LingBot-VLA: A Pragmatic VLA Foundation Model




🥳 We are excited to introduce LingBot-VLA, a pragmatic Vision-Language-Action foundation model.
LingBot-VLA has focused on being Pragmatic:
- Large-scale Pre-training Data: 20,000 hours of real-world data from 9 popular dual-arm robot configurations.
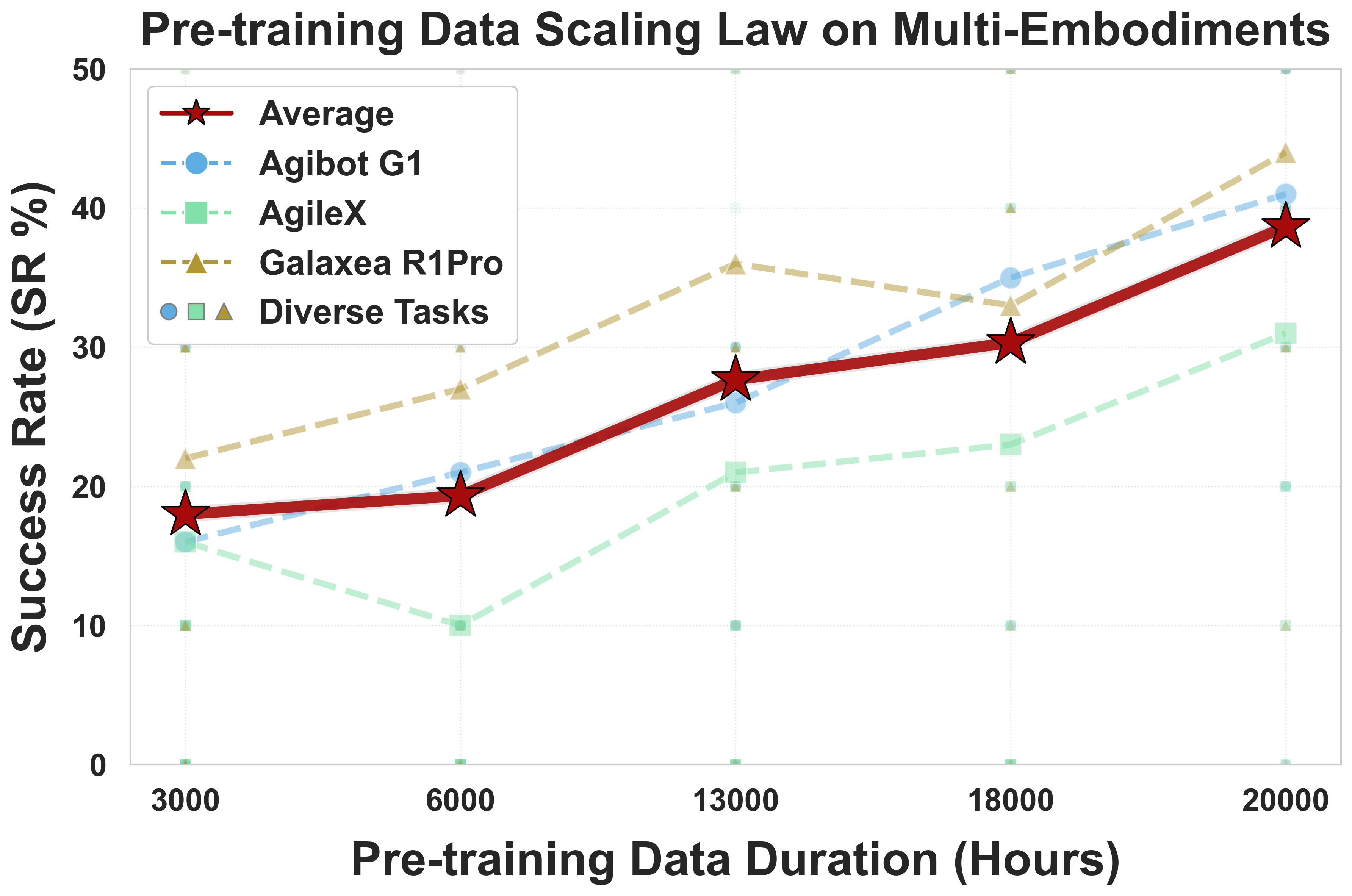
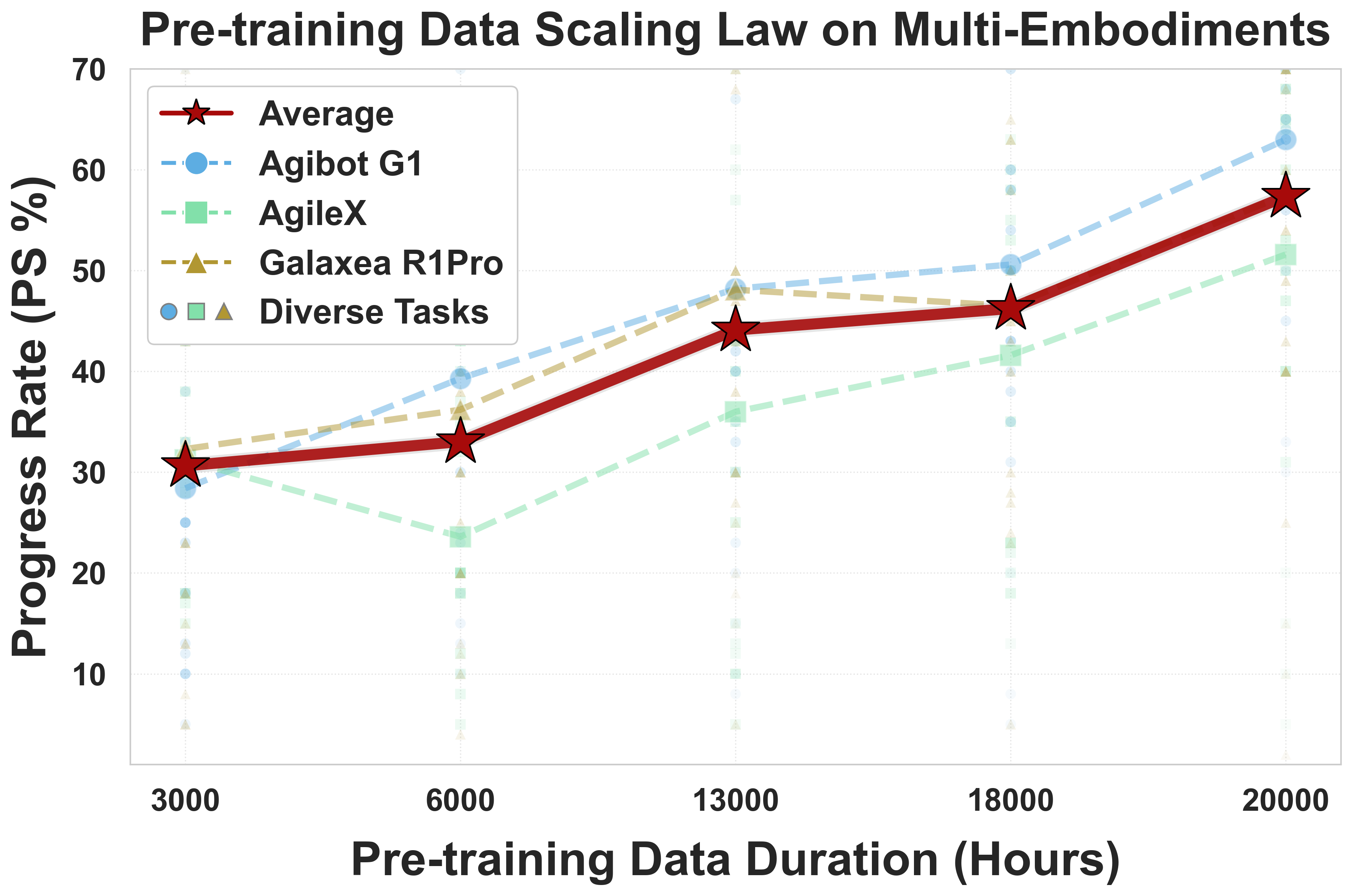
- Strong Performance: Achieves clear superiority over competitors on simulation and real-world benchmarks.
