HoldSpeak

One local copilot, two modes: dictation that types anywhere and learns how you work, and meetings that end with decisions, actions, and follow-ups instead of a recording. Nothing leaves your machine.
![]()
![]()
![]()
![]()
Your voice does work in two places: at the keyboard and in meetings. HoldSpeak covers both with one runtime on macOS and Linux. Hold a hotkey, speak, release, and the text lands in whatever app you are in, optionally rewritten by your own LLM with your project's context. Record or import a meeting, and it comes back as reviewable decisions, action items, and typed artifacts, with a follow-up panel that shows what is still open. Whisper runs locally; the LLM is one you run or point at. No cloud, no account, no telemetry.
Status: 0.x, early but real. HoldSpeak is on PyPI (
pip install holdspeak). The features are mature; APIs, config, and defaults can still change while it is pre-1.0. Upgrades are safe by default (your data is backed up first). Feedback and contributions welcome.
The two modes
| Dictate | Meet |
|---|---|
 |  |
Hold the hotkey, speak, release: the text goes into the active app. Turn on the dictation pipeline and rough speech is routed by intent, enriched with your project's context, and rewritten for its target (Codex, Claude, the terminal, the browser, your editor). Every run lands in the dictation journal; one tap on a wrong result teaches the correction memory. Voice commands map a spoken keyword to a real action (open a URL, launch an app, run a command). Say the wake phrase and it listens hands-free, with the result previewed, never typed, until you confirm. The spoken language setting pins any of Whisper's 99 languages, and the spoken-symbol dictionary types your own vocabulary ("double colon" becomes ::). Activity pre-briefing offers what you touched recently as dictation context, source-cited. | Capture mic and system audio live with speaker labels, or import a recording or a transcript file you already have (vtt and srt keep their real timestamps and speaker names). 