Updates
- [2026/03/09] We release the Logics-Parsing-Omni. For more details, please check our Technical Report.
- [2026/02/13] 🚀🚀🚀🚀🚀 We release Logics-Parsing-v2 Model.
- [2025/09/25] 🚀🚀🚀We release Logics-Parsing Model. For more details, please check our Technical Report.
Introduction
Logics-Parsing-v2 is an advanced evolution of the previously proposed Logics-Parsing (v1). It inherits all the core capabilities of v1 model, while demonstrating more powerful capabilities on handling complex documents. Furthermore, it extends support for Parsing-2.0 scenarios, enabling structured parsing of musical sheets, flowcharts, as well as code/pseudocode blocks.

Key Features
v1
-
Effortless End-to-End Processing
- Our single-model architecture eliminates the need for complex, multi-stage pipelines. Deployment and inference are straightforward, going directly from a document image to structured output.
- It demonstrates exceptional performance on documents with challenging layouts.
-
Advanced Content Recognition
- It accurately recognizes and structures difficult content, including intricate scientific formulas.
- Chemical structures are intelligently identified and can be represented in the standard SMILES format.
-
Rich, Structured HTML Output
- The model generates a clean HTML representation of the document, preserving its logical structure.
- Each content block (e.g., paragraph, table, figure, formula) is tagged with its category, bounding box coordinates, and OCR text.
- It automatically identifies and filters out irrelevant elements like headers and footers, focusing only on the core content.
-
State-of-the-Art Performance
- Logics-Parsing achieves the best performance on our in-house benchmark, which is specifically designed to comprehensively evaluate a model’s parsing capability on complex-layout documents and STEM content.