- Training Efficiency: Represents a 1.5 ∼ 2.8× (depending on the relied VLM base model) speedup over existing VLA-oriented codebases.
🚀 News
-
[2026-04-30] Update of Our codebase:
- Add recommended post-training setting with real robot data.
- Upgrade to LeRobot v3.0.
- Support open-loop evaluation.
- Optimize GPU memory usage during training.
- Enable Torch Compile for inference.
-
[2026-01-27] LingBot-VLA Technical Report is available on Arxiv.
-
[2026-01-27] Weights and code released!
🛠️ Installation
Requirements
- Python 3.12.3
- Pytorch 2.8.0
- CUDA 12.8
conda create -n lingbotvla python=3.12 -y
conda activate lingbotvla
git clone https://github.com/Robbyant/lingbot-vla.git
cd lingbot-vla
bash install.sh📦 Model Download
We release LingBot-VLA pre-trained weights in two configurations: depth-free version and a depth-distilled version.
Pretrained Checkpoints for Post-Training with and without depth
| Model Name | Huggingface | ModelScope | Description |
|---|---|---|---|
| LingBot-VLA-4B | 🤗 lingbot-vla-4b | 🤖 lingbot-vla-4b | LingBot-VLA w/o Depth |
| LingBot-VLA-4B-Depth | 🤗 lingbot-vla-4b-depth | 🤖 lingbot-vla-4b-depth | LingBot-VLA w/ Depth |
# Download Pretrained Checkpoints
python3 scripts/download_hf_model.py --repo_id robbyant/lingbot-vla-4b --local_dir lingbot-vla-4b ⚠️ Note for users who downloaded before 2026/05/01 (click to expand)
If you downloaded
LingBot-VLA-4BorLingBot-VLA-4B-Depthbefore 2026/05/01, you may encounter the following error when loading the model:draccus.utils.DecodingError: The fields `resize_imgs_with_padding`, `adapt_to_pi_aloha`, `use_delta_joint_actions_aloha`, `proj_width`, `num_steps`, `use_cache`, `attention_implementation`, `freeze_vision_encoder`, `train_expert_only`, `train_state_proj` are not valid for PI0ConfigThis is caused by our migration from LeRobot v2.1 to v3.0.
To fix this, please re-download the latest checkpoint, or manually remove the above fields fromconfig.jsonin your locallingbot-vla-4b/orlingbot-vla-4b-depth/directory.
To train LingBot with our codebase, weights from Qwen2.5-VL-3B-Instruct, MoGe-2-vitb-normal, and LingBot-Depth are also required.
💻 Post-Training Example
Data Preparation
Post-training requires three preparation steps. For a complete guide on customizing your own dataset, see the Custom Data Guide.
| Step | Description | Output |
|---|---|---|
| 1. Prepare LeRobot Dataset | Convert your demonstration data to LeRobot v3.0 format | LeRobot dataset directory |
| 2. Prepare Robot Config | Define feature mapping (states / actions / images) from raw keys to unified feature space | configs/robot_configs/<data_name>.yaml |
| 3. Compute Norm Statistics | Calculate normalization statistics over your dataset | assets/norm_stats/<name>.json |
Note: If you already have data in LeRobot v2.1 format, you can use convert_dataset_v21_to_v30.py to quickly convert it to v3.0.
Below we use RoboTwin 2.0 (5 tasks: "open_microwave", "click_bell", "stack_blocks_three", "place_shoe", "put_object_cabinet") as an example.
- Step 1 — RoboTwin Data: Follow RoboTwin2.0 Preparation to download and convert.
- Step 2 — Robot Config: See
configs/robot_configs/robotwin.yamlfor the RoboTwin feature mapping. - Step 3 — Normalization: Pre-computed stats are provided at
assets/norm_stats/robotwin_50.json. To recompute for a custom task subset, see the Custom Data Guide.
