Continuously Augmented Discrete Diffusion
![]()
This repository accompanies the ICLR 2026 paper: Continuously Augmented Discrete Diffusion Model for Categorical Generative Modeling.
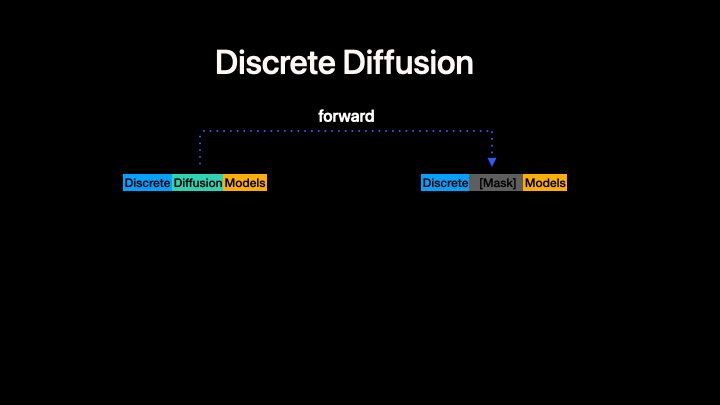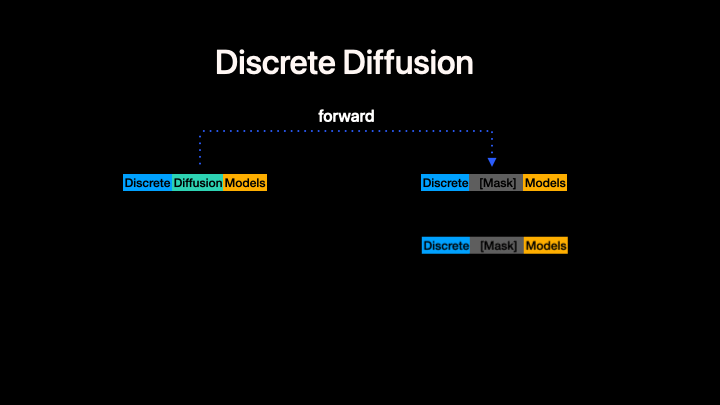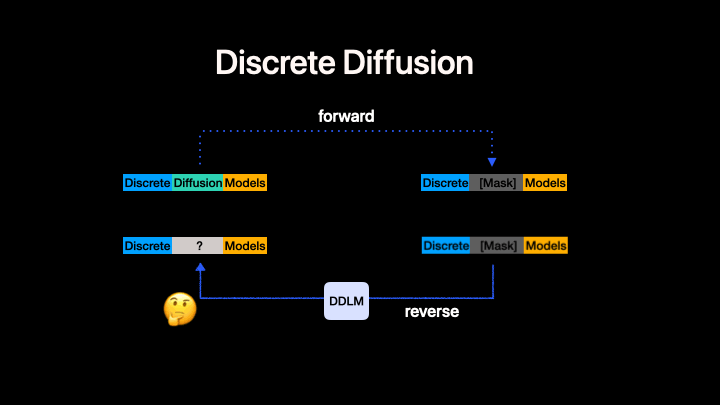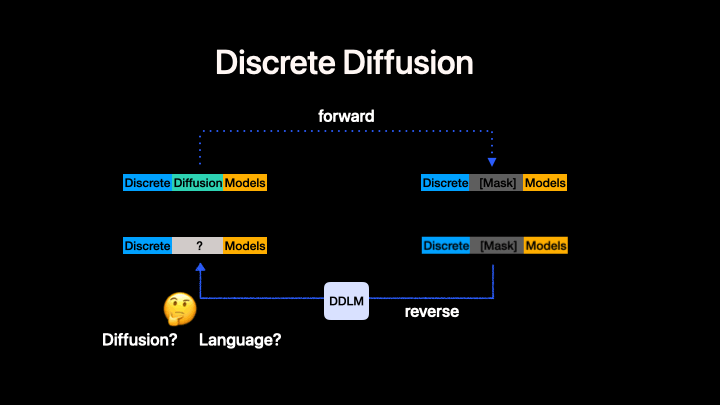
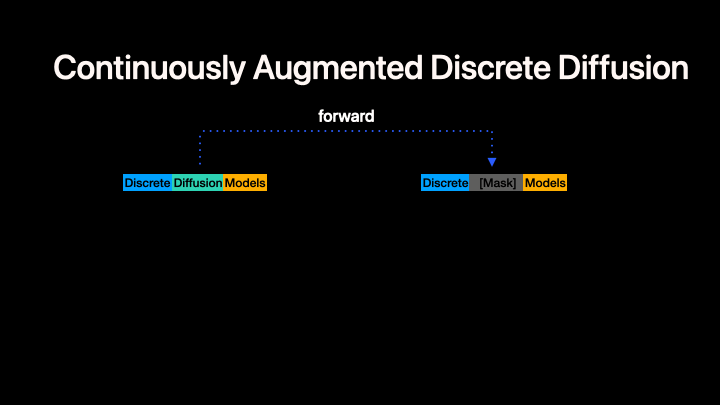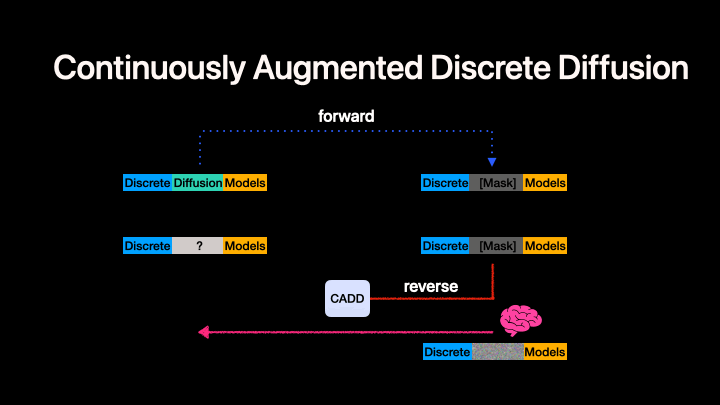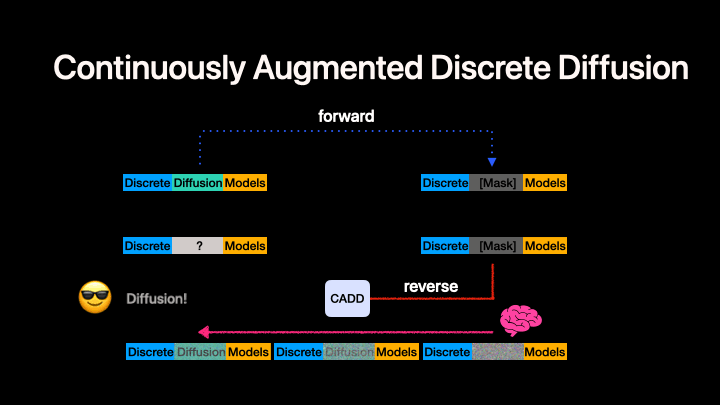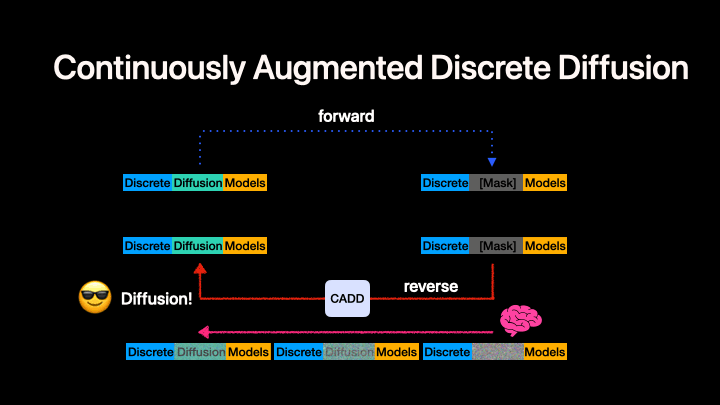
Left: Standard discrete diffusion (mask-based denoising). Right: CADD augments the discrete process with a continuous flow-matching signal in embedding space.
Overview
CADD (Continuously Augmented Discrete Diffusion) extends discrete diffusion language models by adding a continuous flow-matching component to the masked denoising process. At each diffusion step, a continuous embedding signal is added to the discrete mask-token embeddings, providing additional information about the clean data that helps guide the denoising process.
Key idea: During both training and inference, the model input at masked positions is embed(mask_token) + z_continuous, where z_continuous follows a linear flow-matching trajectory from noise to clean embeddings:
z_continuous = (1 - t) * z_0 + t * noise
- At
t = 1(fully masked):z_continuous = noise(no signal) - At
t = 0(fully clean):z_continuous = z_0(clean embedding)
This is orthogonal to the discrete unmasking strategy --- any MDM algorithm can be combined with CADD. In this codebase we currently present our code generation experiment as an example. CADD.md provide the quickstart to help turn your MDMs to CADDs.