v2
-
Effortless End-to-End Processing
- End-to-end recognition and parsing for various kinds of document elements within a single model.
- Handles complex-layout and text-dense documents such as newspapers and magazines with exceptional precision and ease;
-
Advanced Content Recognition
- Smaller in size, greater in performance, delivering more accurate and structured parsing of tables and scientific formulas.
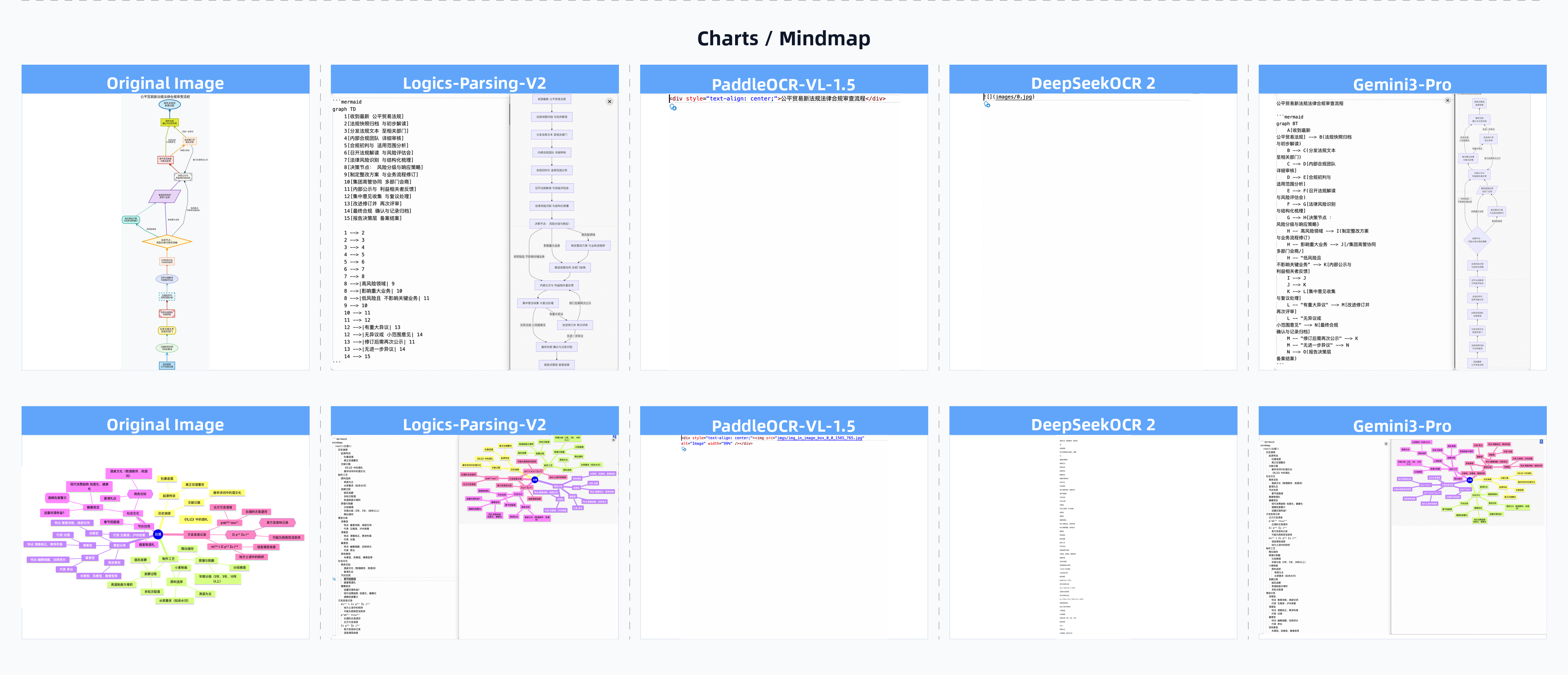
- Introducing Parsing-2.0: natively supports parsing of diverse structured content, including flowcharts, music sheets and pseudocode blocks.
-
Rich, Structured HTML Output
- Transforms documents into concise HTML -- capturing not just content, but also element types, spatial layouts, and semantic hierarchy.
- More scientific and intuitive formats for structured elements -- such as Mermaid for flowcharts and ABC notation for musical scores.
-
State-of-the-Art Performance
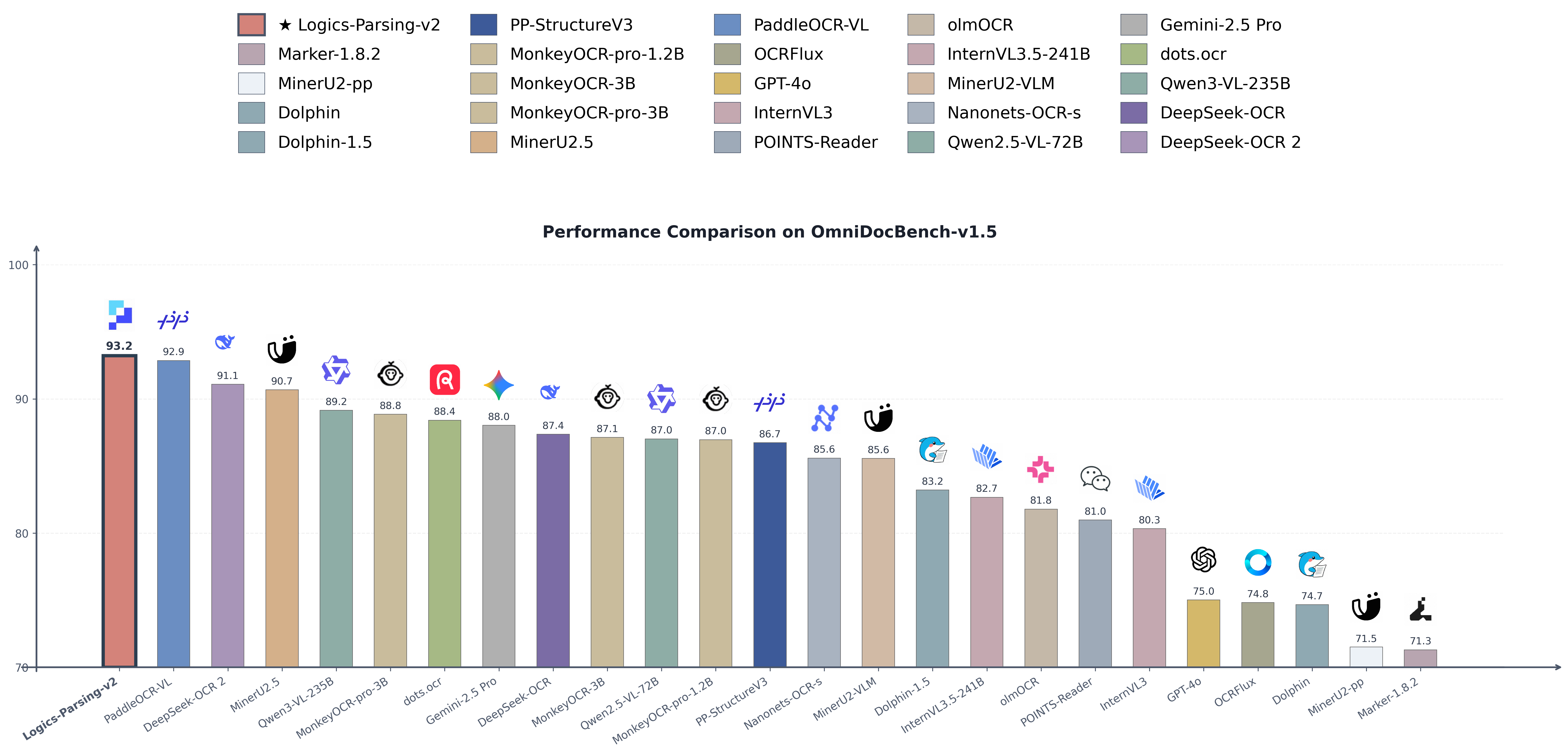
- SOTA across the board: Logics-Parsing-v2 sets top records on both our in-house benchmark (overall score: 82.16) and the renowned public benchmark OmniDocBench-v1.5 (overall score: 93.23).
Benchmark
v1
Existing document-parsing benchmarks often provide limited coverage of complex layouts and STEM content. To address this, we constructed an in-house benchmark comprising 1,078 page-level images across nine major categories and over twenty sub-categories. Our model achieves the best performance on this benchmark.
| Model Type | Methods | Overall Edit ↓ | Text Edit Edit ↓ | Formula Edit ↓ | Table TEDS ↑ | Table Edit ↓ | ReadOrderEdit ↓ | ChemistryEdit ↓ | HandWritingEdit ↓ | ||||||
| EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | ALL | ALL | ||
| Pipeline Tools | doc2x | 0.209 | 0.188 | 0.128 | 0.194 | 0.377 | 0.321 | 81.1 | 85.3 | 0.148 | 0.115 | 0.146 | 0.122 | 1.0 | 0.307 |
| Textin | 0.153 | 0.158 | 0.132 | 0.190 | 0.185 | 0.223 | 76.7 | 86.3 | 0.176 | 0.113 | 0.118 | 0.104 | 1.0 | 0.344 | |
| mathpix* | 0.128 | 0.146 | 0.128 | 0.152 | 0.06 | 0.142 | 86.2 | 86.6 | 0.120 | 0.127 | 0.204 | 0.164 | 0.552 | 0.263 | |
| PP_StructureV3 | 0.220 | 0.226 | 0.172 | 0.29 | 0.272 | 0.276 | 66 | 71.5 | 0.237 | 0.193 | 0.201 | 0.143 | 1.0 | 0.382 | |
| Mineru2 | 0.212 | 0.245 | 0.134 | 0.195 | 0.280 | 0.407 | 67.5 | 71.8 | 0.228 | 0.203 | 0.205 | 0.177 | 1.0 | 0.387 | |
| Marker | 0.324 | 0.409 | 0.188 | 0.289 | 0.285 | 0.383 | 65.5 | 50.4 | 0.593 | 0.702 | 0.23 | 0.262 | 1.0 | 0.50 | |
| Pix2text | 0.447 | 0.547 | 0.485 | 0.577 | 0.312 | 0.465 | 64.7 | 63.0 | 0.566 | 0.613 | 0.424 | 0.534 | 1.0 | 0.95 | |
| Expert VLMs | Dolphin | 0.208 | 0.256 | 0.149 | 0.189 | 0.334 | 0.346 | 72.9 | 60.1 | 0.192 | 0.35 | 0.160 | 0.139 | 0.984 | 0.433 |
| dots.ocr | 0.186 | 0.198 | 0.115 | 0.169 | 0.291 | 0.358 | 79.5 | 82.5 | 0.172 | 0.141 | 0.165 | 0.123 | 1.0 | 0.255 | |
| MonkeyOcr | 0.193 | 0.259 | 0.127 | 0.236 | 0.262 | 0.325 | 78.4 | 74.7 | 0.186 | 0.294 | 0.197 | 0.180 | 1.0 | 0.623 | |
| OCRFlux | 0.252 | 0.254 | 0.134 | 0.195 | 0.326 | 0.405 | 58.3 | 70.2 | 0.358 | 0.260 | 0.191 | 0.156 | 1.0 | 0.284 | |
| Gotocr | 0.247 | 0.249 | 0.181 | 0.213 | 0.231 | 0.318 | 59.5 | 74.7 | 0.38 | 0.299 | 0.195 | 0.164 | 0.969 | 0.446 | |
| Olmocr | 0.341 | 0.382 | 0.125 | 0.205 | 0.719 | 0.766 | 57.1 | 56.6 | 0.327 | 0.389 | 0.191 | 0.169 | 1.0 | 0.294 | |
| SmolDocling | 0.657 | 0.895 | 0.486 | 0.932 | 0.859 | 0.972 | 18.5 | 1.5 | 0.86 | 0.98 | 0.413 | 0.695 | 1.0 | 0.927 | |