14 built-in plugins call your LLM to pull typed artifacts out of the transcript: decisions, action items, ADRs, risk registers, incident timelines. Meeting aftercare then shows what is open, decided, and changed since last time; an accepted action can become a filed issue, and the digest or follow-up draft can go to your team through Send to Slack, all on a propose, approve, execute flow that never acts without you. The archive is searchable and filterable by date, speaker, tag, and open actions. |
This is what they look like in the product, not in pixel art. A saved meeting comes back as typed, reviewable artifacts:
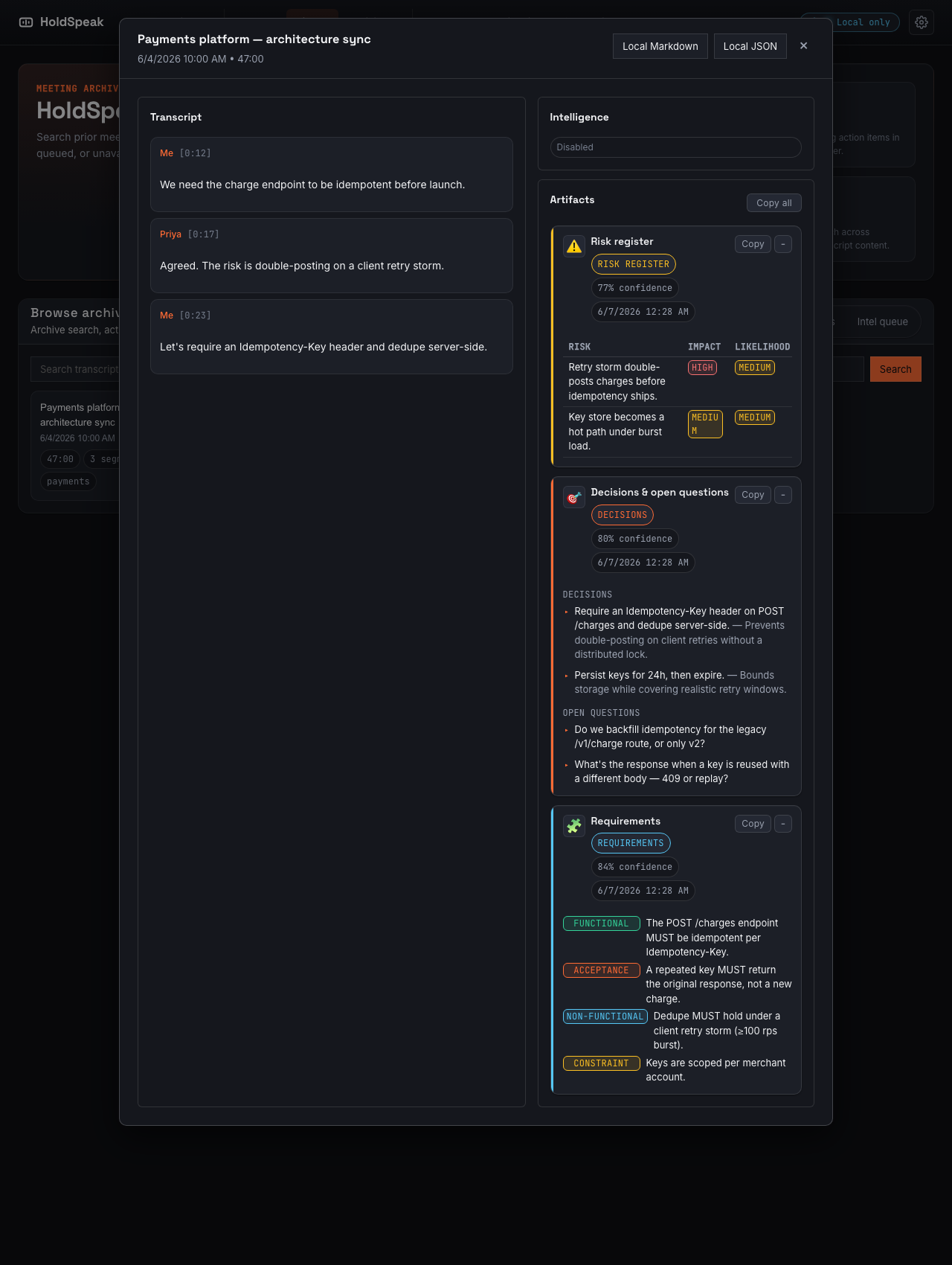
A meeting after intelligence ran: a risk register, decisions, and requirements, each extracted by an LLM-backed plugin and rendered read-only at /history.
Why it's different
- Everything is local, including the intelligence. Whisper transcribes on your machine, in any of its 99 languages, and the LLM is yours: GGUF in-process, MLX on Apple Silicon, or any OpenAI-compatible endpoint you choose, including one on your own LAN. See Security & privacy and Models.
- It learns how you work, and shows you the receipts. The dictation journal records what you said, what it typed, where it routed, and how long it took. Fix a wrong result in one tap and the correction memory learns; the learning digest reports a real "learned from N similar" count, honest at zero; replay an old utterance through the updated pipeline and watch the routing change. See the learning loop.
- Meetings end with their loops closed. A meeting produces artifacts, an aftercare digest, and approval-gated actions where most tools stop at a transcript. Actuators are off by default, audited, and only ever run exactly what you previewed. See meeting intelligence.
- Honest by construction.
holdspeak doctorreports what is actually broken. The import panel says which timestamps are approximate. The learning digest never inflates a count. Upgrades back your database up before touching it and refuse to open data written by a newer build. The docs hold themselves to the same bar.
See it learn

Because every dictation is recorded, you can look back at what it heard, fix a mistake in one tap (which teaches it), and replay the utterance through the updated pipeline. Instead of trusting that it improved, you watch it happen. See the full walkthrough.
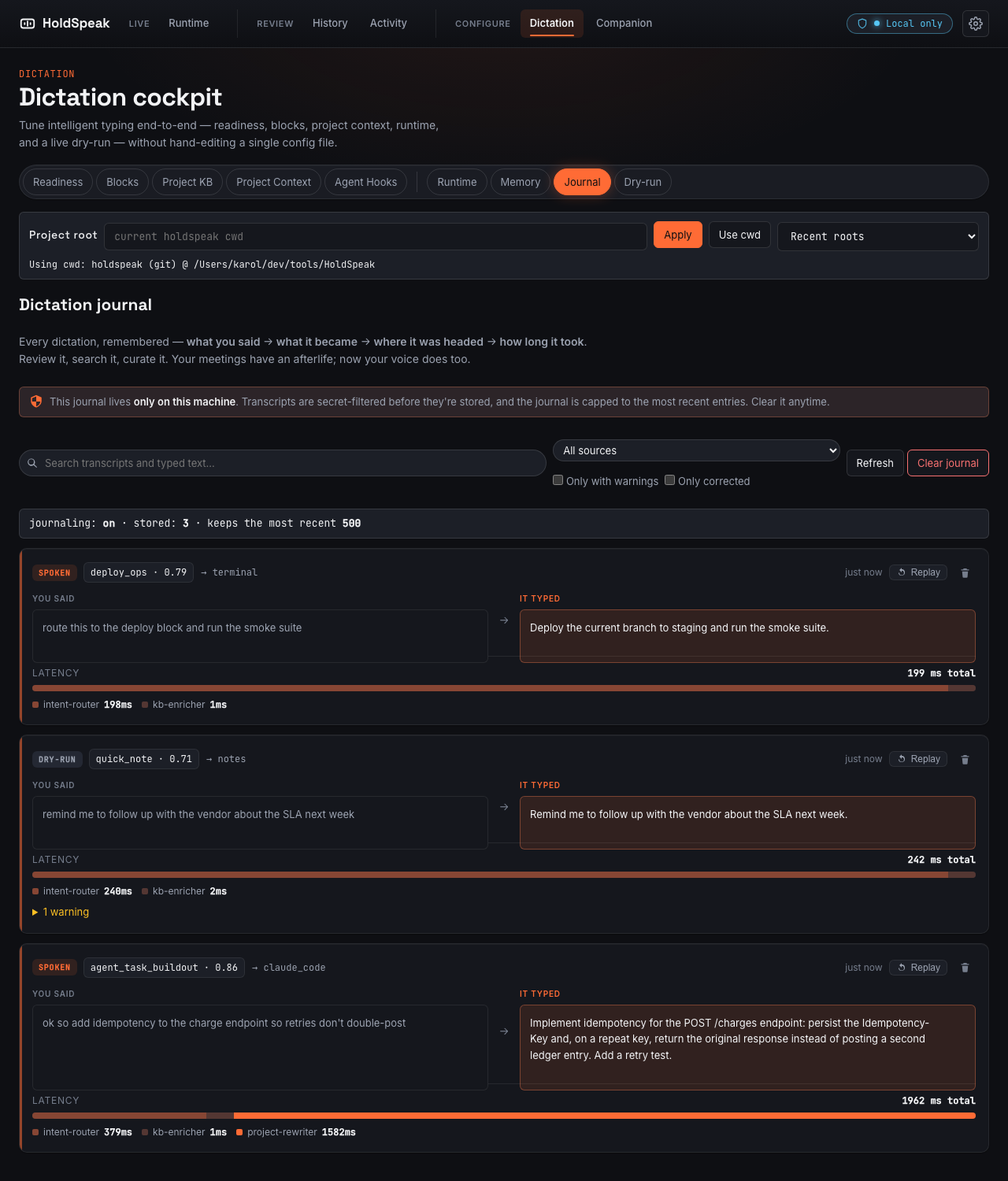
The dictation journal. Every utterance, with what you said, what it typed, where it routed, and how long it took.
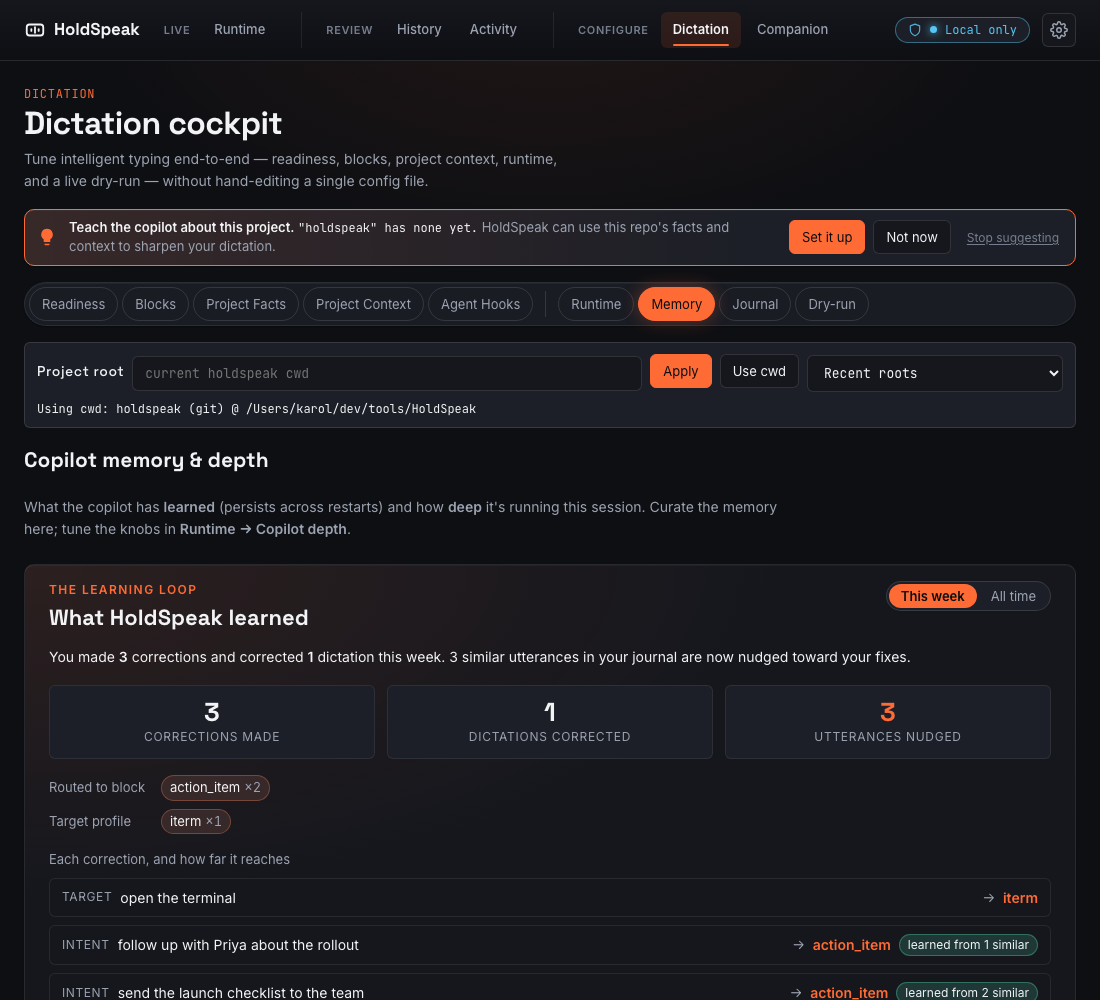
The learning digest. Honest, windowed counts from the same matcher that nudges your routing.
Meet Qlippy
![]()
Yes, he is a paperclip. The famous one had two problems: he interrupted you, and he could not actually do anything. Qlippy is the apology for both. He lives on the desktop presence surface (opt-in, two switches deep), spends most of his time as a tiny animated dock sprite mirroring what the runtime is doing, and slides out a card only for the few moments that genuinely need you: an action awaiting your approval, a correction that actually reached past dictations, a meeting that ended with open items.
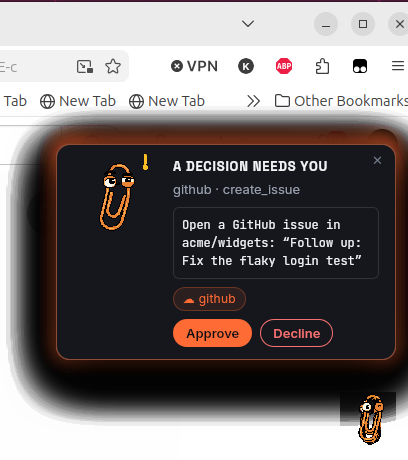
The marquee moment, on a real desktop: a proposed GitHub issue waiting for a decision. The native panel takes pointer clicks only while a card shows and can never steal keyboard focus.
He never acts on his own. Approving on his card sends the identical audited request the dashboard sends. Every card carries the egress badge, one small pill that says at a glance whether its data stays local or goes out, and to where. Dismissing him is always safe, and he is honest to a fault: the "Learned from you" card only ever appears when a correction really reached past dictations, with the real count.
| A decision needs you | Learned from you |
|---|---|
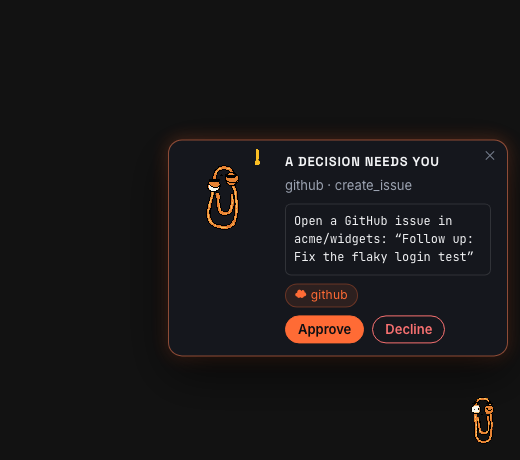 |  |
| The exact preview, the destination on the badge, your call. | Only when a correction really reached past dictations, with the honest count. Local only. |
Off by default, like everything ambient here. Turn him on under Settings, Desktop presence, "Qlippy, the mascot".
How it compares (as of mid-2026)
Honest comparisons, architecture-level on purpose: where your audio goes, what the tool spans, and whether it learns. These tools are good at what they do; pick the one that fits.
| Tool | What it does better | What HoldSpeak does better |
|---|---|---|
| OS dictation (Apple Dictation, Windows Voice Typing) | Zero setup, free, always available | Your own models, LLM rewriting with project context, the learning loop, meetings |
| Local Whisper apps (superwhisper, MacWhisper, VoiceInk) | Simpler setup, polished single-purpose UX | The LLM stays local too (their AI modes often call cloud APIs), a visible learning loop, meeting intelligence, Linux support |
| AI dictation services (Wispr Flow, Aqua Voice) | Out-of-box accuracy and editing polish, no model management | Your voice never leaves your machine, open source, no subscription, meetings |
| Talon | The deepest hands-free coding and computer control there is | Prose-first dictation with LLM rewriting, lower learning curve, meeting intelligence |
| Raw Whisper tooling (whisper.cpp scripts) | Total control, minimal surface | A product: typing integration, routing, the journal, meetings, a web UI |
And the trade-offs in the other direction: HoldSpeak is 0.x, the smart parts need a model you provide, setup is heavier than a menu-bar app, there is no Windows build today, and Wayland limits global hotkeys to best effort.
Quickstart
Install from PyPI, check your setup, and launch the web runtime:
pip install holdspeak holdspeak doctor # check mic permissions and backends holdspeak # launch the web runtime
Prefer uv? uv pip install holdspeak.
Or use the install script (creates an isolated venv and a holdspeak launcher),
or work from a clone:
# one-line install curl -fsSL https://raw.githubusercontent.com/karolswdev/HoldSpeak/main/scripts/install.sh | bash # or from a clone (for development) git clone https://github.com/karolswdev/HoldSpeak.git && cd HoldSpeak uv pip install -e . holdspeak doctor && holdspeak
Install only the extras you need:
pip install 'holdspeak[meeting]' # meeting mode and AI intelligence pip install 'holdspeak[dictation-mlx]' # the dictation pipeline on Apple Silicon (MLX) pip install 'holdspeak[dictation-llama]' # the dictation pipeline, cross-platform (GGUF) pip install 'holdspeak[dictation-openai]' # the dictation pipeline via an OpenAI-compatible endpoint
(From a clone, use the editable form instead, e.g. uv pip install -e '.[meeting]'.)
The dictation and meeting LLM is yours to choose. See
docs/MODELS.md for the contract and current suggestions.
Upgrading and your data
Your whole HoldSpeak database is a single SQLite file. Before a version jump you
can snapshot it with holdspeak backup, and put one back with holdspeak restore. Upgrades are safe by default: HoldSpeak backs up an older database
before it touches it, and refuses to open a database written by a newer build
rather than risk your data. holdspeak doctor reports the schema and config
state it found. The full policy is in
docs/RELEASING.md.
Platform support
| Capability | macOS 14+ (Apple Silicon) | Linux X11 | Linux Wayland |
|---|---|---|---|
| Voice typing | ✅ | ✅ | ✅ |
| Global hotkey | ✅ | ✅ | ⚠️ Best effort |
| Cross-app typing | ✅ | ✅ | ⚠️ Best effort |
| Meeting mode | ✅ | ✅ | ✅ |
| System audio capture | ✅ BlackHole | ✅ Pulse/PipeWire | ✅ Pulse/PipeWire |
Wayland often blocks global hooks and synthetic typing, so HoldSpeak falls back to clipboard paste for injection.
Meeting intelligence, a little deeper
Record a meeting live, or bring one you already have: import a recording
(WAV out of the box; compressed formats with ffmpeg) or a transcript file
(.vtt, .srt, .txt) from the archive page or with holdspeak import call.wav, and it becomes a real meeting, run through the same intelligence.
The transcript is scored for intent (architecture, delivery, product,
incident, comms), a chain of plugins runs, and each one calls your LLM to
produce a typed artifact. The results render read-only at /history.
HoldSpeak ships 14 built-in plugins, all real and backed by an LLM.
Plugins can also propose actions. An actuator proposes an external side effect, like filing a ticket or posting an update, that only runs after you approve it for that specific action. Actuators are off by default. Write your own with the Plugin Authoring guide; for endpoints and routing, see the Meeting Mode Guide.
Then close the loop. Meeting aftercare shows what is still open (by owner), what was decided, and what changed since the last meeting. Jump to the transcript moment that justifies any result, file an accepted action as a human-approved issue through that same actuator flow, or draft a copyable follow-up. It is read-only and local: nothing is sent, and nothing runs, without your approval. See the Meeting Mode Guide.
AIPI-Lite companion

AIPI-Lite is an optional ESPHome-based device you can carry between rooms. Put it on Wi-Fi (a phone hotspot works), and it gives you meeting-capture controls and status feedback. With Claude/Codex hooks on, it tells you when an agent is waiting so you can speak the reply back into the coding session. Buy the hardware from the official page or the Amazon listing; firmware and bridge setup are in the AIPI-Lite Developer Workflow.
Where to go next
| I want to… | Read this |
|---|---|
| Browse all the docs | Documentation index |
| Understand how it works, with diagrams | Architecture |
| Get it running and verify my setup | Getting Started |
| Choose / configure a model | Models (bring your own) |
| See speech become a project-grounded task | The Dictation Copilot |
| Set up the dictation pipeline for Codex / Claude | Intelligent Typing Setup |
| Review, correct, and replay past dictations | The dictation journal & replay |
| Map spoken keywords to real actions | Voice Commands |
| Turn on Qlippy, the mascot | Qlippy |
| Use meeting mode and configure AI intelligence | Meeting Mode Guide |
| Wire up the AIPI-Lite companion | AIPI-Lite Developer Workflow |
| Install Claude / Codex agent hooks | Agent Hook Install |
| Understand what's stored and what can leave my machine | Security & Privacy |
Configuration
Config lives at ~/.config/holdspeak/config.json, but you rarely edit it by hand.
The Settings page in the web runtime exposes the hotkey, model, meeting intel,
dictation pipeline, and presence options. The full reference is in
Getting Started and the guides above.
Contributing
Contributions are welcome. See CONTRIBUTING.md for setup
(uv, the git hooks, the test command) and the commit-contract workflow. Recent
changes are in CHANGELOG.md. If you want to build on
HoldSpeak rather than just use it, the
Plugin Authoring guide and
Connector Development are the doors in.
License
Licensed under the Apache License 2.0. See LICENSE.