DeepSeek-V3.2-Exp

Introduction
We are excited to announce the official release of DeepSeek-V3.2-Exp, an experimental version of our model. As an intermediate step toward our next-generation architecture, V3.2-Exp builds upon V3.1-Terminus by introducing DeepSeek Sparse Attention—a sparse attention mechanism designed to explore and validate optimizations for training and inference efficiency in long-context scenarios.
This experimental release represents our ongoing research into more efficient transformer architectures, particularly focusing on improving computational efficiency when processing extended text sequences.
-
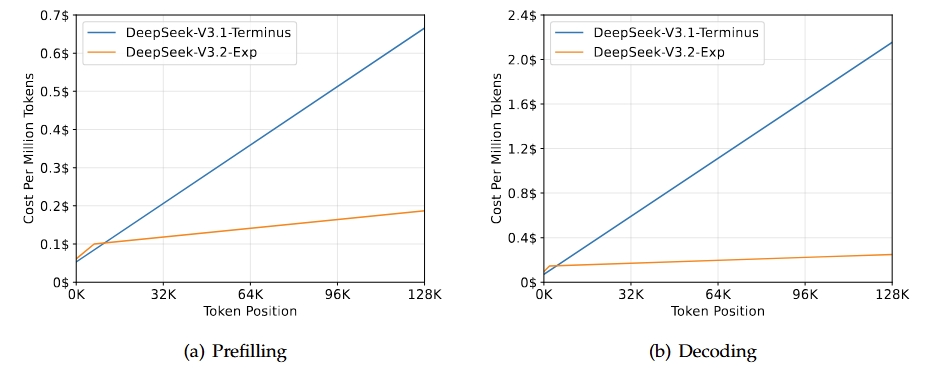
DeepSeek Sparse Attention (DSA) achieves fine-grained sparse attention for the first time, delivering substantial improvements in long-context training and inference efficiency while maintaining virtually identical model output quality.
-
To rigorously evaluate the impact of introducing sparse attention, we deliberately aligned the training configurations of DeepSeek-V3.2-Exp with V3.1-Terminus. Across public benchmarks in various domains, DeepSeek-V3.2-Exp demonstrates performance on par with V3.1-Terminus.
| Benchmark | DeepSeek-V3.1-Terminus | DeepSeek-V3.2-Exp |
|---|---|---|
| Reasoning Mode w/o Tool Use | ||
| MMLU-Pro | 85.0 | 85.0 |
| GPQA-Diamond | 80.7 | 79.9 |
| Humanity's Last Exam | 21.7 | 19.8 |
| LiveCodeBench | 74.9 | 74.1 |
| AIME 2025 | 88.4 | 89.3 |
| HMMT 2025 | 86.1 | 83.6 |
| Codeforces | 2046 | 2121 |
| Aider-Polyglot | 76.1 | 74.5 |
| Agentic Tool Use | ||
| BrowseComp | 38.5 | 40.1 |
| BrowseComp-zh | 45.0 | 47.9 |
| SimpleQA | 96.8 | 97.1 |
| SWE Verified | 68.4 | 67.8 |
| SWE-bench Multilingual | 57.8 | 57.9 |
| Terminal-bench | 36.7 | 37.7 |
Update
- 2025.11.17: We have identified that previous versions of the inference demo code contained an implementation discrepancy in Rotary Position Embedding (RoPE) within the indexer module, potentially leading to degraded model performance. Specifically, the input tensor to RoPE in the indexer module requires a non-interleaved layout, whereas RoPE in the MLA module expects an interleaved layout. This issue has now been resolved. Please refer to the updated version of the inference demo code and take note of this implementation detail.
Open-Source Kernels
For TileLang kernels with better readability and research-purpose design, please refer to TileLang.
For high-performance CUDA kernels, indexer logit kernels (including paged versions) are available in DeepGEMM. Sparse attention kernels are released in FlashMLA.
How to Run Locally
HuggingFace
We provide an updated inference demo code in the inference folder to help the community quickly get started with our model and understand its architectural details.
First convert huggingface model weights to the the format required by our inference demo. Set MP to match your available GPU count:
cd inference
export EXPERTS=256
python convert.py --hf-ckpt-path ${HF_CKPT_PATH} --save-path ${SAVE_PATH} --n-experts ${EXPERTS} --model-parallel ${MP}Launch the interactive chat interface and start exploring DeepSeek's capabilities:
export CONFIG=config_671B_v3.2.json
torchrun --nproc-per-node ${MP} generate.py --ckpt-path ${SAVE_PATH} --config ${CONFIG} --interactiveSGLang
Installation with Docker
# H200
docker pull lmsysorg/sglang:dsv32
# MI350
docker pull lmsysorg/sglang:dsv32-rocm
# NPUs
docker pull lmsysorg/sglang:dsv32-a2
docker pull lmsysorg/sglang:dsv32-a3
Launch Command
python -m sglang.launch_server --model deepseek-ai/DeepSeek-V3.2-Exp --tp 8 --dp 8 --enable-dp-attentionvLLM
vLLM provides day-0 support of DeepSeek-V3.2-Exp. See the recipes for up-to-date details.
License
This repository and the model weights are licensed under the MIT License.
Citation
@misc{deepseekai2024deepseekv32,
title={DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention},
author={DeepSeek-AI},
year={2025},
}
Contact
If you have any questions, please raise an issue or contact us at service@deepseek.com.