| Logics-Parsing | 0.124 | 0.145 | 0.089 | 0.139 | 0.106 | 0.165 | 76.6 | 79.5 | 0.165 | 0.166 | 0.136 | 0.113 | 0.519 | 0.252 | |
| General VLMs | Qwen2VL-72B | 0.298 | 0.342 | 0.142 | 0.244 | 0.431 | 0.363 | 64.2 | 55.5 | 0.425 | 0.581 | 0.193 | 0.182 | 0.792 | 0.359 |
| Qwen2.5VL-72B | 0.233 | 0.263 | 0.162 | 0.24 | 0.251 | 0.257 | 69.6 | 67 | 0.313 | 0.353 | 0.205 | 0.204 | 0.597 | 0.349 | |
| Doubao-1.6 | 0.188 | 0.248 | 0.129 | 0.219 | 0.273 | 0.336 | 74.9 | 69.7 | 0.180 | 0.288 | 0.171 | 0.148 | 0.601 | 0.317 | |
| GPT-5 | 0.242 | 0.373 | 0.119 | 0.36 | 0.398 | 0.456 | 67.9 | 55.8 | 0.26 | 0.397 | 0.191 | 0.28 | 0.88 | 0.46 | |
| Gemini2.5 pro | 0.185 | 0.20 | 0.115 | 0.155 | 0.288 | 0.326 | 82.6 | 80.3 | 0.154 | 0.182 | 0.181 | 0.136 | 0.535 | 0.26 | |
Comparisons on LogicsDocBench
We introduce LogicsDocBench, a new comprehensive evaluation benchmark comprising 900 carefully selected PDF pages, covering both traditional document Parsing-1.0 tasks and the newly introduced Parsing-2.0 scenarios. This benchmark is designed to better assess models’ capabilities in complex and diverse real-world documents parsing. The dataset is organized into three core document subsets:
-
STEM Documents (218 pages):
Focuses on high-difficulty academic and educational content, spanning over ten domains including physics, mathematics, engineering, and interdisciplinary sciences. This subset evaluates deep understanding of mathematical formulas, technical terminology, and structured knowledge representation.
-
Complex Layouts (459 pages):
Includes challenging real-world layouts such as multi-column text, cross-page tables, vertical writing, and mixed text-image arrangements. This subset comprehensively evaluate a model’s layout analysis abilities.
