset: Download the example video from robbyant/lingbot-map-demo on Hugging Face.
python demo_render/batch_demo.py \
--video_path /data/demo_videos/drive_frames.mp4 \
--output_folder /data/outputs/drive/ \
--model_path /path/to/lingbot-map.pt \
--config demo_render/config/outdoor_drive.yaml \
--mode windowed --window_size 128 \
--max_non_keyframe_gap 100 --overlap_keyframes 8 \
--image_stride 1 \
--sky_mask_dir /data/outputs/sky_masks \
--sky_mask_visualization_dir /data/outputs/sky_mask_viz \
--camera_vis default --keyframes_only_points \
--frame_tag --frame_tag_position top_right \
--save_predictionsWhat differs from the indoor walkthrough above:
| Flag | Why it's there |
|---|---|
--config demo_render/config/outdoor_drive.yaml | Seed defaults from the outdoor preset: sky masking enabled, deeper render range (max_depth: 250), and a follow cam tuned for vehicle trajectories with a final birdeye reveal. |
--image_stride 1 | Use every video frame. Increase it to subsample long or high-FPS drive footage. |
--max_non_keyframe_gap 100 | Upper bound on consecutive non-keyframes before a keyframe is forced. Only active with flow-based keyframe selection (--flow_threshold > 0); in the default fixed-interval mode it has no effect. |
The remaining flags (--mode windowed --window_size 128, --overlap_keyframes 8, sky-mask caching, overlays, --save_predictions) carry over unchanged from the indoor example — see the flag-by-flag table above.
Camera Path (YAML)
The virtual camera path is described by the camera.segments list in the YAML preset passed via --config. Edit the YAML to design your own shot — no need to touch CLI flags.
Built-in presets live in demo_render/config/: default.yaml, indoor.yaml, indoor_overview.yaml, outdoor_large.yaml, outdoor_large_overview.yaml, surrounding.yaml, lingbo_world.yaml. Copy one and edit the camera: block.
YAML structure
camera:
fov: 60.0 # camera field of view in degrees
transition: 30 # frames blended between adjacent segments
segments:
- mode: follow # chase cam following the input trajectory
frames: [0, 1500] # rendered-frame range this segment covers (-1 = end)
back_offset: 0.3 # how far behind the input camera (fraction of scene scale)
up_offset: 0.08 # vertical lift above the input camera
look_offset: 0.4 # how far ahead the lookat target points
smooth_window: 30 # trajectory smoothing window in frames
- mode: birdeye # rise up for a top-down reveal of the whole scene
frames: [1500, 1800]
reveal_height_mult: 2.5 # birdeye height = scene scale × this factor
- mode: follow # drop back into chase cam
frames: [1800, -1]
back_offset: 0.3
up_offset: 0.08
look_offset: 0.4transition controls how many frames are blended between adjacent segments; frames: [0, -1] means "the whole sequence".
Available modes
mode | Behavior | Tunable fields |
|---|---|---|
follow | Chase cam tracks the input trajectory with smooth offsets. The most cinematic option for walkthroughs. | back_offset, up_offset, look_offset, smooth_window, scale_frames |
birdeye | Top-down reveal of the whole scene. Useful for hero / overview shots. | reveal_height_mult |
static | Fixed eye + lookat, auto-derived from the segment's start frame. | — |
pivot | Fixed eye, lookat sweeps along the trajectory. | — |
Single-shot YAML examples
Pure follow (most common):
camera:
fov: 60.0
segments:
- mode: follow
frames: [0, -1]
back_offset: 0.3
up_offset: 0.08
look_offset: 0.4
smooth_window: 30Full birdeye (good for overview / hero shots):
camera:
fov: 60.0
segments:
- mode: birdeye
frames: [0, -1]
reveal_height_mult: 2.5Follow with birdeye inserts: just list multiple segments in order under segments: — adjacent segments are interpolated using transition frames.
Caveat: when
--configloads a YAML preset, passing any segment-shaping CLI flag (--camera_mode,--back_offset,--up_offset,--look_offset,--smooth_window,--follow_scale_frames,--birdeye_start,--birdeye_duration,--reveal_height_mult) discards the YAML'ssegmentsand rebuilds the camera path from those flags instead. To stay fully YAML-driven, don't pass any of them on the command line.
Output files
For a given output name (e.g. <scene> or <video_name>):
| File | Description |
|---|---|
<name>_pointcloud.mp4 | Rendered point-cloud flythrough |
<name>_pointcloud_rgb.mp4 | Original RGB frames encoded as video |
<name>_pointcloud_config.yaml | Full config snapshot of this run |
batch_results.json | Per-scene success / duration summary |
📜 License
This project is released under the Apache License 2.0. See LICENSE file for details.
📖 Citation
@article{chen2026geometric,
title={Geometric Context Transformer for Streaming 3D Reconstruction},
author={Chen, Lin-Zhuo and Gao, Jian and Chen, Yihang and Cheng, Ka Leong and Sun, Yipengjing and Hu, Liangxiao and Xue, Nan and Zhu, Xing and Shen, Yujun and Yao, Yao and Xu, Yinghao},
journal={arXiv preprint arXiv:2604.14141},
year={2026}
}✨ Acknowledgments
We thank Shangzhan Zhang, Jianyuan Wang, Yudong Jin, Christian Rupprecht, and Xun Cao for their helpful discussions and support.
This work builds upon several excellent open-source projects: