superpowers-bench

Can your agent pick the right skill without being told?
You give your agent a set of skills. You describe a task. Does it figure out which skills to use - or does it need hand-holding?
superpowers-bench measures how well coding agents (Claude Code, Codex, OpenCode) discover and invoke skills from obra/superpowers based on context alone. It tests two conditions: no hints (just the task prompt) and with hints (task prompt + a natural-language hint that implies the right workflow without naming it).
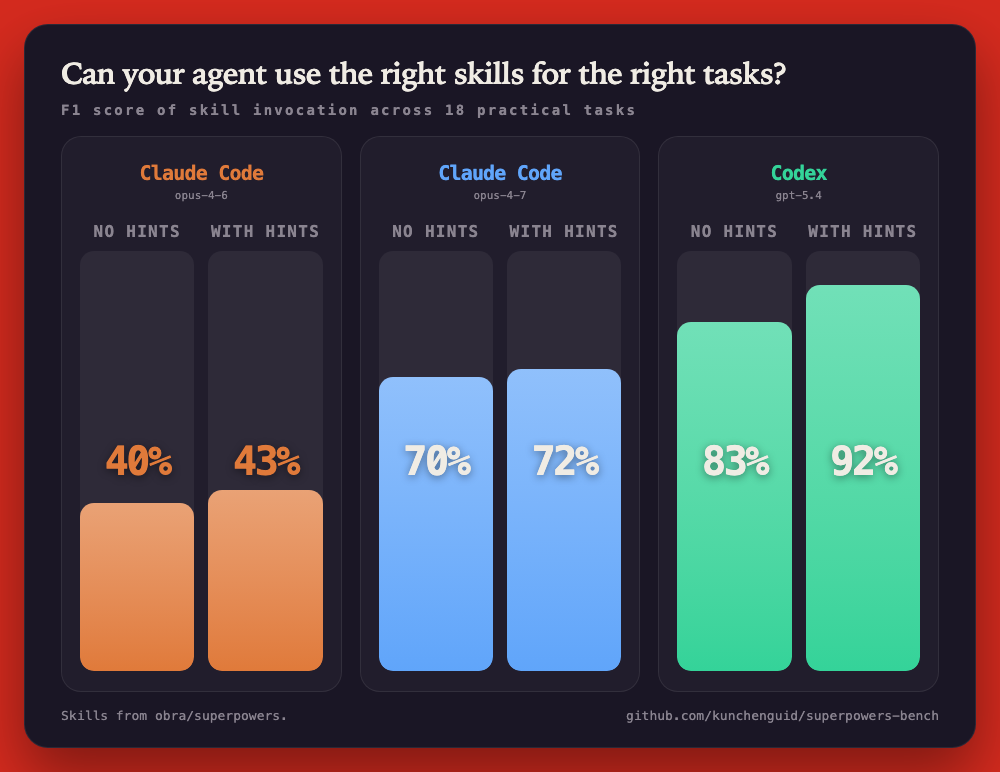
- Skill selection as the unit of measure - not code quality, not pass/fail on tests. Did the agent reach for the right tools?
- Apples-to-apples comparison - same 20 tasks, same skills, same grading. Just swap the agent.
- Baseline vs triggered - quantifies how much a well-written hint improves skill discovery without explicit instruction.
Quick Start
$ npm install $ npm run fetch-skills # download skill definitions $ npm run bench -- run --condition claude --task explain_code # ... agent runs, result appended to results/results.jsonl $ npm run bench -- matrix --parallel 4 # run full benchmark $ npm run bench -- report # generate report
Install
From source (only method - this is a benchmarking tool, not a published package):
git clone https://github.com/kunchenguid/superpowers-bench.git cd superpowers-bench npm install npm run fetch-skills
Prerequisites: Node.js 16+, and at least one supported agent CLI on your PATH with valid API credentials: claude (Claude Code CLI), codex (OpenAI Codex CLI), or opencode (OpenCode CLI).
How It Works
┌──────────────────────────────────────────────────┐
│ CLI: run / matrix / report │
└──────────────────┬───────────────────────────────┘
▼
┌──────────────────────────────────────────────────┐
│ Runner │
│ 1. Clone target repo into isolated workspace │
│ 2. Copy skill definitions into workspace │
│ 3. Build prompt (+ trigger hint if triggered) │
│ 4. Execute agent (multi-turn, auto-respond x3) │
│ 5. Detect which skills were invoked │
│ 6. Grade: precision / recall / F1 vs expected │
│ 7. Append result to results.jsonl │
└──────────────────────────────────────────────────┘
▼
┌──────────────────────────────────────────────────┐
│ Reporter │
│ Load results.jsonl ► markdown tables │
│ Summary by condition, per-task, per-skill │
└──────────────────────────────────────────────────┘
- Isolated workspaces - each parallel worker gets its own git copy of the target repo to prevent interference
- Detection method - Claude: parsed from
Skilltool_use events. Codex/OpenCode: fingerprint matching against distinctive phrases from skill bodies - Grading - set comparison between detected and expected skills. Pass = no missing, no extra
CLI Reference
| Command | Description |
|---|---|
npm run bench run | Execute a single condition x task combination |
npm run bench matrix | Run full benchmark matrix across all combos |
npm run bench report | Generate markdown report from results.jsonl |
npm run fetch-skills | Download skill definitions from superpowers |
run and matrix start from a fresh results/ directory. report always reflects the latest benchmark batch, not an append-only history.
Flags
| Command | Flag | Description |
|---|---|---|
run | --condition <id> | Condition to run (required) |
run | --task <id> | Task to run (required) |
run | --repeat <n> | Number of repetitions (default: 1) |
matrix | --parallel <n> | Max concurrent workers (default: 4) |
matrix | --condition <id> | Filter to one condition |
matrix | --task <id> | Filter to one task |
matrix | --repeat <n> | Repeats per combination (default: 1) |
Configuration
All config lives in config/:
conditions.yaml- defines agent variants (agent, model, triggered flag)tasks.yaml- 20 tasks with prompts, expected skills, and trigger hintsfingerprints.yaml- distinctive phrases for Codex/OpenCode skill detection
Conditions
| ID | Agent | Model | Triggered |
|---|---|---|---|
claude | Claude | claude-opus-4-6 | no |
claude-triggered | Claude | claude-opus-4-6 | yes |
claude-opus-4-7 | Claude | claude-opus-4-7 | no |
claude-opus-4-7-triggered | Claude | claude-opus-4-7 | yes |
codex | Codex | gpt-5.4 | no |
codex-triggered | Codex | gpt-5.4 | yes |
opencode-gpt-5-4 | OpenCode | openai/gpt-5.4 | no |
opencode-gpt-5-4-triggered | OpenCode | openai/gpt-5.4 | yes |
Development
npm install # install dependencies npm run fetch-skills # download skill definitions npm run bench # run CLI (see subcommands above)