autoresearch-claude-code
![]()
Autonomous experiment loop for Claude Code. Give it a goal, a benchmark, and files to modify — it loops forever: try ideas, measure results, keep winners, discard losers.
Port of pi-autoresearch as a pure skill — no MCP server, just instructions the agent follows with its built-in tools.
Install
Option A: Let Claude do it (easiest)
git clone https://github.com/drivelineresearch/autoresearch-claude-code.git ~/autoresearch-claude-code claude -p "Install the autoresearch plugin from ~/autoresearch-claude-code"
Claude will read the repo, run install.sh, and configure everything.
Option B: Plugin flag
# One-session test drive claude --plugin-dir /path/to/autoresearch-claude-code # Permanent — add to ~/.claude/settings.json: # { "plugins": ["~/autoresearch-claude-code"] } # Toggle on/off claude plugin disable autoresearch claude plugin enable autoresearch
Option C: Manual symlinks
git clone https://github.com/drivelineresearch/autoresearch-claude-code.git ~/autoresearch-claude-code cd ~/autoresearch-claude-code && ./install.sh
To remove: ./uninstall.sh
Quick Start
/autoresearch optimize test suite runtime
/autoresearch # resume existing loop
/autoresearch off # pause (in-session)
The agent creates a branch, writes a session doc + benchmark script, runs a baseline, then loops autonomously. Send messages mid-loop to steer the next experiment.
What Can You Optimize?
Anything with a measurable metric:
- ML models — R², RMSE, accuracy, F1 (see the OpenBiomechanics example)
- Code performance — runtime, memory usage, throughput
- Build systems — bundle size, compile time, dependency count
- Frontend — Lighthouse score, load time, CLS
- Prompt engineering — eval scores, parameter-golf
- Any script that outputs
METRIC name=numberto stdout
The only requirement: a bash command that runs your benchmark and prints METRIC name=number lines.
Example: Fastball Velocity Prediction
Included in examples/ — predicts fastball velocity from biomechanical data using the Driveline OpenBiomechanics dataset and a model zoo of 19 algorithms.
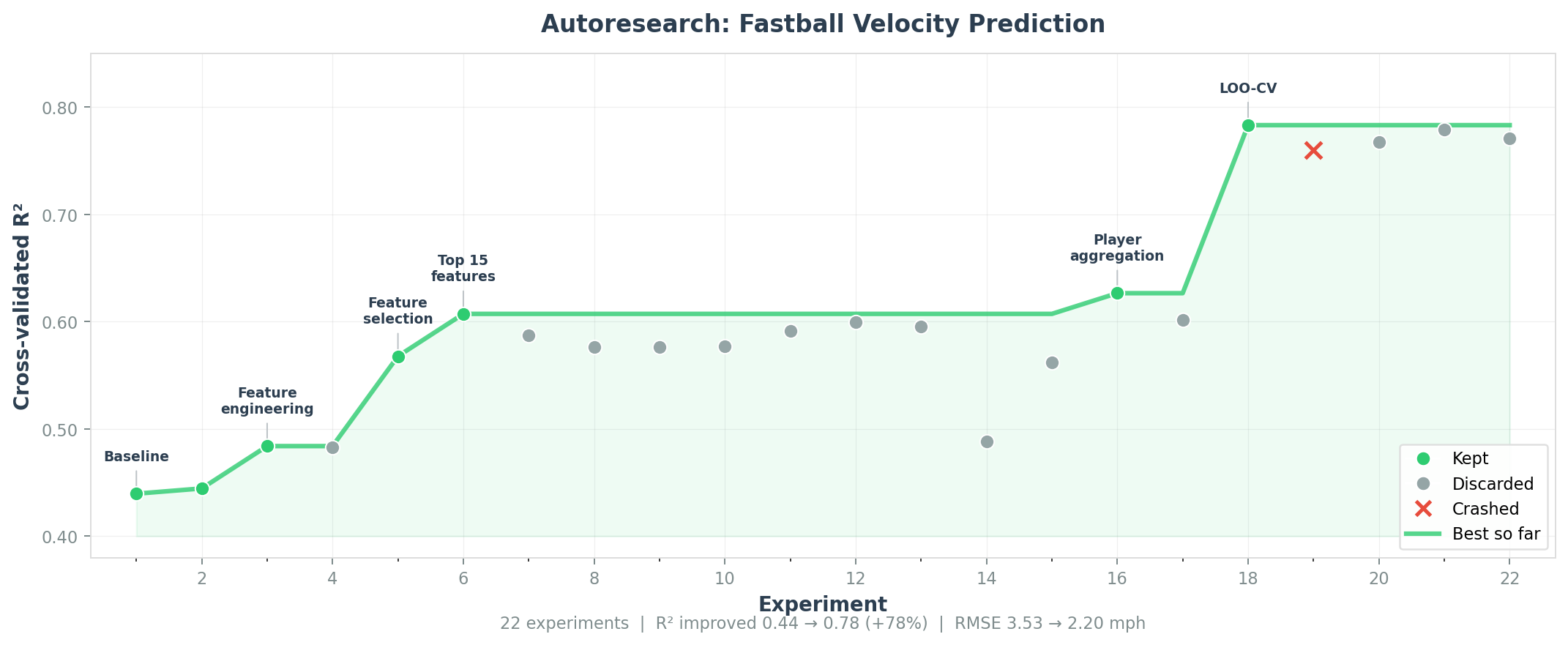
22 autonomous experiments took R² from 0.44 to 0.78 (+78%), predicting a new player's velocity within ~2 mph from biomechanics alone.