-
Parsing-2.0 Content (223 pages):
Targets modern digital and semi-structured content that poses significant challenges for traditional OCR systems, including:
- Chemical Molecular formulas
- Musical sheets
- Code and pseudo-code block
- Flowcharts and mind maps
For Parsing-1.0 tasks, we adopt the same evaluation protocols as OmniDocBench-v1.5 to ensure fairness and consistency across benchmarks. For Parsing-2.0, we report fine-grained results using edit distance for each subcategory, and compute an overall score as follows:
$$\small \text{Overall} = \frac{Parsing1.0^{Overall} \times 3 + (1-{Chemistry}^{Edit})\times 100 + (1-{Code}^{Edit})\times 100 + (1-{Chart}^{Edit})\times 100 + (1-{Music}^{Edit})\times 100}{7}$$
Comprehensive evaluation of document parsing on LogicsDocBench is listed as follows:
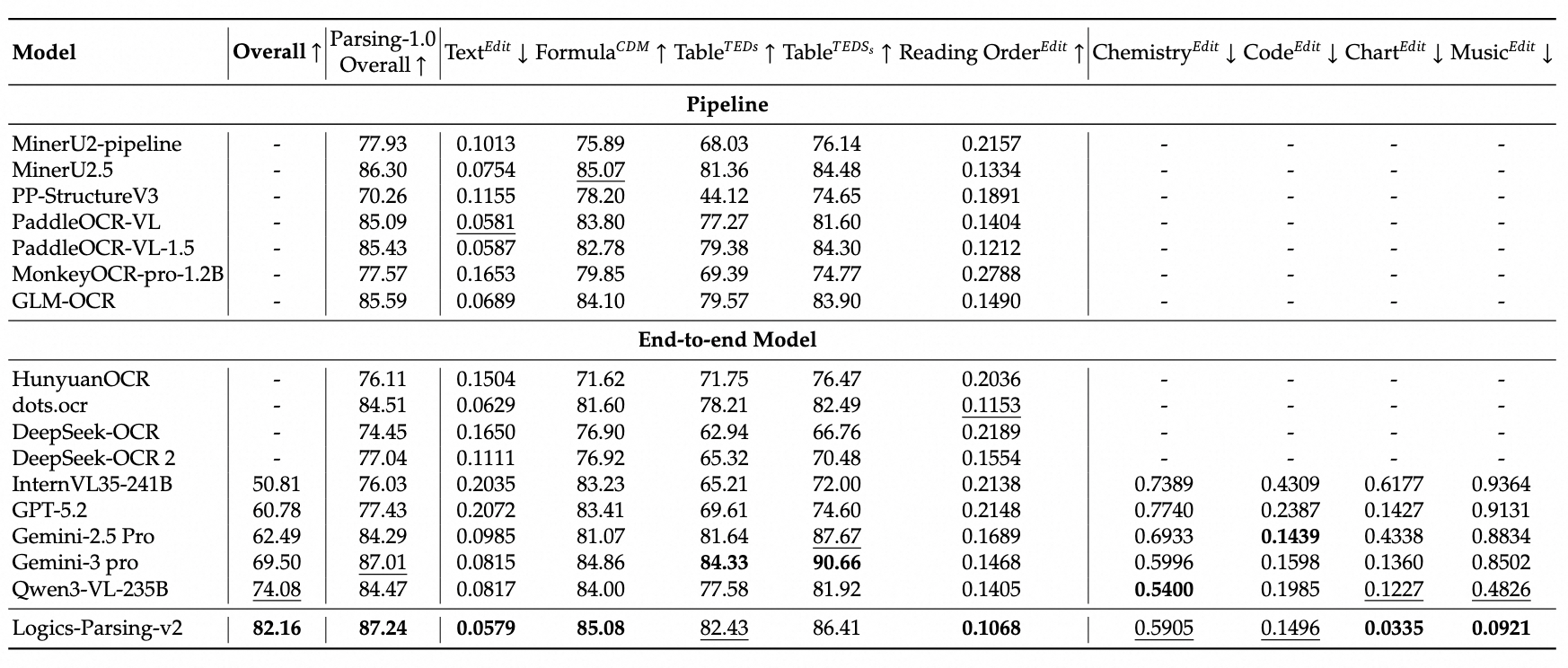
The histogram below provides a more intuitive visualization of the advantages of our Logics-Parsing-v2 model in both Parsing-1.0 and 2.0 scenarios.
Comparisons on OmniDocBench_v1.5
We also provide the experimental results of our newly proposed Logics-Parsing-v2 model on the widely recognized open-source benchmark OmniDocBench-v1.5. As shown in the table below, Logics-Parsing-v2 achieves highly competitive performance.
