Star 历史趋势
数据来源: GitHub API · 生成自 Stargazers.cn
README.md
Vivid-VR: Distilling Concepts from Text-to-Video Diffusion Transformer for Photorealistic Video Restoration
Alibaba Group - Taobao & Tmall Group
* Corresponding author

Click to download more visual comparisons on [synthetic], [real-world], and [AIGC] videos.
For more video visualizations, go checkout our [project page].
🔥 Update
- [2026.01.26] This work has been accepted by ICLR 2026.
- [2025.09.29] Paper Update: Add some experiments. Go checkout the revised paper at [link].
- [2025.09.20] Support restoration-guided sampling for the trade-off between fidelity and realism, using the arg "--restoration_guidance_scale", click here to view visual comparisons.
- [2025.08.30] Support long video inference by aggregate sampling in the temporal dimension, using the arg "--num_temporal_process_frames".
- [2025.08.21] Paper is released at [link].
- [2025.08.06] UGC50 and AIGC50 testsets are made publicly available from [link].
- [2025.08.05] Inference code is released.
- [2025.08.05] This repo is created.
🎬 Overview
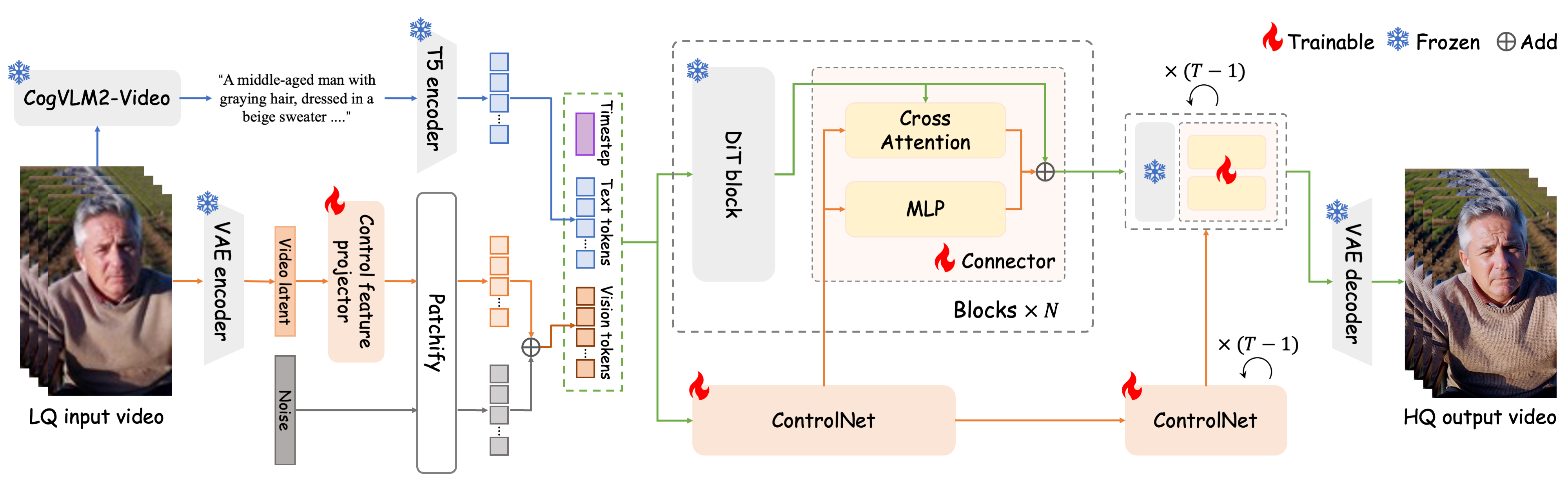
🔧 Dependencies and Installation
-
Clone Repo
git clone https://github.com/csbhr/Vivid-VR.git cd Vivid-VR -
Create Conda Environment and Install Dependencies
# create new conda env conda create -n Vivid-VR python=3.10 conda activate Vivid-VR # install pytorch pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 --index-url https://download.pytorch.org/whl/cu121 # install python dependencies pip install -r requirements.txt # install easyocr [Optional, for text fix] pip install easyocr pip install numpy==1.26.4 # numpy2.x maybe installed when installing easyocr, which will cause conflicts -
Download Models
- [Required] Download CogVideoX1.5-5B checkpoints from [huggingface].
- [Required] Download cogvlm2-llama3-caption checkpoints from [huggingface].
- Please replace
modeling_cogvlm.pyin the downloaded cogvlm2-llama3-caption directory with./VRDiT/cogvlm2-llama3-caption /modeling_cogvlm.pyto remove the dependency on pytorchvideo.
- Please replace
- [Required] Download Vivid-VR checkpoints from [huggingface].
- [Optional, for text fix] Download easyocr checkpoints [english_g2] [zh_sim_g2] [craft_mlt_25k].
- [Optional, for text fix] Download Real-ESRGAN checkpoints [RealESRGAN_x2plus].
- Put them under the
./ckptsfolder.
The
ckptsdirectory structure should be arranged as:├── ckpts │ ├── CogVideoX1.5-5B │ │ ├── ... │ ├── cogvlm2-llama3-caption │ │ ├── ... │ ├── Vivid-VR │ │ ├── controlnet │ │ ├── config.json │ │ ├── diffusion_pytorch_model.safetensors │ │ ├── connectors.pt │ │ ├── control_feat_proj.pt │ │ ├── control_patch_embed.pt │ ├── easyocr │ │ ├── craft_mlt_25k.pth │ │ ├── english_g2.pth │ │ ├── zh_sim_g2.pth │ ├── RealESRGAN │ │ ├── RealESRGAN_x2plus.pth
☕️ Quick Inference
Run the following commands to try it out:
python VRDiT/inference.py \ --ckpt_dir=./ckpts \ --cogvideox_ckpt_path=./ckpts/CogVideoX1.5-5B \ --cogvlm2_ckpt_path=./ckpts/cogvlm2-llama3-caption \ --input_dir=/dir/to/input/videos \ --output_dir=/dir/to/output/videos \ --num_temporal_process_frames=121 \ # For long video inference, if video longer than num_temporal_process_frames, aggregate sampling will be enabled in the temporal dimension --restoration_guidance_scale=-1.0 \ # Optional, for restoration-guided sampling, if set to -1.0, it will be disable --upscale=0 \ # Optional, if set to 0, the short-size of output videos will be 1024 --textfix \ # Optional, if given, the text region will be replaced by the output of Real-ESRGAN --save_images # Optional, if given, the video frames will be saved
GPU memory usage:
- For a 121-frame video, it requires approximately 43GB GPU memory.
- If you want to reduce GPU memory usage, replace "pipe.enable_model_cpu_offload" with "pipe.enable_sequential_cpu_offload" in
./VRDiT/inference.py. GPU memory usage is reduced to 25GB, but the inference time is longer. - For the arg "--num_temporal_process_frames", smaller values require less GPU memory but increase inference time.
Trade-off between fidelity and realism:
- Using the arg "--restoration_guidance_scale" to enable restoration-guided sampling. Higher value yield more realistic results, while lower value preserve greater fidelity to the original input content. When the value is -1, restoration-guided sampling is disabled.
- Click here to view visual comparisons.
📧 Citation
If you find our repo useful for your research, please consider citing it:
@InProceedings{bai2026vividvr, title={Vivid-VR: Distilling Concepts from Text-to-Video Diffusion Transformer for Photorealistic Video Restoration}, author={Bai, Haoran and Chen, Xiaoxu and Yang, Canqian and He, Zongyao and Deng, Sibin and Chen, Ying}, booktitle={International Conference on Learning Representations (ICLR)}, year={2026} }
📄 License
- This repo is built based on diffusers v0.31.0, which is distributed under the terms of the Apache License 2.0.
- CogVideoX1.5-5B models are distributed under the terms of the CogVideoX License.
- cogvlm2-llama3-caption models are distributed under the terms of the CogVLM2 License and LLAMA3 License.
- Real-ESRGAN models are distributed under the terms of the BSD 3-Clause License.
- easyocr models are distributed under the terms of the JAIDED.AI Terms and Conditions.
关于 About
The official repository of our ICLR 2026 paper "Vivid-VR: Distilling Concepts from Text-to-Video Diffusion Transformer for Photorealistic Video Restoration".
语言 Languages
Python100.0%
Makefile0.0%
提交活跃度 Commit Activity
代码提交热力图
过去 52 周的开发活跃度44
Total Commits峰值: 18次/周
LessMore