Sirchmunk: Raw data to self-evolving intelligence, real-time.
Quick Start · Key Features · MCP Server · Web UI · Docker · How it Works · FAQ
🔍 Agentic Search • 🧠 Knowledge Clustering • 📊 Monte Carlo Evidence Sampling
⚡ Indexless Retrieval • 🔄 Self-Evolving Knowledge Base • 💬 Real-time Chat
🌰 Why “Sirchmunk”?
Intelligence pipelines built upon vector-based retrieval can be rigid and brittle. They rely on static vector embeddings that are expensive to compute, blind to real-time changes, and detached from the raw context. We introduce Sirchmunk to usher in a more agile paradigm, where data is no longer treated as a snapshot, and insights can evolve together with the data.
✨ Key Features
1. EmbeddingDB-Free: Data in its Purest Form
Sirchmunk works directly with raw data -- bypassing the heavy overhead of squeezing your rich files into fixed-dimensional vectors.
- Instant Search: Eliminating complex pre-processing pipelines in hours long indexing; just drop your files and search immediately.
- Full Fidelity: Zero information loss —- stay true to your data without vector approximation.
2. Self-Evolving: A Living Index
Data is a stream, not a snapshot. Sirchmunk is dynamic by design, while vector DB can become obsolete the moment your data changes.
- Context-Aware: Evolves in real-time with your data context.
- LLM-Powered Autonomy: Designed for Agents that perceive data as it lives, utilizing token-efficient reasoning that triggers LLM inference only when necessary to maximize intelligence while minimizing cost.
3. Intelligence at Scale: Real-Time & Massive
Sirchmunk bridges massive local repositories and the web with high-scale throughput and real-time awareness.
It serves as a unified intelligent hub for AI agents, delivering deep insights across vast datasets at the speed of thought.
For more technical details, refer to the Sirchmunk blog
Traditional RAG vs. Sirchmunk
Demonstration
Access files directly to start chatting
| WeChat Group | DingTalk Group |
|---|---|
 |  |
🎉 News
-
🚀 Jun 18, 2026: Sirchmunk v0.0.8
- Knowledge Compile (Beta): New
sirchmunk compilecommand for offline document pre-processing — builds hierarchical tree indices and knowledge clusters to boost retrieval precision in both FAST and DEEP modes. - Search pipeline integration: Compile artifacts (tree indices, document catalog, summary index) are automatically detected and used by the search pipeline when available; graceful fallback to standard retrieval when absent.
- Health check utility:
sirchmunk compile --lintperforms system-level knowledge integrity checks with optional--fixfor auto-repair. - I/O optimization: File hash reuse across the pipeline to eliminate redundant I/O; configurable model names and processing limits replace previous hardcoded values.
- Knowledge Compile (Beta): New
-
🚀 Apr 13, 2026: Sirchmunk v0.0.7
- C/S deployment hardening: Strict
allowed_pathsenforcement with symlink detection for remote mode; per-IP rate limiting and JSON Lines audit logging; local mode remains unrestricted for backward compatibility. - Remote file upload: Three-mode upload UI (Select Files / Select Folder / drag-and-drop); server-side pre-upload duplicate detection with skip/overwrite options; manifest-based storage accounting.
- Server file browser:
FileBrowserdefaults to serverdata/directory; manual path input validated againstallowed_paths; permission-aware error messages for remote access control. - Init alignment:
sirchmunk initgenerates.envfully aligned withconfig/env.example, covering all C/S deployment variables.
- C/S deployment hardening: Strict
-
🚀 Mar 31, 2026: Sirchmunk v0.0.6post3
- Docker multi-arch: Native
linux/amd64andlinux/arm64images via Docker Buildx; CI builds both architectures automatically. - FAST mode: File-level deduplication and dynamic score pruning in
_fast_find_best_file; scope-aware knowledge cluster reuse.
- Docker multi-arch: Native
-
🚀 Mar 20, 2026: Sirchmunk v0.0.6post1
- 🐿️x🦞OpenClaw skill: Sirchmunk is now available as an OpenClaw skill on ClawHub — any OpenClaw-compatible agent can search local files via natural language. See openclaw-recipe for details.
- Search API: New SSE streaming endpoint (
POST /api/v1/search/stream) for real-time log output; concurrency control viaSIRCHMUNK_MAX_CONCURRENT_SEARCHES;pathsparameter now accepts both string and array, and is optional (falls back toSIRCHMUNK_SEARCH_PATHS). - Dependency fix:
sirchmunk serveno longer requiressirchmunk[web]—uvicornis now a core dependency;psutilmade optional.
-
🚀 Mar 12, 2026: Sirchmunk v0.0.6
- Multi-turn conversation: Context management with LLM query rewriting; configs
CHAT_HISTORY_MAX_TURNS/CHAT_HISTORY_MAX_TOKENS; default search token budget 128K - Document summarization & cross-lingual retrieval: Summarization pipeline (chunk/merge/rerank), cross-lingual keyword extraction, chat-history relevance filtering
- Docker:
SIRCHMUNK_SEARCH_PATHSenv support; updated entrypoint; document-processing dependencies - OpenAI client:
_ProviderProfilefor multi-provider management; auto-detect frombase_url; unified streaming;thinking_contentsupport
- Multi-turn conversation: Context management with LLM query rewriting; configs
Older releases (v0.0.2 – v0.0.5)
-
🚀 Mar 5, 2026: Sirchmunk v0.0.5
- Breaking Change: Unified Search API: Streamlined search() interface with a new SearchContext object and simplified parameter control (return_context).
- Robust RAG Chat: Significantly improved conversational reliability through new retry mechanisms and granular exception handling.
- Stable MCP Integration: Fixed mcp run initialization issues, ensuring seamless server deployment for Model Context Protocol users.
- PyPI Web UI Fix: Corrected Next.js source bundling to support flawless Web UI startup for standard pip install users.
-
🚀 Feb 27, 2026: Sirchmunk v0.0.4
- Docker Support: First-class Docker deployment with pre-built images for seamless containerized setup.
- FAST Search Mode: New default greedy search mode using 2-level keyword cascade and context-window sampling — significantly faster retrieval with only 2 LLM calls (2-5s vs 10-30s).
- Simplified Deployment: Streamlined CLI and Web UI configuration workflows for quicker onboarding.
- Windows Compatibility: Fixed compatibility issues for Windows environments.
-
🚀 Feb 12, 2026: Sirchmunk v0.0.3: Upgraded MCP Integration & Core Search Algorithms
- MCP Boost: Enhanced Model Context Protocol support with updated setup guides.
- Granular Search: Added glob pattern (include/exclude) support; auto-filters temp/cache files.
- New Docs: Deep dives into "Monte Carlo Evidence Sampling" and "Self-Evolving Knowledge Clusters."
- System Stability: Refactored search pipeline and implemented SHA256 deterministic IDs for Knowledge Clusters.
-
🚀 Feb 5, 2026: Release v0.0.2 — MCP Support, CLI Commands & Knowledge Persistence!
- MCP Integration: Full Model Context Protocol support, works seamlessly with Claude Desktop and Cursor IDE.
- CLI Commands: New
sirchmunkCLI withinit,serve,search,web, andmcpcommands. - KnowledgeCluster Persistence: DuckDB-powered storage with Parquet export for efficient knowledge management.
- Knowledge Reuse: Semantic similarity-based cluster retrieval for faster searches via embedding vectors.
-
🎉🎉 Jan 22, 2026: Introducing Sirchmunk: Initial Release v0.0.1 Now Available!
🚀 Quick Start
Prerequisites
- Python 3.10+
- LLM API Key (OpenAI-compatible endpoint, local or remote)
- Node.js 18+ (Optional, for web interface)
Installation
# Create virtual environment (recommended) conda create -n sirchmunk python=3.13 -y && conda activate sirchmunk pip install sirchmunk # Or via UV: uv pip install sirchmunk # Alternatively, install from source: git clone https://github.com/modelscope/sirchmunk.git && cd sirchmunk pip install -e .
Python SDK Usage
import asyncio from sirchmunk import AgenticSearch from sirchmunk.llm import OpenAIChat llm = OpenAIChat( api_key="your-api-key", base_url="your-base-url", # e.g., https://api.openai.com/v1 model="your-model-name" # e.g., gpt-5.2 ) async def main(): searcher = AgenticSearch(llm=llm) # FAST mode (default): greedy search, 2 LLM calls, 2-5s result: str = await searcher.search( query="How does transformer attention work?", paths=["/path/to/documents"], ) # DEEP mode: comprehensive analysis with Monte Carlo sampling, 10-30s result_deep: str = await searcher.search( query="How does transformer attention work?", paths=["/path/to/documents"], mode="DEEP", ) print(result) asyncio.run(main())
⚠️ Notes:
- Upon initialization,
AgenticSearchautomatically checks ifripgrep-allandripgrepare installed. If they are missing, it will attempt to install them automatically. If the automatic installation fails, please install them manually. - Replace
"your-api-key","your-base-url","your-model-name"and/path/to/documentswith your actual values.
Using with MiniMax
from sirchmunk.llm import OpenAIChat llm = OpenAIChat( api_key="your-minimax-api-key", base_url="https://api.minimax.io/v1", model="MiniMax-M3" # or "MiniMax-M2.7" / "MiniMax-M2.7-highspeed" )
Command Line Interface
Sirchmunk provides a powerful CLI for server management and search operations.
Installation
pip install "sirchmunk[web]" # or install via UV uv pip install "sirchmunk[web]"
Initialize
# Initialize Sirchmunk with default settings (Default work path: `~/.sirchmunk/`) sirchmunk init # Alternatively, initialize with custom work path sirchmunk init --work-path /path/to/workspace
Start Server
# Start backend API server only sirchmunk serve # Custom host and port sirchmunk serve --host 0.0.0.0 --port 8000
Search
# Search in current directory (FAST mode by default) sirchmunk search "How does authentication work?" # Search in specific paths sirchmunk search "find all API endpoints" ./src ./docs # DEEP mode: comprehensive analysis with Monte Carlo sampling sirchmunk search "database architecture" --mode DEEP # Quick filename search sirchmunk search "config" --mode FILENAME_ONLY # Output as JSON sirchmunk search "database schema" --output json # Use API server (requires running server) sirchmunk search "query" --api --api-url http://localhost:8584
Available Commands
| Command | Description |
|---|---|
sirchmunk init | Initialize working directory, .env, and MCP config |
sirchmunk serve | Start the backend API server |
sirchmunk search | Perform search queries |
sirchmunk web init | Build WebUI frontend (requires Node.js 18+) |
sirchmunk web serve | Start API + WebUI (single port) |
sirchmunk web serve --dev | Start API + Next.js dev server (hot-reload) |
sirchmunk mcp serve | Start the MCP server (stdio/HTTP) |
sirchmunk mcp version | Show MCP version information |
sirchmunk compile | Compile documents into knowledge indices (Beta) |
sirchmunk version | Show version information |
Knowledge Compile (Beta)
Pre-process document collections into hierarchical tree indices and knowledge clusters to improve retrieval accuracy. This is an optional step — search works without it, but compile artifacts can significantly boost precision for large document sets.
# Compile documents (incremental by default) sirchmunk compile --paths /path/to/documents # Full recompile (ignore cache) sirchmunk compile --paths /path/to/documents --full # Shallow mode (skip tree indexing, faster) sirchmunk compile --paths /path/to/documents --shallow # Check compile status sirchmunk compile --paths /path/to/documents --status # Run knowledge health checks sirchmunk compile --lint --work-path ~/.sirchmunk # Auto-fix lint issues sirchmunk compile --lint --fix --work-path ~/.sirchmunk
Note: This feature is in Beta. The compile artifacts are automatically detected by the search pipeline — no additional configuration is needed after compilation.
🔌 MCP Server
Sirchmunk provides a Model Context Protocol (MCP) server that exposes its intelligent search capabilities as MCP tools. This enables seamless integration with AI assistants like Claude Desktop and Cursor IDE.
Quick Start
# Install with MCP support pip install sirchmunk[mcp] # Initialize (generates .env and mcp_config.json) sirchmunk init # Optional: use a custom work path # sirchmunk init --work-path /path/to/your_work_path # Edit ~/.sirchmunk/.env with your LLM API key # Test with MCP Inspector npx @modelcontextprotocol/inspector sirchmunk mcp serve # Optional: use a custom work path for this MCP run # npx @modelcontextprotocol/inspector sirchmunk mcp serve --work-path /path/to/your_work_path
mcp_config.json Configuration
After running sirchmunk init, a ~/.sirchmunk/mcp_config.json file is generated. Copy it to your MCP client configuration directory.
Example:
{ "mcpServers": { "sirchmunk": { "command": "sirchmunk", "args": ["mcp", "serve"], "env": { "SIRCHMUNK_SEARCH_PATHS": "", "SIRCHMUNK_WORK_PATH": "/path/to/your_work_path" } } } }
| Parameter | Description |
|---|---|
command | The command to start the MCP server. Use full path (e.g. /path/to/venv/bin/sirchmunk) if running in a virtual environment. |
args | Command arguments. ["mcp", "serve"] starts the MCP server in stdio mode. |
env.SIRCHMUNK_SEARCH_PATHS | Default document search directories (comma-separated). Supports both English , and Chinese , as delimiters. When set, these paths are used as default if no paths parameter is provided during tool invocation. |
env.SIRCHMUNK_WORK_PATH | Sets the Sirchmunk working directory used by MCP server (.env, cache, knowledge, history). Recommended for persistent MCP clients. |
Tip: MCP Inspector is a great way to test the integration before connecting to your AI assistant. In MCP Inspector: Connect → Tools → List Tools →
sirchmunk_search→ Input parameters (queryandpaths, e.g.["/path/to/your_docs"]) → Run Tool. You can override the working directory temporarily withsirchmunk mcp serve --work-path /path/to/your_work_path.
Features
- Multi-Mode Search: FAST mode (default, greedy 2-5s), DEEP mode for comprehensive analysis, FILENAME_ONLY for fast file discovery
- Knowledge Cluster Management: Automatic extraction, storage, and reuse of knowledge
- Standard MCP Protocol: Works with stdio and Streamable HTTP transports
📖 For detailed documentation, see Sirchmunk MCP README.
🖥️ Web UI
The web UI is built for fast, transparent workflows: chat, knowledge analytics, and system monitoring in one place.
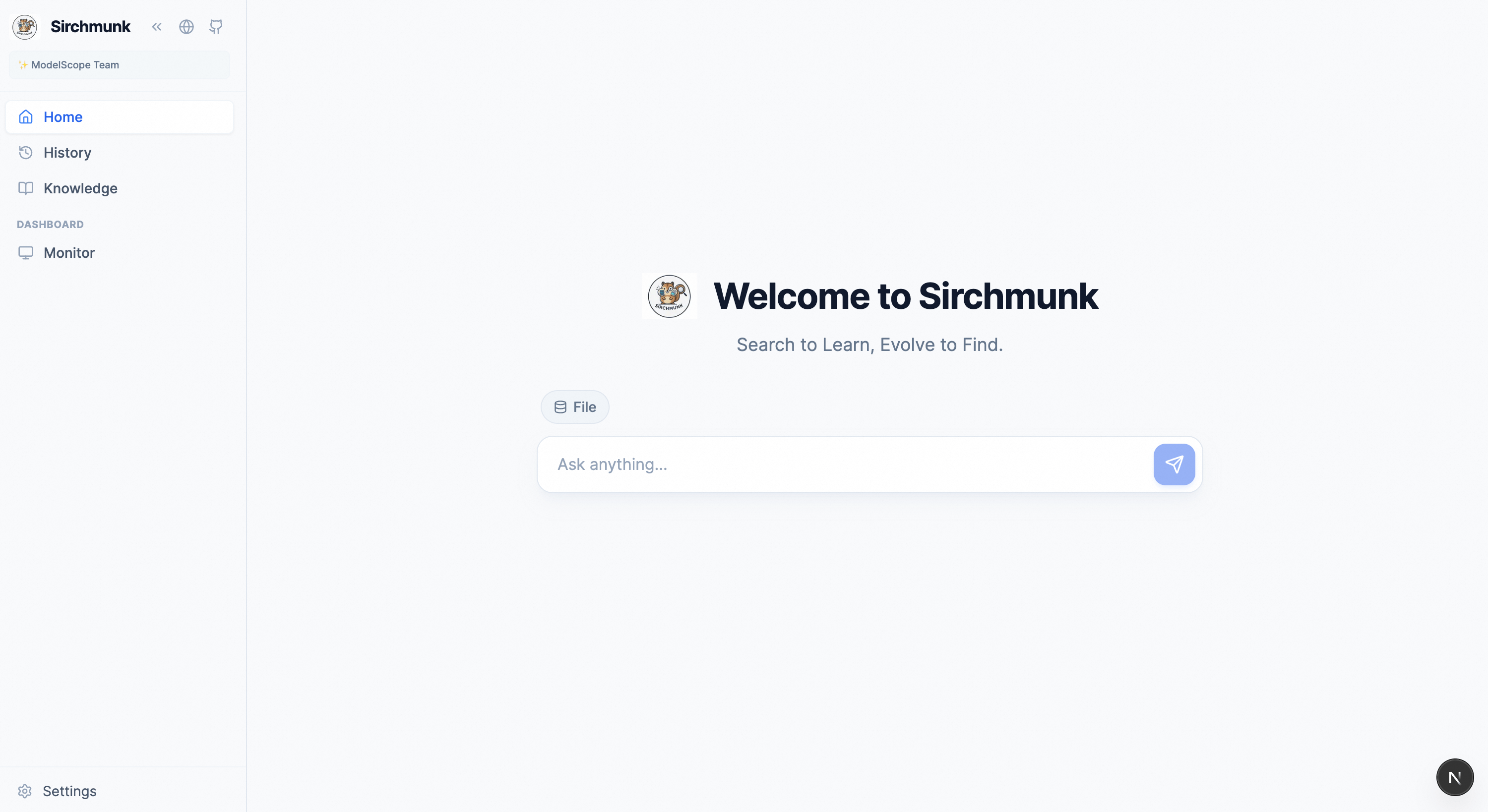
Home — Chat with streaming logs, file-based RAG, and session management.
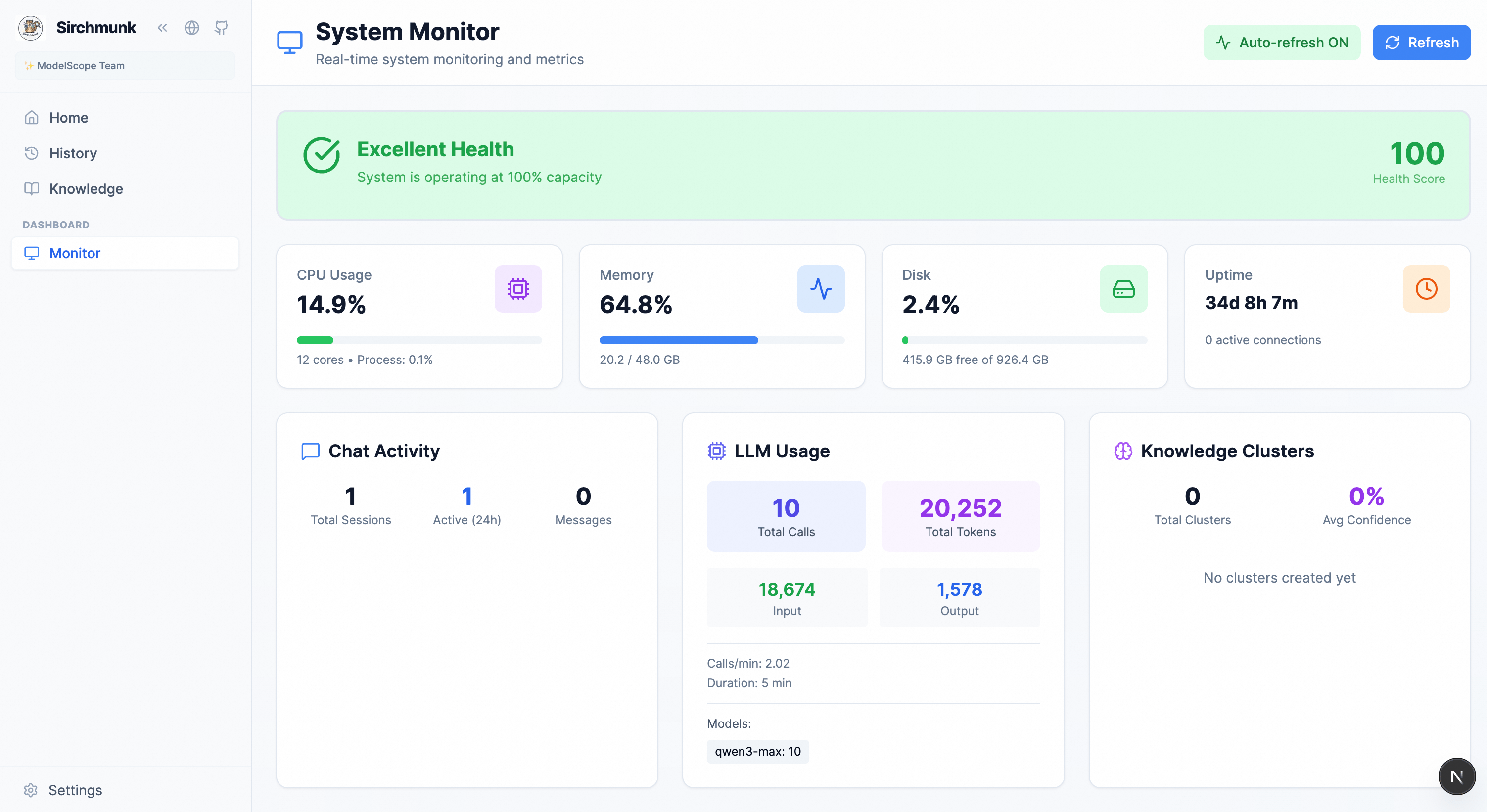
Monitor — System health, chat activity, knowledge analytics, and LLM usage.
Option 1: Single-Port Mode (Recommended)
Build the frontend once, then serve everything from a single port — no Node.js needed at runtime.