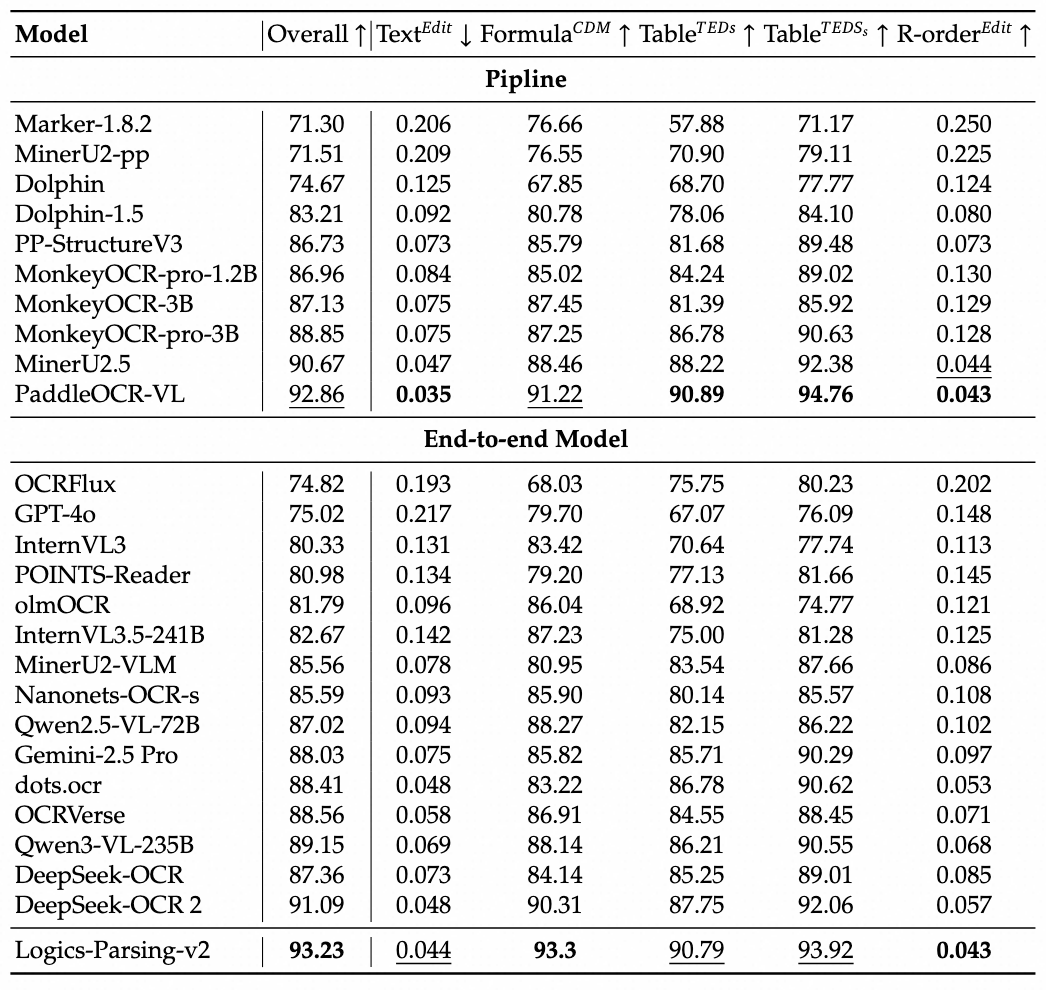
* The model results in the table are sourced from the official OmniDocBench website.
Quick Start
v1
1. Installation
conda create -n logis-parsing python=3.10
conda activate logis-parsing
pip install -r requirement.txt2. Download Model Weights
# Download our model from Modelscope.
pip install modelscope
python download_model.py -t modelscope
# Download our model from huggingface.
pip install huggingface_hub
python download_model.py -t huggingface
3. Inference
python3 inference.py --image_path PATH_TO_INPUT_IMG --output_path PATH_TO_OUTPUT --model_path PATH_TO_MODEL1. Installation
conda create -n logis-parsing-v2 python=3.10
conda activate logis-parsing-v2
pip install -r requirements.txt2. Download Model Weights
# Download our model from Modelscope.
pip install modelscope
python download_model_v2.py -t modelscope
# Download our model from huggingface.
pip install huggingface_hub
python download_model_v2.py -t huggingface
3. Inference
python3 inference_v2.py --image_path PATH_TO_INPUT_IMG --output_path PATH_TO_OUTPUT --model_path PATH_TO_MODELShowcases






Acknowledgments
We would like to acknowledge the following open-source projects that provided inspiration and reference for this work: