Consistency in Diffusion-Based Visual Generation: A Survey



![]()
![]()
![]()
Overview · Taxonomy · Evaluation & Optimization · Resources · Data Files · Contribute · Citation
Overview
This repository accompanies the survey:
Consistency in Diffusion-Based Visual Generation: A Survey
Song Yan, Wei Zhai, Chenfeng Wang, Ruixuan Li, Zhangping Yang, Yancheng Cai, Tao Zhang, Ling Wang, Yunwei Lan, Yujie He, Yang Cao, Min Li, and Zheng-Jun Zha.
Preprints, 2026 · Paper · DOI
Diffusion models now support text-to-image synthesis, editing, personalization, video generation, and 3D-aware content creation. Visual fidelity alone, however, does not guarantee that an output follows its prompt, preserves identity, remains coherent over time or viewpoint, or satisfies safety and physical-plausibility requirements.
The survey organizes these failures through a single question:
What should a generated visual output agree with?
Its answer is a relation-based taxonomy of external, internal, and normative consistency. The repository turns this taxonomy into a navigable literature map covering representative methods, benchmarks, evaluators, datasets, and diagnostic resources.
Key contributions
- Relation-based taxonomy — organizes consistency according to the target of agreement rather than only by task or modality.
- Evaluation protocol abstraction — separates observation units, agreement targets, evidence sources, and evaluation outputs.
- Optimization-locus analysis — compares where consistency is imposed: before sampling, at the condition interface, during denoising, across coupled outputs, or after generation.
- Machine-readable resource map — provides structured CSV and BibTeX files for maintenance, comparison, and downstream analysis.
Taxonomy
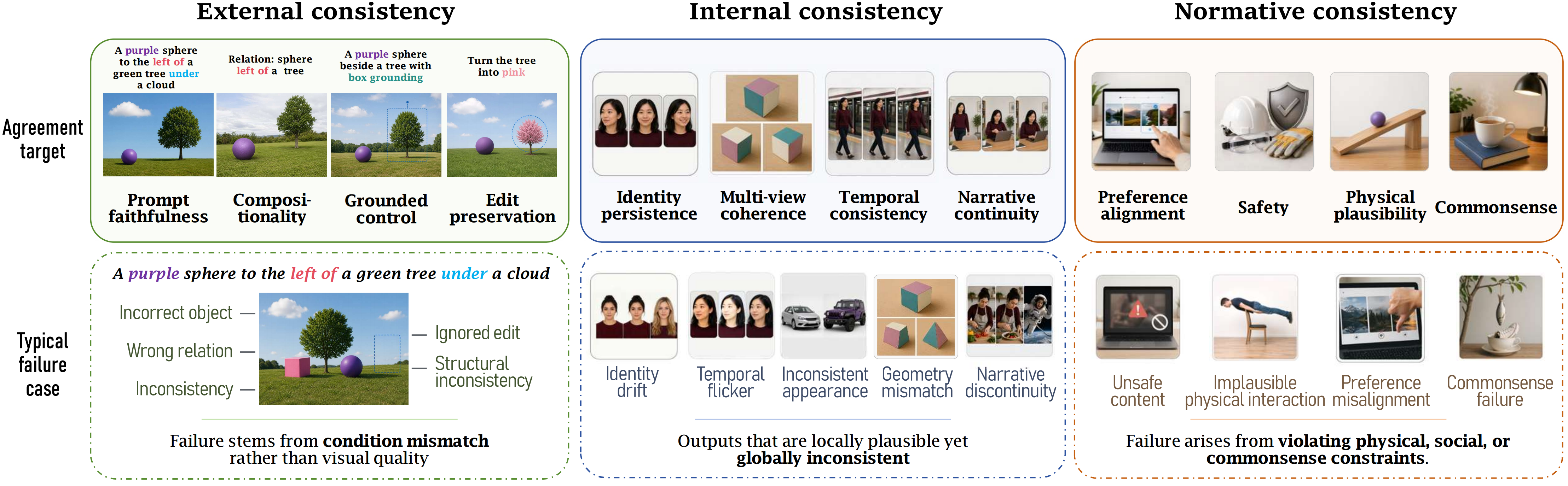
Figure 1. Three consistency relations in diffusion-based visual generation.
| Relation | Agreement target | Representative failures | Typical settings | Resources |
|---|---|---|---|---|
| External consistency | Prompts, references, layouts, masks, poses, controls, and editing instructions | Prompt omission, attribute-binding error, counting error, control mismatch, over-editing | Text-to-image generation, structural control, editing, inpainting, virtual try-on, typography | 125 |
| Internal consistency | Generated subjects, views, frames, shots, instances, and story states | Identity drift, view inconsistency, temporal flicker, state forgetting, narrative discontinuity | Personalization, multi-view/3D generation, video generation, story visualization | 123 |
| Normative consistency | Preference, safety, fairness, physical plausibility, commonsense, and causal/world-state criteria | Low preference, unsafe output, benign-capability loss, physical violation, causal failure | Preference optimization, safety editing, concept erasure, physical and world-model evaluation | 107 |
The categories are conceptually distinct but practically entangled. A method may address several relations simultaneously; the repository places it according to its primary agreement target while retaining its broader diagnostic role in the description and coverage files.
Evaluation and optimization
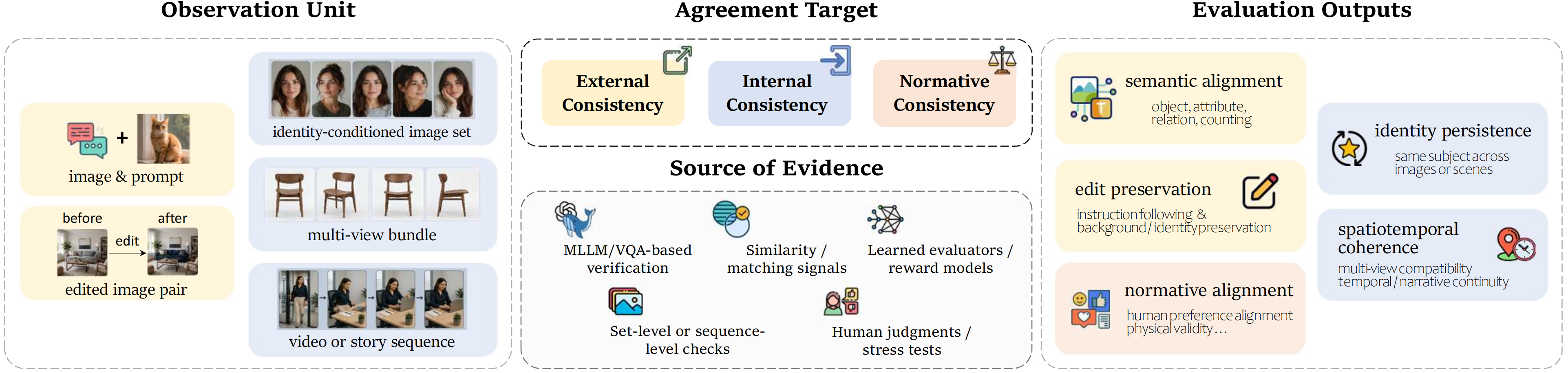
|
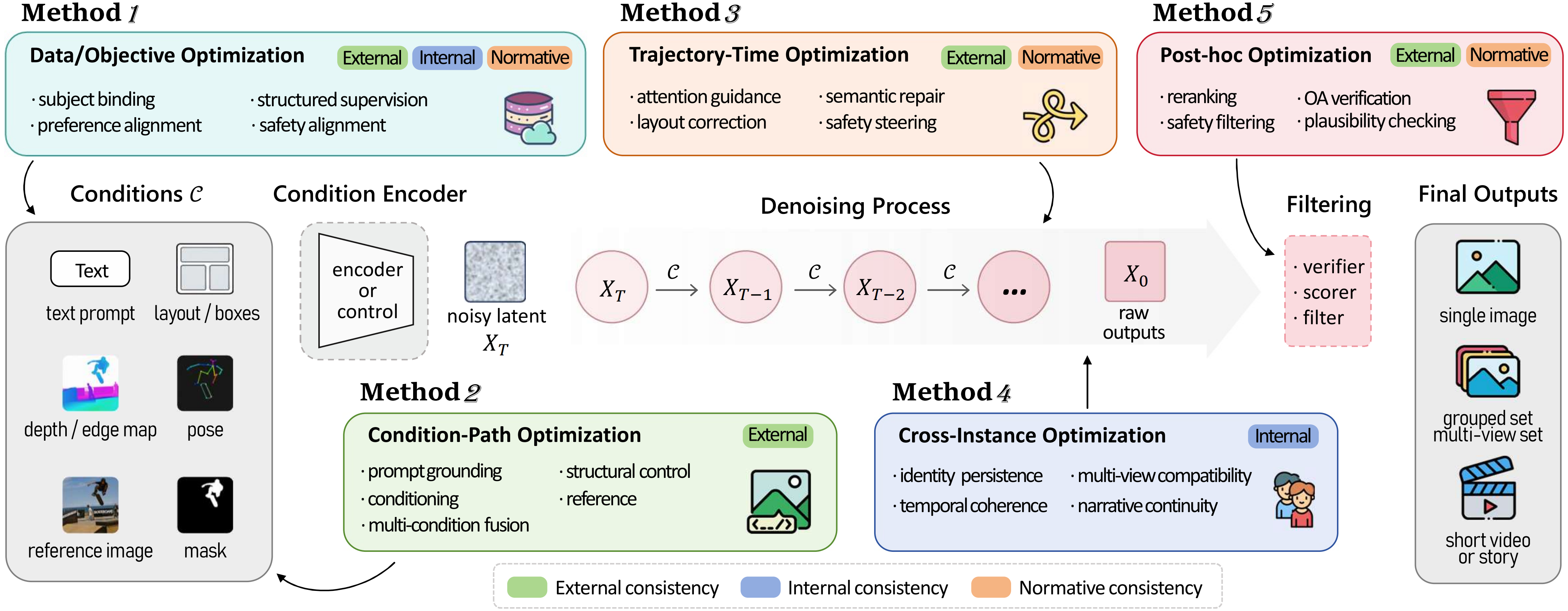
|
| Evaluation view. A consistency claim should specify the observation unit, agreement target, evidence source, and evaluation output. This prevents sequence-level claims from being supported only by frame-level evidence, or specific alignment claims from being reduced to broad preference scores. | Optimization view. Consistency can be imposed before sampling, at the condition interface, during denoising, across coupled outputs, or after generation. Each locus creates different trade-offs among persistence, controllability, realism, diversity, memory cost, and modularity. |
Resource collection
The collection is designed as a topic-oriented literature map, not a flat bibliography. Resources are first grouped by their primary consistency relation and then divided into focused research themes. All lists are fully expanded to support browser search, direct linking, and rapid visual scanning.
| Consistency relation | Methods | Benchmarks & Evaluators | Datasets & Data | Total | Browse |
|---|---|---|---|---|---|
| External consistency | 85 | 20 | 20 | 125 | Open section |
| Internal consistency | 83 | 20 | 20 | 123 | Open section |
| Normative consistency | 57 | 30 | 20 | 107 | Open section |
| Collection | 225 | 70 | 60 | 355 | — |
Entry format
Each resource is presented with a prominent title, compact venue/year metadata, and a separate one-line description:
- Resource title venue / year
The consistency issue, mechanism, or diagnostic role addressed by the resource.
[!NOTE] Recent papers may temporarily be labeled arXiv, project, or venue TBD until stable proceedings metadata becomes available. Official paper repositories and project pages are preferred over unofficial reimplementations.
01 · External consistency
Agreement target — Agreement with externally specified conditions.
Scope — Prompts, layouts, boxes, masks, depth maps, poses, reference images, editing instructions, and other user- or task-provided controls.
| Resource type | Description | Jump |
|---|---|---|
| Methods | Architectures, objectives, inference procedures, and intervention mechanisms. | Browse 85 |
| Benchmarks & Evaluators | Test suites, metrics, learned scorers, and evaluation protocols. | Browse 20 |
| Datasets & Data Resources | Training corpora, annotations, prompt sets, and diagnostic data. | Browse 20 |
Methods
85 resources organized into 6 focused topics.
Prompt following & compositional generation 20
Foundational text-conditioned models, semantic binding, prompt planning, and prompt refinement.
- GLIDE arXiv 2022
Early text-guided diffusion model supporting prompt-conditioned generation and editing. - Imagen NeurIPS 2022 / arXiv
High-fidelity text-to-image diffusion model emphasizing language understanding. - Latent Diffusion Models CVPR 2022
Latent-space diffusion backbone widely used for controllable generation and editing. - Composable Diffusion Models ECCV 2022
Combines multiple diffusion score functions for compositional generation. - Structured Diffusion Guidance arXiv 2022
Uses structured guidance signals to improve prompt-object alignment. (same work as StructureDiffusion) - StructureDiffusion arXiv 2022
Parses prompts into structured representations to improve compositional text-to-image generation. - Attend-and-Excite SIGGRAPH 2023
Manipulates cross-attention maps to reduce missing objects and improve prompt coverage Paper - BoxDiff ICCV 2023
Training-free box-constrained generation for spatially grounded text-to-image synthesis Paper - Composer ICML 2023
Composes heterogeneous visual conditions for controllable image synthesis Paper - MultiDiffusion ICML 2023
Fuses multiple diffusion paths to satisfy spatial and regional generation constraints. - LLM-grounded Diffusion ICLR 2024
Uses LLM planning to turn complex prompts into layout-grounded generation constraints. - SynGen ICCV 2023
Uses syntactic guidance to improve compositional text-to-image generation. - RPG: Recaption, Plan, and Generate arXiv 2024
Uses MLLM-based recaptioning and planning for complex prompt following Paper - CONFORM arXiv / venue TBD
Improves object-attribute alignment through contrastive or correspondence-driven prompt grounding. - Divide-and-Bind arXiv / venue TBD
Decomposes complex prompts and binds objects to attributes or relations. - Linguistic Binding in Diffusion arXiv / venue TBD
Studies or improves language-binding failures in text-to-image diffusion. - Promptist arXiv 2022
Optimizes prompts to improve text-to-image generation quality and alignment. - BeautifulPrompt AAAI 2024 / arXiv
Refines user prompts for stronger image generation quality and faithfulness. - Prompt Expansion for Text-to-Image topic / resource
Expands underspecified prompts to reduce ambiguity in generation. - Prompt Decomposition for T2I topic / resource
Decomposes prompts into atomic semantic constraints for evaluation or guidance.
Spatial grounding & structural control 24
Boxes, layouts, adapters, scene graphs, masks, poses, and other explicit control interfaces.
- ControlNet ICCV 2023
Adds trainable side branches for depth, edge, pose, segmentation, and other controls Paper - GLIGEN CVPR 2023
Grounds generation with boxes and phrase-level grounding tokens Paper - T2I-Adapter AAAI 2024
Uses lightweight adapters for structural conditions such as sketch, depth, and pose Paper - IP-Adapter arXiv 2023
Adds image-prompt conditioning while preserving text compatibility Paper - AnyDoor CVPR 2024
Performs zero-shot object-level customization and insertion Paper - FreeDoM ICCV 2023
Applies training-free energy guidance for conditional diffusion tasks Paper - HumanSD ICCV 2023
Generates human images under native skeleton guidance Paper - UniControl NeurIPS 2023 / arXiv
Provides a unified framework for multiple controllable generation signals. - Uni-ControlNet arXiv 2023
Unifies multi-condition ControlNet-style conditioning. - Ctrl-Adapter ICLR 2025
Uses efficient adapters for diverse spatial and structural controls. - UniCon ICLR 2025
Designs unidirectional information flow for stronger large-scale condition control. - InstanceDiffusion CVPR 2024
Supports instance-level control over object placement and attributes. - ControlNet++ arXiv / venue TBD
Improves ControlNet-style conditioning quality and efficiency. - ControlNet-XS arXiv / venue TBD
Compresses controllable generation modules for efficient deployment. - ControlLoRA arXiv / venue TBD
Uses LoRA-style lightweight control adaptation. - SparseCtrl arXiv / venue TBD
Controls image/video generation from sparse visual conditions. - SemanticControl arXiv / venue TBD
Handles loose or weakly aligned semantic controls. - LayoutDiffusion CVPR 2023 / arXiv
Conditions diffusion generation on layout annotations. - LayoutDM CVPR 2023 / arXiv
Models layout-to-image synthesis through diffusion. - SceneComposer arXiv / venue TBD
Composes scene-level controls for complex generation. - Scene Graph Diffusion arXiv / venue TBD
Uses scene graphs for relation-aware image synthesis. - DetDiffusion arXiv / venue TBD
Integrates detection-like constraints into image generation. - Grounded Diffusion topic / resource
General family of grounding-based diffusion methods. - SAM-guided Diffusion Editing topic / resource
Uses segmentation masks to localize editing constraints.
Guidance, inversion & image editing 26
Sampling-time guidance, inversion, instruction editing, drag editing, and localized inpainting.
- Diffusion Posterior Sampling ICLR 2023
Uses measurement likelihoods to guide inverse-problem diffusion. - Universal Guidance for Diffusion Models ICML 2023 Workshop
Applies generic guidance losses during sampling. - Classifier Guidance NeurIPS 2021
Uses classifier gradients to steer diffusion samples. - Classifier-Free Guidance NeurIPS 2021 workshop / arXiv
Steers conditional generation without an external classifier. - SDEdit ICLR 2022
Edits images by adding noise and denoising under new guidance. - Prompt-to-Prompt ICLR 2023
Controls cross-attention to edit prompts while preserving layout/content Paper - Null-Text Inversion CVPR 2023
Inverts real images for more faithful prompt-based editing. - DiffEdit ICLR 2023
Computes semantic edit masks from prompt differences Paper - InstructPix2Pix CVPR 2023
Trains a diffusion editor to follow natural-language instructions Paper - InstructDiffusion CVPR 2024
Unifies several visual instruction tasks in diffusion models Paper - Imagic CVPR 2023
Edits real images by optimizing text embeddings and model weights. - Paint-by-Example CVPR 2023
Uses exemplar images to guide localized editing Paper - Plug-and-Play Diffusion Features CVPR 2023
Injects diffusion features to preserve structure during editing. - Pix2Pix-Zero ICCV 2023
Performs zero-shot image-to-image translation through cross-attention guidance. - MasaCtrl ICCV 2023
Uses mutual self-attention to preserve structure across synthesis/editing Paper - LEDITS++ arXiv 2023
Performs lightweight semantic editing and concept erasure. - DragonDiffusion ICLR 2024 / arXiv
Supports object moving, resizing, and fine-grained interactive editing Paper - DragDiffusion CVPR 2024
Enables point-based drag editing with diffusion priors Paper - FreeDrag CVPR 2024 / arXiv
Improves drag editing without model finetuning. - DiffEditor arXiv / venue TBD
Provides an editing pipeline for localized diffusion modifications. - SEGA arXiv 2023
Steers semantic directions during diffusion sampling. - Emu Edit CVPR 2024 / arXiv
Uses instruction data for high-quality image editing. - SmartEdit CVPR 2024 / arXiv
Combines MLLMs and diffusion for instruction-based editing. - BrushNet ECCV 2024 / arXiv
Adds a dedicated inpainting branch for masked image editing. - PowerPaint ECCV 2024 / arXiv
Supports versatile object removal, insertion, and inpainting. - Inpaint Anything arXiv 2023
Combines segmentation and diffusion inpainting.
Typography & visual text 5
Text rendering, multilingual typography, glyph conditioning, and text-aware editing.
- TextDiffuser NeurIPS 2023
Improves text rendering inside generated images. - TextDiffuser-2 arXiv 2023
Improves multilingual and layout-aware text rendering. - AnyText ICLR 2024
Generates and edits multilingual text in images. - GlyphDraw NeurIPS 2023 / arXiv
Uses glyph-level information for visual text generation. - GlyphControl arXiv / venue TBD
Adds explicit glyph constraints for controllable typography.
Virtual try-on & dressing 7
Garment preservation, person–garment alignment, and generalized dressing constraints.
- TryOnDiffusion CVPR 2023
Uses diffusion for virtual try-on with garment-person consistency. - StableVITON CVPR 2024
Adapts stable diffusion to virtual try-on Paper - IDM-VTON ECCV 2024
Improves image-based virtual try-on with diffusion Paper - CatVTON arXiv 2024
Provides a lightweight virtual try-on framework Paper - OOTDiffusion arXiv 2024
Generates outfits and try-on images under reference constraints Paper - LaDI-VTON ACM MM 2023 / arXiv
Uses latent diffusion for virtual try-on. - AnyDressing arXiv / venue TBD
Handles generalized dressing and garment transfer constraints.
Posters & graphic design 3
Layout-aware poster generation and structured graphic composition.
- PosterCraft arXiv / venue TBD
Studies layout- and text-aware poster generation. - CreatiPoster arXiv / venue TBD
Generates visually structured poster layouts. - PosterMaker arXiv / venue TBD
Uses diffusion for controllable poster design.
Benchmarks & Evaluators
20 resources organized into 4 focused topics.
| Topic | Coverage |
|---|---|
| General prompt fidelity & composition | 11 |
| Editing & learned-concept evaluation | 2 |
| Fine-grained semantic diagnostics | 5 |
| Domain-specific control evaluation | 2 |
General prompt fidelity & composition 11
Broad prompt-following, semantic alignment, and compositional evaluation protocols.
- TIFA ICCV 2023
Evaluates prompt faithfulness using generated question-answer pairs. - GenEval NeurIPS 2023 workshop / arXiv
Tests object presence, counting, colors, positions, and attribute binding. - T2I-CompBench NeurIPS 2023
Measures compositional alignment across attributes, relations, and complex prompts. - GenEval2 arXiv / venue TBD
Extends prompt-following evaluation with harder and less saturated cases. - HRS-Bench ICCV 2023
Provides holistic evaluation of T2I capabilities, robustness, fairness, and bias. Paper - DPG-Bench arXiv 2024
Uses dense prompts to evaluate semantic and relation following. - GenAI-Bench / VQAScore ECCV 2024
Evaluates text-to-visual generation through VQA-style image/video scoring. - DrawBench Imagen / NeurIPS 2022 resource
Human-evaluation prompt suite for text-to-image generation. - PartiPrompts arXiv 2022
Large prompt set for evaluating compositional and high-level prompt following. - DSG: Davidsonian Scene Graph evaluation arXiv / venue TBD
Converts prompts to scene-graph-like checks for semantic consistency. - VIEScore arXiv / venue TBD
Uses vision-language evaluators for image-text alignment.
Back to benchmarks & evaluators ↑
Editing & learned-concept evaluation 2
Evaluation of edit preservation, instruction compliance, and reusable concept learning.
- EditBench CVPR 2023
Benchmarks text-guided image inpainting and edit preservation. - ConceptBed arXiv / venue TBD
Evaluates concept learning and reusable concept binding.
Back to benchmarks & evaluators ↑
Fine-grained semantic diagnostics 5
Targeted tests for counting, spatial relations, attribute binding, relations, and typography.
- CountBench resource / venue TBD
Tests numerical object-counting consistency in generated images. - SpatialBench resource / venue TBD
Tests spatial relation following. - ObjectAttributeBench resource / venue TBD
Tests object-attribute binding. - RelationBench resource / venue TBD
Tests relational semantics in text-to-image generation. - TypographyBench resource / venue TBD
Evaluates rendered text accuracy in generated images.
Back to benchmarks & evaluators ↑
Domain-specific control evaluation 2
Specialized protocols for virtual try-on and pose-conditioned generation.
- VTON evaluation suites resource
Evaluate garment preservation and person-garment alignment. - Human pose generation evaluation resource
Evaluates pose-conditioned human generation.
Back to benchmarks & evaluators ↑
Datasets & Data Resources
20 resources organized into 5 focused topics.
| Topic | Coverage |
|---|---|
| Instruction-guided editing | 2 |
| Captioning, grounding & compositional reasoning | 7 |
| Web-scale image–text pretraining | 4 |
| Segmentation & object-level control | 2 |
| Fashion, pose & typography | 5 |
Instruction-guided editing 2
Data for natural-language image editing and multi-turn edit supervision.
- MagicBrush NeurIPS 2023 Datasets and Benchmarks
Instruction-guided image editing dataset with multi-turn annotations. - InstructPix2Pix dataset CVPR 2023 resource
Synthetic instruction-edit pairs for image editing Paper
Back to datasets & data resources ↑
Captioning, grounding & compositional reasoning 7
Caption, region, relation, referring-expression, VQA, and synthetic reasoning annotations.
- COCO Captions ECCV 2014 / dataset
Common image-caption source for prompt grounding. - Visual Genome IJCV 2017 / dataset
Dense object, attribute, and relation annotations. - OpenImages dataset
Large-scale object and visual relationship annotations. - ADE20K CVPR 2017 / dataset
Scene parsing annotations for structural control. - RefCOCO dataset
Referring-expression grounding resource. - GQA CVPR 2019 / dataset
Visual-question-answering resource for compositional reasoning. - CLEVR CVPR 2017 / dataset
Synthetic compositional reasoning dataset.
Back to datasets & data resources ↑
Web-scale image–text pretraining 4
Large image–text corpora and aesthetic-filtered pretraining resources.
- LAION-5B NeurIPS 2022 Datasets and Benchmarks
Web-scale image-text pretraining data. - LAION-Aesthetics dataset resource
Aesthetic-filtered image-text data. - CC3M ACL 2018 / dataset
Web image-caption data for vision-language pretraining. - CC12M CVPR 2021 / dataset
Larger conceptual-caption dataset.
Back to datasets & data resources ↑
Segmentation & object-level control 2
Mask, instance, and long-tail object annotations for localized control.
- SA-1B ICCV 2023 / dataset
Large-scale segmentation masks for editing and control. - LVIS CVPR 2019 / dataset
Long-tail instance annotations for object-level diagnostics.
Back to datasets & data resources ↑
Fashion, pose & typography 5
Domain-specific supervision for dressing, human pose, and visual text generation.
- DeepFashion CVPR 2016 / dataset
Fashion data for virtual try-on and garment consistency. - VITON-HD CVPR 2021 workshop / dataset
High-resolution virtual try-on data. - DressCode CVPR 2022 / dataset
Multi-category virtual try-on dataset. - OpenPose / pose datasets resource
Pose supervision for human-conditioned generation. - OCR/text rendering corpora resource
Text-image data for typography generation.
Back to datasets & data resources ↑
Back to resource index ↑ · Back to top ↑
02 · Internal consistency
Agreement target — Agreement among generated states.
Scope — Subjects, identities, views, frames, shots, scenes, instances, and story states that should remain mutually compatible.
| Resource type | Description | Jump |
|---|---|---|
| Methods | Architectures, objectives, inference procedures, and intervention mechanisms. | Browse 83 |
| Benchmarks & Evaluators | Test suites, metrics, learned scorers, and evaluation protocols. | Browse 20 |
| Datasets & Data Resources | Training corpora, annotations, prompt sets, and diagnostic data. | Browse 20 |
Methods
83 resources organized into 6 focused topics.
Personalized concepts & subject identity 21
Concept inversion, parameter-efficient personalization, and identity-preserving generation.
- Textual Inversion ICLR 2023
Learns new textual tokens for personalized concepts Paper - DreamBooth CVPR 2023
Finetunes T2I models for subject-driven generation. - Custom Diffusion CVPR 2023
Efficiently customizes multiple concepts through parameter-efficient updates Paper - Perfusion SIGGRAPH 2023
Uses key-locking to preserve personalized concept identity. - SVDiff arXiv 2023
Parameter-efficient personalization via singular-vector updates. - P+ arXiv 2023
Expands textual inversion representation capacity. - NeTI arXiv 2023
Uses neural textual inversion for richer concept embedding. - ProSpect SIGGRAPH 2023 / arXiv
Personalizes without heavy finetuning. - DisenBooth arXiv 2023
Disentangles identity and context for personalization. - SuTI arXiv 2023
Scalable subject-driven text-to-image personalization. - BLIP-Diffusion NeurIPS 2023
Uses pretrained subject representations for controllable subject generation Paper - ELITE ICCV 2023
Encodes visual concepts into textual embeddings for fast personalization Paper - FastComposer NeurIPS 2023
Enables tuning-free multi-subject generation Paper - Subject-Diffusion ICCV 2023
Supports open-domain personalized subject generation Paper - PhotoMaker CVPR 2024
Uses stacked ID embeddings for realistic human personalization Paper - InstantID arXiv 2024
Provides zero-shot identity-preserving generation Paper - IP-Adapter-FaceID arXiv 2023/2024
Preserves face identity through image-prompt adapters Paper - PuLID arXiv 2024
Supports pure and lightning ID customization Paper - InfiniteYou arXiv / venue TBD
Explores scalable identity-consistent personalization. - RealCustom arXiv / venue TBD
Focuses on realistic personalized concept generation. - InstantCharacter arXiv / venue TBD
Builds fast character-consistent generation.
Characters, style & cross-instance consistency 11
Consistent characters, shared style, stories, and repeated identity across generated sets.
- ConsiStory arXiv 2024
Training-free consistent character generation across images Paper - StoryDiffusion NeurIPS 2024
Uses consistent self-attention for long-range image/video generation Paper - StyleAligned SIGGRAPH 2024
Shares attention to preserve style across generated sets. - The Chosen One SIGGRAPH Asia 2024
Generates consistent characters across text-to-image outputs. - ConsistentID arXiv 2024
Preserves identity in portrait and character generation. - CharaConsist arXiv / venue TBD
Studies fine-grained character consistency. - MagicID arXiv / venue TBD
Provides ID-conditioned video customization. - PersonalVideo arXiv / venue TBD
Customizes video generation with personalized identity. - Phantom arXiv / venue TBD
Explores subject-consistent video generation. - Preserve and Personalize ICLR 2026
Preserves distributional behavior while personalizing concepts. - ConceptPrism CVPR 2026 / project
Disentangles concepts for personalized diffusion.
Multi-view & 3D consistency 17
Novel-view synthesis, synchronized multi-view diffusion, and image-to-3D reconstruction.
- Zero-1-to-3 ICCV 2023
Generates novel views from one image Paper - One-2-3-45 arXiv 2023
Produces multi-view images and 3D assets from a single image Paper - Zero123++ arXiv 2023
Improves single-image novel-view generation. - Cascade-Zero123 arXiv 2023
Cascades view generation for stronger 3D consistency Paper - Consistent123 arXiv 2023
Encourages cross-view consistency in novel-view synthesis. - SyncDreamer ICLR 2024
Synchronizes multi-view diffusion generation Paper - MVDream ICLR 2024
Generates multi-view images with 3D-aware diffusion Paper - Wonder3D CVPR 2024
Reconstructs 3D assets from single images through multi-view diffusion Paper - ViewDiff CVPR 2024
Enforces 3D consistency for text-to-image multi-view generation. - EscherNet CVPR 2024
Performs scalable view synthesis under camera changes. - DreamGaussian ICLR 2024
Uses 3D Gaussians for fast text/image-to-3D generation Paper - LGM ECCV 2024
Reconstructs 3D Gaussians from sparse or generated views Paper - GRM ECCV 2024
Builds large Gaussian reconstruction models. - Instant3D arXiv / venue TBD
Accelerates 3D generation from sparse visual evidence. - TripoSR arXiv 2024
Fast feed-forward 3D reconstruction from a single image Paper - CRM arXiv / venue TBD
Uses reconstruction priors for consistent 3D asset generation. - LRM ICLR 2024 / arXiv
Learns large reconstruction models for image-to-3D.
Video generation & temporal editing 21
Text-to-video models, motion modules, temporal feature propagation, and video editing.
- VideoLDM CVPR 2023
Extends latent diffusion to video generation. - Text2Video-Zero ICCV 2023
Adapts image diffusion to zero-shot video generation Paper - Tune-A-Video ICCV 2023
Tunes a T2I model for video generation from one video Paper - AnimateDiff ICLR 2024
Adds motion modules to personalized image diffusion models Paper - FateZero ICCV 2023
Uses attention fusion for zero-shot video editing Paper - Video-P2P arXiv 2023
Extends Prompt-to-Prompt-style editing to videos Paper - TokenFlow ICLR 2024
Propagates diffusion features to improve temporal video editing consistency. - CoDeF CVPR 2024
Uses content deformation fields for temporally consistent video processing. - Rerender A Video SIGGRAPH Asia 2023
Performs zero-shot text-guided video-to-video translation. - COVE arXiv 2024
Uses correspondence guidance for video editing Paper - VideoCrafter arXiv 2023
Open video diffusion framework Paper - VideoCrafter2 CVPR 2024
Improves high-quality video diffusion generation Paper - ModelScopeT2V project / 2023
Open text-to-video generation system. - Make-A-Video arXiv 2022
Generates videos from text using image-text and video data. - Imagen Video arXiv 2022
Cascaded video diffusion model. - Phenaki ICLR 2023 / arXiv
Generates long videos from open-domain prompts. - VideoFusion CVPR 2023 / arXiv
Uses decomposed diffusion for video generation. - Latte TMLR / arXiv
Applies latent diffusion transformers to video generation. - VideoPoet ICML 2024 / arXiv
Multimodal video generation and editing model. - Lumiere SIGGRAPH 2024 / arXiv
Space-time diffusion model for coherent video generation. - Sora technical report technical report 2024
Large-scale video generation model emphasizing world simulation properties.
Long-form stories & interactive video 7
Long-horizon narratives, multi-scene planning, interactive control, and shot consistency.
- MovieDreamer arXiv / venue TBD
Studies hierarchical long visual sequence generation. - TaleCrafter arXiv / venue TBD
Generates multi-character visual stories. - One-Prompt-One-Story arXiv / venue TBD
Aims at consistent story generation from a single prompt. - Animate-A-Story arXiv 2023
Generates storytelling videos with retrieval and control signals Paper - MotionStream ICLR 2026
Supports real-time video generation with interactive motion control. - VideoDirectorGPT arXiv 2023
Uses LLM planning for multi-scene video generation. - ShotAdapter arXiv / venue TBD
Adapts video generation for multi-shot consistency.
Personalized video & human animation 6
Subject-aware video customization, talking-human generation, and reference-driven animation.
- VideoBooth arXiv 2023
Customizes video generation to a subject or concept. - DreamVideo arXiv 2023
Personalizes video generation with subject-aware priors. - Vlogger arXiv 2024
Generates talking/head or human-centric video content. - MagicAnimate CVPR 2024
Animates human images under motion guidance Paper - AnimateAnyone CVPR 2024 / arXiv
Animates reference characters with strong identity preservation. - Champ arXiv 2024
Enables controllable and consistent human animation.
Benchmarks & Evaluators
20 resources organized into 4 focused topics.
| Topic | Coverage |
|---|---|
| Multi-view & 3D consistency | 3 |
| Video generation quality & temporal coherence | 7 |
| Story, character & long-horizon consistency | 4 |
| Editing, tracking & feature-based metrics | 6 |
Multi-view & 3D consistency 3
Benchmarks and metrics for geometric compatibility across generated viewpoints.
- MVG-Bench arXiv 2024
Evaluates multi-view generation consistency. - MET3R arXiv 2024
Measures 3D-aware multi-view consistency from generated images. - Multi-view consistency metrics resource
Measures cross-view geometric compatibility.
Back to benchmarks & evaluators ↑
Video generation quality & temporal coherence 7
General video quality, text–video alignment, motion, and physical-temporal diagnostics.
- VBench CVPR 2024
Comprehensive video generation benchmark including subject/background and temporal consistency. - Video-Bench CVPR 2025
Human-aligned video generation benchmark. - EvalCrafter CVPR 2024
Evaluates generated videos along visual, text-video, and motion dimensions. - FETV NeurIPS 2023 Datasets and Benchmarks
Fine-grained open-domain text-to-video evaluation benchmark. Paper - T2V-CompBench arXiv / venue TBD
Tests compositional text-to-video generation. - VideoScore arXiv / venue TBD
Provides learned or automatic video generation quality scoring. - VideoPhy temporal subset ICLR 2025
Uses physical video checks as temporal/world consistency diagnostics.
Back to benchmarks & evaluators ↑
Story, character & long-horizon consistency 4
Identity persistence, story continuity, and long-video evaluation.
- ViStoryBench CVPR 2026 / preprint
Evaluates story visualization, character consistency, and narrative coherence. Paper - Long-video consistency evaluation resource
Focuses on long-horizon entity and scene persistence. - Character consistency benchmark resource
Tests identity preservation across generated sets. - Story visualization benchmark resource
Tests narrative and character persistence in story sequences.
Back to benchmarks & evaluators ↑
Editing, tracking & feature-based metrics 6
Preservation metrics based on editing stability, CLIP/DINO features, face identity, and LPIPS.
- Video editing consistency metrics resource
Measures preservation and temporal stability after video editing. - CLIP frame consistency metric family
Uses semantic features to estimate cross-frame consistency. - DINO tracking consistency metric family
Uses self-supervised features for object/region persistence. - Identity similarity metrics metric family
Evaluates subject or face identity preservation. - Face recognition metrics metric family
Uses face recognition models for identity consistency. - LPIPS temporal smoothness metric family
Measures perceptual smoothness across frames.
Back to benchmarks & evaluators ↑
Datasets & Data Resources
20 resources organized into 4 focused topics.
| Topic | Coverage |
|---|---|
| Video segmentation & tracking | 8 |
| Driving & dynamic scenes | 3 |
| 3D objects & multi-view reconstruction | 8 |
| Synthetic controlled environments | 1 |
Video segmentation & tracking 8
Object persistence, occlusion, scene parsing, and long-term tracking supervision.
- MeViS ICCV 2023
Motion-expression video segmentation data useful for temporal grounding. - MOSE ICCV 2023 / dataset
Video object segmentation data with complex occlusions. - TAO ECCV 2020
Long-tail tracking data for object persistence diagnostics. - VSPW CVPR 2021
Video scene parsing dataset for scene-state continuity. - DAVIS CVPR 2016
Video object segmentation data for temporal preservation. - YouTube-VOS ECCV 2018 / dataset
Large-scale video object segmentation data. - LaSOT CVPR 2019
Long-term single-object tracking dataset. - TrackingNet ECCV 2018 / dataset
Large-scale object tracking data.
Back to datasets & data resources ↑
Driving & dynamic scenes 3
Large-scale autonomous-driving data for geometry, motion, and state continuity.
- nuScenes CVPR 2020
Driving dataset useful for dynamic-scene consistency. - KITTI IJRR 2013 / dataset
Autonomous-driving visual dataset for geometry and temporal checks. - Waymo Open Dataset CVPR 2020 / dataset
Large-scale driving data for world and motion consistency.
Back to datasets & data resources ↑
3D objects & multi-view reconstruction 8
Object assets, camera trajectories, RGB-D scenes, scans, and multi-view imagery.
- Objaverse CVPR 2023 / dataset
Large 3D object dataset for view and 3D generation. - Objaverse-XL NeurIPS 2023 Datasets and Benchmarks
Web-scale 3D object data. - CO3D ICCV 2021 / dataset
Common objects in 3D data for view consistency. - RealEstate10K dataset
Camera-trajectory video data for novel-view synthesis. - ScanNet CVPR 2017 / dataset
RGB-D scene data for geometry-aware generation. - ShapeNet arXiv 2015 / dataset
3D shape dataset for object-level 3D generation. - Google Scanned Objects dataset
High-quality scanned object assets. - MVImgNet CVPR 2023 / dataset
Multi-view image dataset for object-centric reconstruction.
Back to datasets & data resources ↑
Synthetic controlled environments 1
Procedural data generation for controlled scene and temporal diagnostics.
- Kubric CVPR 2022 / dataset generator
Synthetic video/scene data generation for controlled temporal diagnostics. Paper
Back to datasets & data resources ↑
Back to resource index ↑ · Back to top ↑
03 · Normative consistency
Agreement target — Agreement with evaluative or world-level criteria.
Scope — Human preference, aesthetics, safety, fairness, concept restrictions, physical plausibility, commonsense, causality, and world-state validity.
| Resource type | Description | Jump |
|---|---|---|
| Methods | Architectures, objectives, inference procedures, and intervention mechanisms. | Browse 57 |
| Benchmarks & Evaluators | Test suites, metrics, learned scorers, and evaluation protocols. | Browse 30 |
| Datasets & Data Resources | Training corpora, annotations, prompt sets, and diagnostic data. | Browse 20 |
Methods
57 resources organized into 3 focused topics.
| Topic | Coverage |
|---|---|
| Preference models & reward optimization | 20 |
| Safety, unlearning & concept control | 20 |
| World models & physical consistency | 17 |
Preference models & reward optimization 20
Human-preference scorers, direct preference optimization, reinforcement learning, and multi-reward alignment.
- Pick-a-Pic / PickScore NeurIPS 2023
Collects pairwise preferences and trains a preference scorer. - ImageReward NeurIPS 2023
Learns a general human preference reward model for T2I images. Paper - HPS ICCV 2023 / arXiv
Scores generated images according to human preference. - HPSv2 arXiv 2023
Refines human preference scoring and benchmark coverage. - HPSv3 arXiv 2025
Extends preference evaluation to broader text-image distributions. Paper - MPS CVPR 2024
Models multi-dimensional human preferences for T2I generation. - VisionReward AAAI 2026
Learns multi-dimensional reward signals for image and video generation. - Diffusion-DPO NeurIPS 2023 / arXiv
Applies direct preference optimization to diffusion models. - DDPO ICLR 2024
Trains diffusion models with reinforcement learning rewards. - AlignProp ICLR 2024 / arXiv
Backpropagates reward gradients through diffusion sampling. - DPOK arXiv 2023
Applies KL-regularized policy optimization to diffusion models. - D3PO arXiv 2024
Optimizes diffusion policies from preference data. - SPO CVPR 2025
Performs step-by-step preference optimization for aesthetic post-training. - DSPO ICLR 2025
Aligns diffusion models using direct score preference optimization. - RankDPO ICCV 2025
Uses ranked preference data for scalable T2I preference optimization. - CMPO / CaPO CVPR 2025
Calibrates multiple preferences for diffusion alignment. - Diffusion-NPO ICLR 2026
Performs negative preference optimization for diffusion alignment. - BranchGRPO ICLR 2026
Uses branch-level GRPO-style optimization for diffusion generation. - Flow-GRPO arXiv / venue TBD
Applies GRPO-like preference learning to flow/diffusion sampling. - RLAIF for Diffusion topic / resource
Uses AI feedback instead of human feedback for diffusion alignment.
Safety, unlearning & concept control 20
Safety guidance, concept erasure, unlearning, red teaming, filtering, and adversarial robustness.
- Safe Latent Diffusion CVPR 2023
Adds safety guidance during latent diffusion sampling. - Erasing Concepts from Diffusion Models ICCV 2023
Removes undesirable concepts from diffusion weights. - Ablating Concepts ICCV 2023
Ablates target concepts while retaining general model behavior. - Unified Concept Editing WACV 2024 / arXiv
Edits multiple concepts in diffusion models. - MACE CVPR 2024 / arXiv
Scales concept erasure to many concepts. - Forget-Me-Not arXiv 2023
Uses attention control to forget concepts. - Ring-A-Bell NeurIPS 2023 workshop / arXiv
Red-teams concept erasure using adversarial prompts. - ACE arXiv / venue TBD
Studies robust anti-editing concept erasure. - Editing Massive Concepts arXiv / venue TBD
Edits or suppresses many concepts at scale. - SalUn ICLR 2024 / arXiv
Uses saliency-guided unlearning for generative models. - ESD arXiv 2023
Erases stable-diffusion concepts through targeted training. - ConceptPrune arXiv / venue TBD
Removes concepts by pruning or editing model components. - Responsible Text-to-Image Diffusion ICML 2026 / project
Studies controllable and interpretable safe/fair generation. - T2VSafetyBench methods arXiv 2024
Studies safety evaluation and intervention for text-to-video models. - SafeGen arXiv / venue TBD
Improves safety during generative sampling. - Safety Checker / post-hoc filters system resource
Filters generated outputs after sampling. - NSFW prompt filtering system resource
Screens prompts before generation. - Adversarial prompt defense topic / resource
Defends against jailbreak prompts in visual generation. - Jailbreak-resistant diffusion topic / resource
Studies robust safety under prompt attacks. - Concept restoration after erasure topic / resource
Diagnoses benign capability loss after safety editing.
World models & physical consistency 17
Interactive world models, driving simulation, physics-aware guidance, causality, and state transitions.
- UniSim ICLR 2024
Learns interactive real-world simulators for action-conditioned generation. - Genie ICML 2024
Generates interactive environments from videos. - GAIA-1 arXiv / technical report 2023
Builds a generative world model for autonomous driving. - WorldDreamer arXiv 2024
Generates driving videos with world-model priors. - DriveDreamer ECCV 2024 / arXiv
Generates driving scenarios with structured controls. - DriveDreamer-2 arXiv / venue TBD
Extends driving world generation to longer/higher-quality videos. - Vista arXiv / venue TBD
Studies video world models for controllable environments. - Pandora arXiv / venue TBD
Explores world modeling through video generation. - Cosmos World Foundation Models technical report / arXiv
Studies large-scale world foundation models. - HunyuanWorld / Hunyuan World technical report / arXiv
Generates 3D/world environments using generative world modeling. - World-consistent Video Diffusion topic / resource
Enforces geometry, dynamics, and state consistency in video generation. - Physics-guided Diffusion topic / resource
Injects physical constraints into diffusion sampling or training. - Simulator-guided Diffusion topic / resource
Uses simulators or constraints to steer generation. - Verifier-guided Generation topic / resource
Uses post-hoc or in-loop verifiers to reject inconsistent samples. - Causal Video Generation topic / resource
Studies causal state transitions in generated videos. - Object-state-change Generation topic / resource
Focuses on object state changes and action consequences. - Embodied Diffusion World Models topic / resource
Connects diffusion generation with embodied planning and control.
Benchmarks & Evaluators
30 resources organized into 3 focused topics.
| Topic | Coverage |
|---|---|
| Preference & aesthetics | 8 |
| Safety & concept erasure | 7 |
| Physics, causality & world-model evaluation | 15 |
Preference & aesthetics 8
Learned reward models and multidimensional evaluators for human preference and visual quality.
- Pick-a-Pic / PickScore NeurIPS 2023
Pairwise preference data and reward model for T2I outputs. - ImageReward NeurIPS 2023
Learned reward model for human preference evaluation. - HPSv2 arXiv 2023
Human preference benchmark for T2I evaluation. - HPSv3 arXiv 2025
Wide-spectrum preference benchmark and reward model. - VisionReward AAAI 2026
Multi-dimensional image/video preference evaluator. - MPS evaluation CVPR 2024
Evaluates multiple dimensions of human preference. - Aesthetic score models metric family
Score visual aesthetics for generated images. - LAION aesthetic predictor dataset/model resource
Provides aesthetic scores for LAION-like data.
Back to benchmarks & evaluators ↑
Safety & concept erasure 7
Unsafe-generation, concept-removal, benign-retention, and red-teaming protocols.
- Six-CD arXiv / venue TBD
Evaluates concept removal and benign retention. - I2P arXiv 2023
Prompt benchmark for inappropriate image generation risks. - Unsafe Diffusion benchmark resource
Evaluates unsafe output generation. - T2VSafetyBench arXiv 2024
Safety benchmark for text-to-video generation. - Concept removal benchmarks resource
Measures erasure success and collateral damage. - Benign retention benchmarks resource
Tests whether safe editing harms benign generations. - Red-teaming prompts resource
Stress-tests safety filters and concept removal.
Back to benchmarks & evaluators ↑
Physics, causality & world-model evaluation 15
Static and dynamic physical reasoning, action consequences, and world-state validity.
- PhyBench arXiv 2024
Static physical commonsense benchmark for T2I. - VideoPhy ICLR 2025
Physical commonsense benchmark for generated videos. - PhyCoBench arXiv 2024
Optical-flow-guided physical coherence benchmark. - PhyGenBench arXiv 2024
Physical-law benchmark for video generation. - VideoPhy-2 ICLR 2026
Action-centric physical commonsense benchmark. - T2VPhysBench arXiv / venue TBD
Tests first-principles physical consistency in T2V. - T2VWorldBench arXiv / venue TBD
Evaluates world knowledge, commonsense, and causal plausibility. - Physics-IQ WACV 2026
Tests physical principles in generative video models. - PhyWorldBench arXiv 2025
Benchmarks physical realism in text-to-video generation. - VideoVerse arXiv 2025
World-model-oriented T2V evaluation. - PhyEduVideo WACV 2026
Physics-education-oriented video benchmark. - PhyWorld ICML 2025
Studies how far video generation is from physical world models. - OSCBench arXiv / venue TBD
Tests object state change and action consequence. - Morpheus arXiv / venue TBD
Evaluates physical reasoning in video generation. - World-model Video Evaluation resource
General benchmarks for video-as-world-model behavior.
Back to benchmarks & evaluators ↑
Datasets & Data Resources
20 resources organized into 3 focused topics.
| Topic | Coverage |
|---|---|
| Preference & aesthetics | 7 |
| Safety & concept control | 3 |
| Physical reasoning & world dynamics | 10 |
Preference & aesthetics 7
Pairwise preference annotations, reward-model training data, and aesthetic ratings.
- Pick-a-Pic dataset NeurIPS 2023
Pairwise human preferences for generated images. - ImageRewardDB NeurIPS 2023 resource
Human preference annotations for reward training. - HPD / HPSv2 data arXiv 2023 resource
Human preference data for T2I evaluation. - HPDv3 / HPSv3 data arXiv 2025 resource
Larger preference dataset for wide-spectrum evaluation. - MPS preference data CVPR 2024
Multi-dimensional preference labels. - LAION-Aesthetics dataset resource
Image-text data filtered by aesthetic scores. - AVA Aesthetics CVPR 2012 / dataset
Aesthetic image-quality annotations.
Back to datasets & data resources ↑
Safety & concept control 3
Unsafe prompt sets, NSFW resources, and concept-erasure diagnostics.
- I2P prompts arXiv 2023 resource
Inappropriate prompt set for safety testing. - NSFW prompt resources resource
Prompts for unsafe content testing. - Concept erasure prompt sets resource
Prompts for target concept removal.
Back to datasets & data resources ↑
Physical reasoning & world dynamics 10
Physical commonsense, video dynamics, driving, egocentric interaction, and synthetic physics data.
- Physical commonsense prompts resource
Prompts testing static physical plausibility. - Video physical prompts resource
Prompts testing dynamic physical plausibility. - Driving world-model datasets resource
Driving data for action-conditioned world models. - Ego4D CVPR 2022 / dataset
Egocentric video data for embodied and action reasoning. - Something-Something V2 ICCV 2017 / dataset
Human-object interaction videos for action/state understanding. - CLEVRER ICLR 2020 / dataset
Synthetic videos for physical and causal reasoning. - PHYRE NeurIPS 2019 / benchmark
Physical reasoning environments. - IntPhys arXiv 2018 / dataset
Intuitive physics video dataset. - CLEVR CVPR 2017 / dataset
Synthetic visual reasoning data. - Kubric CVPR 2022
Synthetic scene/video generator useful for controlled physical diagnostics.
Back to datasets & data resources ↑
Back to resource index ↑ · Back to top ↑
Machine-readable resources
The repository includes structured companion files for programmatic analysis and maintenance:
resources/benchmark_coverage.csv: benchmark, dataset, evaluator, and diagnostic-resource coverage map.resources/related_surveys.csv: prior survey positioning.resources/taxonomy_methods.csv: compact mapping from taxonomy nodes to representative methods and resources.resources/selected_bibtex.bib: selected BibTeX entries.
Coverage labels
| Label | Meaning |
|---|---|
| P/C | prompt and compositional faithfulness |
| S/E | structural control and edit preservation |
| ID | subject/identity persistence |
| V/T | multi-view, temporal, or narrative coherence |
| N/S | preference, safety, or value alignment |
| P/W | physical, causal, or world-grounded plausibility |
Coverage values: H = direct/dedicated coverage, M = partial/adaptable coverage, L = indirect/low coverage.
Contribution guide
Contributions are welcome. Please keep additions concise, verifiable, and aligned with the relation-based taxonomy. Please include the resource title, BibTeX key, venue/year, official paper URL, official project/code URL if available, resource type, modality, primary consistency relation, coverage values, and a short diagnostic-use/blind-spot description.
Use the issue template: Add or correct a resource.
[!TIP] Prefer official paper pages, author-maintained repositories, and stable proceedings links. Include enough information for another maintainer to verify the entry without additional searching.
Maintenance notes
Some 2025--2026 papers may initially appear as arXiv or project-page entries before official proceedings metadata is stable. When official BibTeX becomes available, please update resources/selected_bibtex.bib and any corresponding table entries.
When adding links, prefer official repositories or project pages over unofficial reimplementations. If no stable official repository exists, leave the code URL blank in the CSV table. Entries with arXiv-search links are included as expansion placeholders and should be replaced by stable paper/project links when available.
Citation
If this survey or resource collection is useful in your research, please cite:
@article{yan2026consistency, title = {Consistency in Diffusion-Based Visual Generation: A Survey}, author = {Yan, Song and Zhai, Wei and Wang, Chenfeng and Li, Ruixuan and Yang, Zhangping and Cai, Yancheng and Zhang, Tao and Wang, Ling and Lan, Yunwei and He, Yujie and Cao, Yang and Li, Min and Zha, Zheng-Jun}, year = {2026}, doi = {10.20944/preprints202606.0870.v1}, url = {https://www.preprints.org/manuscript/202606.0870/v1}, note = {Preprints} }
License
This repository is released under the MIT License.