Results
CADD-Coder achieves the following results on code generation benchmarks:
| Model | HumanEval | HumanEval+ | MBPP | MBPP+ | BCB |
|---|---|---|---|---|---|
| DiffuCoder (baseline, no CADD) | 67.1 | 60.4 | 74.2 | 60.9 | 40.2 |
| CADD-Coder | 72.0 | 63.4 | 75.7 | 63.2 | 42.1 |
This result is produced with settings: alg=entropy, temperature=0.1, steps=512, cadd_sampling_mode=weighted. For full training and sampling details, see reproduce.md.
Codebase Structure
ms-CADD/
README.md # This file
CADD.md # Detailed algorithm description
reproduce.md # Training and sampling parameters for reproduction
LICENSE # Apple software license
LICENSE_MODELS # Apple model license
CONTRIBUTING.md # Contribution guide
requirements.txt # Dependencies
configuration_dream.py # Model configuration (DreamConfig)
modeling_dream.py # Model architecture (DreamModel)
generation_utils.py # CADD-enabled sampling (DreamGenerationMixin)
asset/ # Visualizations
generation_utils.py--- The core file. DefinesDreamGenerationMixinwith the_sample()method that implements CADD sampling, including continuous flow-matching initialization, forward pass withinputs_embeds, and the flow-matching update loop.modeling_dream.py--- DefinesDreamModel, the transformer architecture with bidirectional attention for discrete diffusion. Supports bothinput_idsandinputs_embedsfor the CADD forward pass.configuration_dream.py--- DefinesDreamConfig, the model configuration class.CADD.md--- Detailed walkthrough of the CADD training and sampling algorithms with pseudocode.reproduce.md--- Exact hyperparameters (training and sampling) to reproduce the reported results.
CADD Sampling Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
use_cadd | bool | True | Enable CADD continuous augmentation |
cadd_sampling_mode | str | "argmax" | How to estimate z_0 from logits: "weighted" (softmax-weighted) or "argmax" |
alg | str | "origin" | Unmasking strategy: "entropy", "origin", "maskgit_plus", "topk_margin" |
temperature | float | 1.0 | Sampling temperature for token prediction |
steps | int | 512 | Number of diffusion steps |
Getting Started
1. Install Dependencies
pip install -r requirements.txt
2. Download the Model
The CADD-Coder checkpoint will be released on HuggingFace.
Download and place the checkpoint weights to your desired path (./cadd-coder/ for example) and overlay the CADD generation code:
from huggingface_hub import snapshot_download snapshot_download("apple/CADD-Base-7B", local_dir="./cadd-coder")
# Copy CADD code into the model directory cp generation_utils.py modeling_dream.py configuration_dream.py ./cadd-coder/
3. Generate Code with CADD
from transformers import AutoTokenizer, AutoModel import torch model_path = "./cadd-coder" tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) model = AutoModel.from_pretrained( model_path, trust_remote_code=True, torch_dtype=torch.bfloat16 ).cuda() # Generate with CADD prompt = "def fibonacci(n):\n" input_ids = tokenizer(prompt, return_tensors="pt").input_ids.cuda() output = model.diffusion_generate( input_ids, max_new_tokens=512, steps=512, temperature=0.1, alg="entropy", alg_temp=0.0, use_cadd=True, cadd_sampling_mode="weighted", ) print(tokenizer.decode(output[0], skip_special_tokens=True))
4. Evaluate on Benchmarks
Use standard public evaluation tools:
# Install evaluation tools pip install evalplus bigcodebench # HumanEval (pass@1) python -m evalplus.generate --model ./cadd-coder --backend diffusion \ --temperature 0.1 --steps 512 --alg entropy \ --use_cadd --cadd_sampling_mode weighted \ --dataset humaneval --bs 1 --n_samples 1 # MBPP (pass@1) python -m evalplus.generate --model ./cadd-coder --backend diffusion \ --temperature 0.1 --steps 512 --alg entropy \ --use_cadd --cadd_sampling_mode weighted \ --dataset mbpp --bs 1 --n_samples 1
See reproduce.md for the complete evaluation setup.
Citation
@article{zheng2025continuously, title={Continuously augmented discrete diffusion model for categorical generative modeling}, author={Zheng, Huangjie and Gong, Shansan and Zhang, Ruixiang and Chen, Tianrong and Gu, Jiatao and Zhou, Mingyuan and Jaitly, Navdeep and Zhang, Yizhe}, journal={arXiv preprint arXiv:2510.01329}, year={2025} }
Acknowledgments
Our codebase is built upon Diffucoder. We sincerely appreciate OpenCoder, LLaMA-Factory, Dream and Qwen2.5-Coder for their opensourcing efforts:
License
Please refer to the LICENSE file for details.