Training
We provide a post-training example of LingBot-VLA on 5 RoboTwin 2.0 tasks ("open_microwave", "click_bell", "stack_blocks_three", "place_shoe", "put_object_cabinet"):
# without depth
bash train.sh tasks/vla/train_lingbotvla.py ./configs/vla/robotwin_load20000h.yaml \
--data.train_path /path/to/mixed_robotwin_5tasks \
--data.data_name robotwin \
--data.norm_stats_file assets/norm_stats/robotwin_50.json \
--train.output_dir output/
# with depth
bash train.sh tasks/vla/train_lingbotvla.py ./configs/vla/robotwin_load20000h_depth.yaml \
--data.train_path /path/to/mixed_robotwin_5tasks \
--data.data_name robotwin \
--data.norm_stats_file assets/norm_stats/robotwin_50.json \
--train.output_dir output/🤖 Real-Robot Post-Training
Also, we provide recommended training configurations specifically tailored for real-world scenarios: real_load20000h.yaml (w/o depth) and real_load20000h_depth.yaml (w/ depth). For a detailed explanation of all training configuration parameters (batch size, gradient accumulation, training duration, checkpointing, depth injection, etc.), see the Training Configuration Guide.
Evaluation
Open-Loop Eval
export QWEN25_PATH=Qwen/Qwen2.5-VL-3B-Instruct
python scripts/open_loop_eval.py --model_path path_to_posttraining_ckpt --data_path path_to_validation_data --use_length 50
# If `--data_path` is omitted, the script defaults to the training dataset specified in the YAML config (`data.train_path`).Note:
For inference, the model path (path_to_posttraining_ckpt, located intrain.output_dir/checkpoints/*/hf_ckpt) must include:
- weights in
.safetensorsformatconfig.jsonlingbotvla_cli.yaml
Robotwin
export QWEN25_PATH=path_to_Qwen2.5-VL-3B-Instruct
python -m deploy.lingbot_vla_policy \
--model_path path_to_posttraining_ckpt \
--use_compile \
--use_length 50 \
--port portReal-Robot Deployment
export QWEN25_PATH=path_to_Qwen2.5-VL-3B-Instruct
python -m deploy.lingbot_vla_policy \
--model_path path_to_posttraining_ckpt \
--use_compile \
--use_length 25
# You can set --num_denoising_step to 5 if you want to speed up the evaluation.🏗️ Efficiency
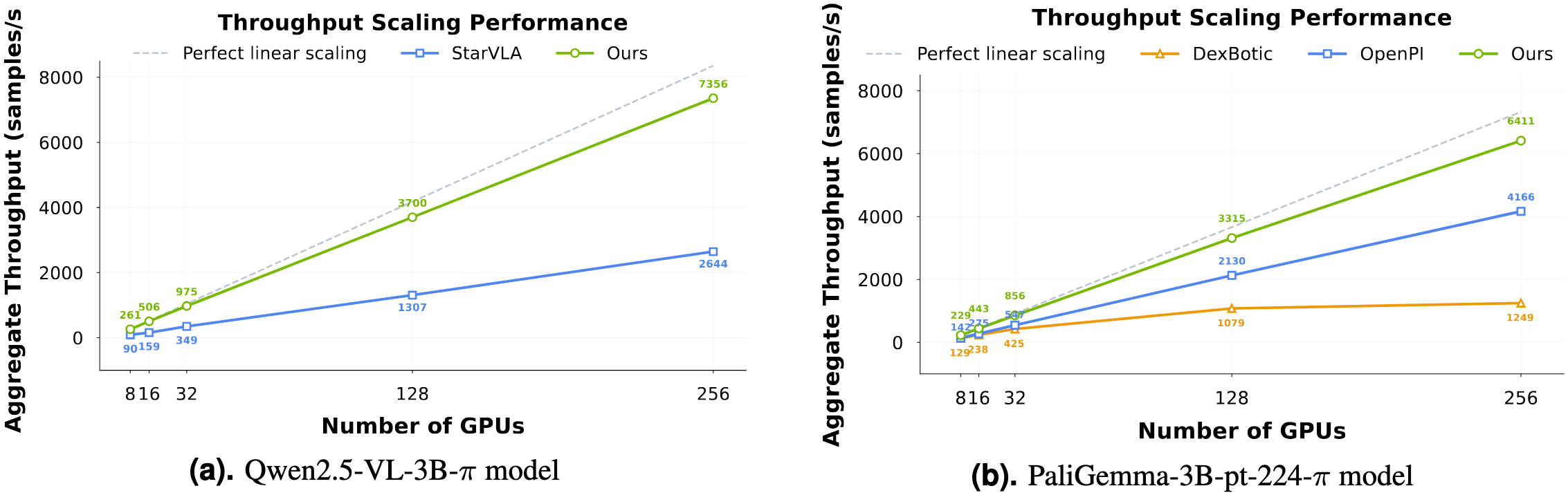
📢 Note on Throughput Metrics: All throughput values (e.g., 261 samples/sec) represent the total aggregate throughput across all GPUs, not per-GPU performance.
(Updated: Previously mislabeled as per-GPU in earlier versions. We apologize for the confusion.)
📊 Performance
Our LingBot-VLA achieves state-of-the-art results on real-world and simulation benchmarks:
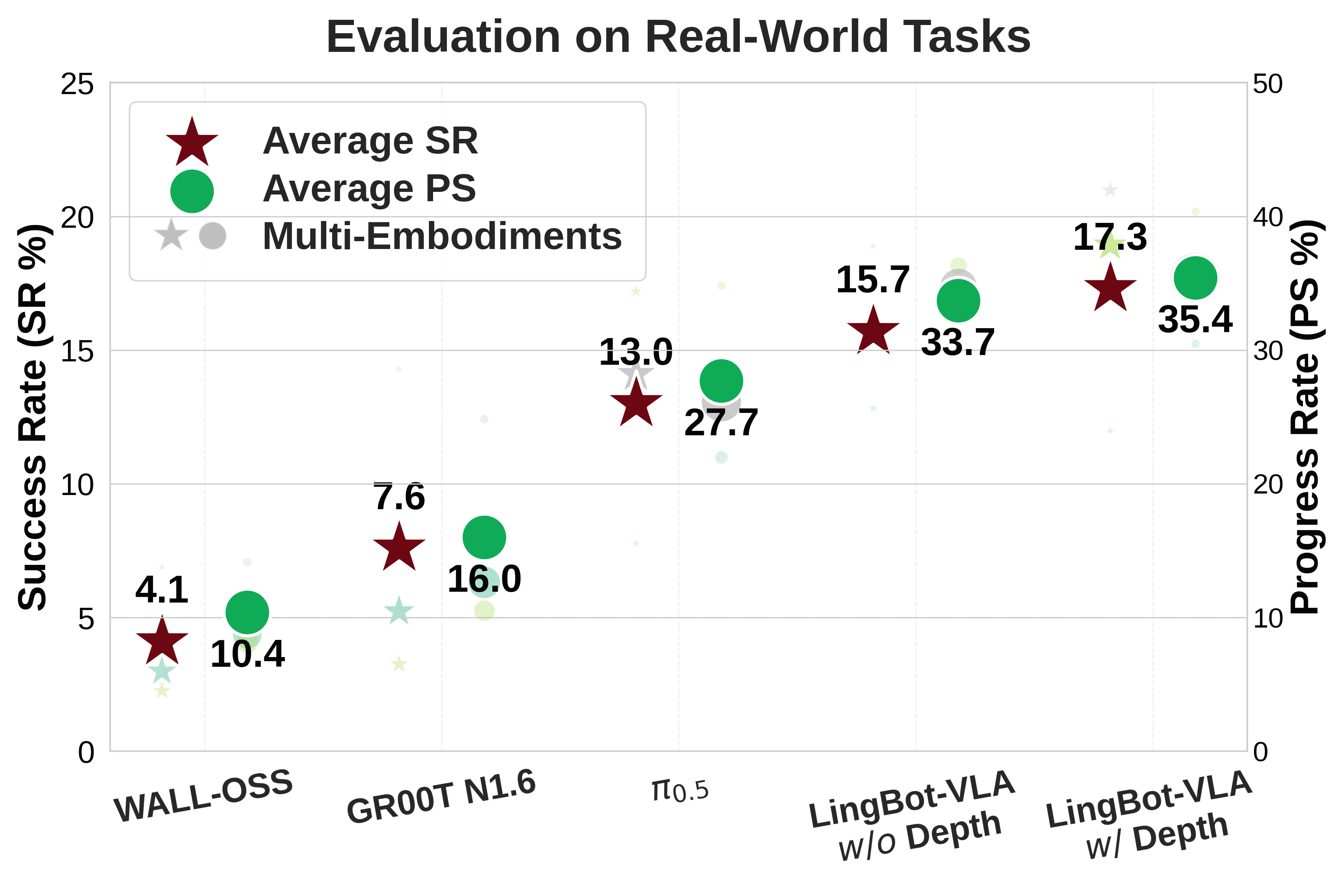
- GM-100 across 3 robot platforms
| Platform | WALL-OSS | GR00T N1.6 | π0.5 | Ours w/o depth | Ours w/ depth | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| SR | PS | SR | PS | SR | PS | SR | PS | SR | PS | |
| Agibot G1 | 2.99% | 8.75% | 5.23% | 12.63% | 7.77% | 21.98% | 12.82% | 30.04% | 11.98% | 30.47% |
| AgileX | 2.26% | 8.16% | 3.26% | 10.52% | 17.20% | 34.82% | 15.50% | 36.31% | 18.93% | 40.36% |
| Galaxea R1Pro | 6.89% | 14.13% | 14.29% | 24.83% | 14.10% | 26.14% | 18.89% | 34.71% | 20.98% | 35.40% |
| Average | 4.05% | 10.35% | 7.59% | 15.99% | 13.02% | 27.65% | 15.74% | 33.69% | 17.30% | 35.41% |
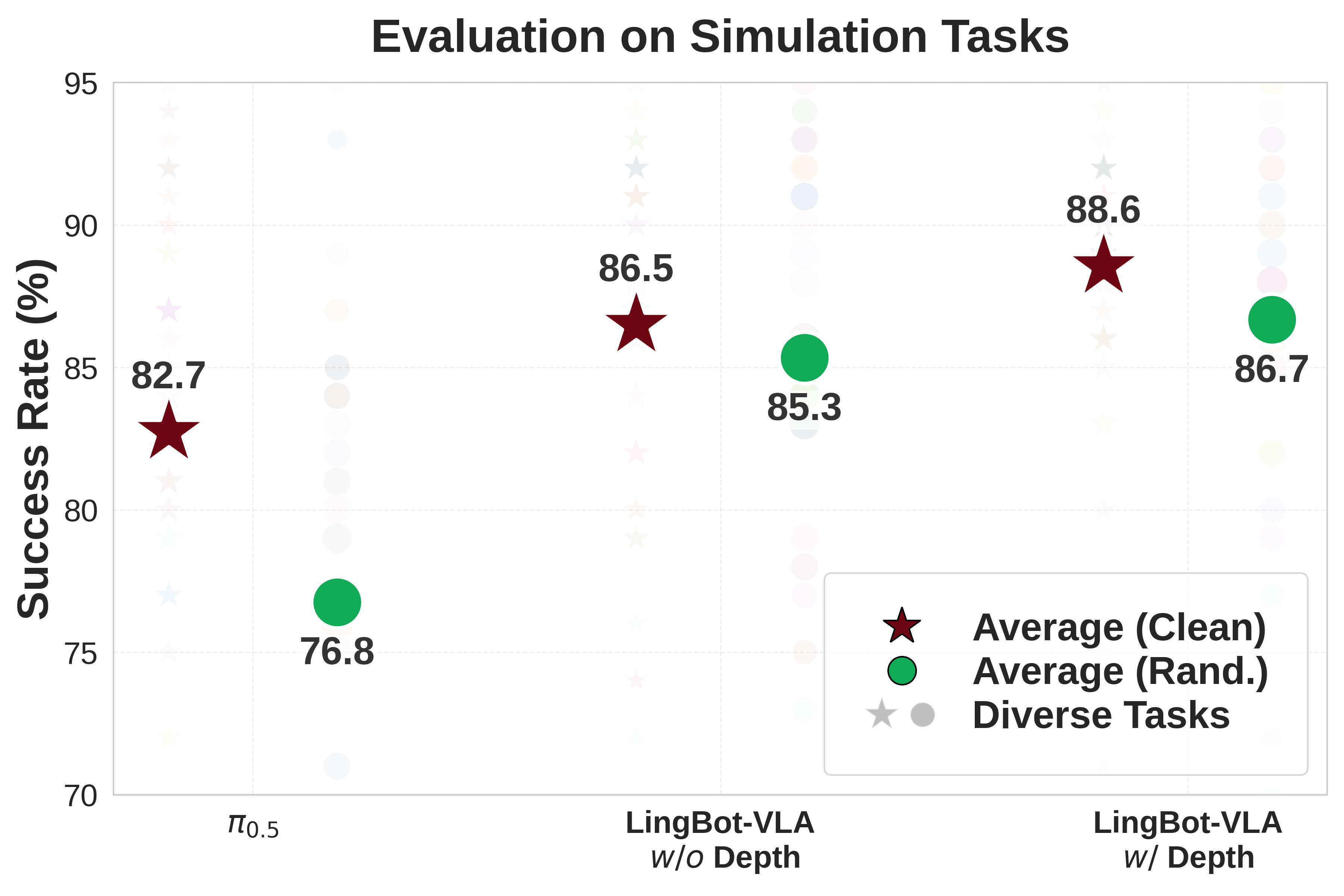
- RoboTwin 2.0 (Clean and Randomized)
| Simulation Tasks | π0.5 | Ours w/o depth | Ours w/ depth | |||
|---|---|---|---|---|---|---|
| Clean | Rand. | Clean | Rand. | Clean | Rand. | |
| Average SR | 82.74% | 76.76% | 86.50% | 85.34% | 88.56% | 86.68% |
📢 We have released our checkpoints of LingBot-VLA-Posttrain-Robotwin:
| Model Name | Huggingface | ModelScope | Description |
|---|---|---|---|
| LingBot-VLA-4B-Posttrain-Robotwin | 🤗 lingbot-vla-4b-posttrain-robotwin | 🤖 lingbot-vla-4b-posttrain-robotwin | LingBot-VLA-Posttrain-Robotwin w/o Depth |
| LingBot-VLA-4B-Depth-Posttrain-Robotwin | 🤗 lingbot-vla-4b-depth-posttrain-robotwin | 🤖 lingbot-vla-4b-depth-posttrain-robotwin | LingBot-VLA-Posttrain-Robotwin w/ Depth |
⚠️ Note for users who downloaded before 2026/05/01 (click to expand)
If you downloaded
lingbot-vla-4b-posttrain-robotwinorlingbot-vla-4b-depth-posttrain-robotwinbefore 2026/05/01, you may encounter the following error when loading the model:draccus.utils.DecodingError: The fields `resize_imgs_with_padding`, `adapt_to_pi_aloha`, `use_delta_joint_actions_aloha`, `proj_width`, `num_steps`, `use_cache`, `attention_implementation`, `freeze_vision_encoder`, `train_expert_only`, `train_state_proj` are not valid for PI0ConfigTo fix this, please re-download the latest checkpoint, or manually remove the above fields from
config.jsonand add them to thetrainsection oflingbotvla_cli.yamlin your local directory.
📝 Citation
If you find our work useful in your research, feel free to give us a cite.
@article{wu2026pragmatic,
title={A Pragmatic VLA Foundation Model},
author={Wei Wu and Fan Lu and Yunnan Wang and Shuai Yang and Shi Liu and Fangjing Wang and Shuailei Ma and He Sun and Yong Wang and Zhenqi Qiu and Houlong Xiong and Ziyu Wang and Shuai Zhou and Yiyu Ren and Kejia Zhang and Hui Yu and Jingmei Zhao and Qian Zhu and Ran Cheng and Yong-Lu Li and Yongtao Huang and Xing Zhu and Yujun Shen and Kecheng Zheng},
journal={arXiv preprint arXiv:2601.18692v1},
year={2026}
}📄 License Agreement
This project is licensed under the Apache-2.0 License.
😊 Acknowledgement
We would like to express our sincere gratitude to the developers of VeOmni, LeRobot, and Baidu Cloud for their technical support. This project benefits significantly from their outstanding work and contributions. Baidu Cloud's optimization solutions notably reduced our GPU memory consumption by 29.2% during model training.