| Metric | Baseline | Best | Change |
|---|---|---|---|
| R² | 0.440 | 0.783 | +78% |
| RMSE | 3.53 mph | 2.20 mph | -38% |
Setup
# Clone data mkdir -p third_party git clone https://github.com/drivelineresearch/openbiomechanics.git third_party/openbiomechanics # Install dependencies with uv (https://docs.astral.sh/uv/) cd examples uv sync # core deps (xgboost, sklearn, rich, etc.) uv sync --extra all # all model backends (PyTorch, CatBoost, LightGBM, TabPFN, TabNet) # Copy example files to working directory and run cd .. cp examples/train.py examples/models.py examples/autoresearch.sh . uv run python train.py
See examples/obp-autoresearch.md for the session config and experiments/worklog.md for the full experiment narrative.
Model Zoo
The example ships with 19 models the agent can swap between. All use a common interface — change MODEL_TYPE in train.py to switch.
| Category | Models | GPU | Extra Deps |
|---|---|---|---|
| Boosting | xgboost, catboost, lightgbm, histgb | xgb/catboost/lgbm | catboost, lightgbm |
| Neural | pytorch_mlp, mc_dropout, ft_transformer, tabpfn, tabnet, mlp | torch-based | torch, tabpfn, pytorch-tabnet |
| Linear | ridge, elasticnet, lasso, huber | — | — |
| Bayesian | bayesian_ridge, gp | — | — |
| Other | svr, knn | — | — |
| Ensemble | stacking | — | — |
Models use lazy imports — missing optional deps produce clear error messages, not crashes. Install what you need:
uv sync # core (xgboost, sklearn, rich) uv sync --extra torch # + PyTorch/CUDA models uv sync --extra boost # + CatBoost, LightGBM uv sync --extra all # everything
GPU is auto-detected. When CUDA is available, XGBoost/CatBoost/LightGBM/PyTorch models use it automatically.
How It Works
| pi-autoresearch (MCP) | This port (Plugin) |
|---|---|
init_experiment tool | Agent writes config to autoresearch.jsonl |
run_experiment tool | Agent runs ./autoresearch.sh with timing |
log_experiment tool | Agent appends result JSON, git commit on keep |
| TUI dashboard | autoresearch-dashboard.md |
before_agent_start hook | UserPromptSubmit hook injects context |
State lives in autoresearch.jsonl. Session artifacts (*.jsonl, dashboard, session doc, benchmark script, ideas backlog, worklog) are gitignored.
Project Structure
.claude-plugin/plugin.json # Plugin manifest
skills/autoresearch/SKILL.md # Core skill: setup, JSONL protocol, run/log/loop logic
commands/autoresearch.md # /autoresearch slash command (start, resume, off)
hooks/hooks.json # Hook definitions (plugin format)
hooks/autoresearch-context.sh # UserPromptSubmit hook — injects context when active
install.sh / uninstall.sh # Manual symlink install (alternative to plugin)
examples/ # Demo: fastball velocity prediction
train.py # Training script with rich TUI output
models.py # Model registry (19 models, GPU detection)
pyproject.toml # uv project config with dependency groups
obp-autoresearch.md # Session config for the OBP demo
autoresearch.sh # Benchmark runner