# Build WebUI frontend (requires Node.js 18+ at build time) sirchmunk web init # Start server with embedded WebUI sirchmunk web serve
Access: http://localhost:8584 (API + WebUI on the same port)
Option 2: Development Mode
For frontend development with hot-reload:
# Start backend + Next.js dev server sirchmunk web serve --dev
Access:
- Frontend (hot-reload): http://localhost:8585
- Backend APIs: http://localhost:8584/docs
Option 3: Legacy Script
# Start frontend and backend via script python scripts/start_web.py # Stop all services python scripts/stop_web.py
Configuration:
- Access
Settings→Envrionment Variablesto configure LLM API, and other parameters.
🐳 Docker Deployment
Pre-built Docker images are available on Alibaba Cloud Container Registry:
| Region | Image |
|---|---|
| US West | modelscope-registry.us-west-1.cr.aliyuncs.com/modelscope-repo/sirchmunk:ubuntu22.04-py312-0.0.7 |
| China Beijing | modelscope-registry.cn-beijing.cr.aliyuncs.com/modelscope-repo/sirchmunk:ubuntu22.04-py312-0.0.7 |
# Pull the image docker pull modelscope-registry.cn-beijing.cr.aliyuncs.com/modelscope-repo/sirchmunk:ubuntu22.04-py312-0.0.7 # Start the service docker run -d \ --name sirchmunk \ --cpus="4" \ --memory="2g" \ -p 8584:8584 \ -e LLM_API_KEY="your-api-key-here" \ -e LLM_BASE_URL="https://api.openai.com/v1" \ -e LLM_MODEL_NAME="gpt-5.2" \ -e LLM_TIMEOUT=60.0 \ -e UI_THEME=light \ -e UI_LANGUAGE=en \ -e SIRCHMUNK_VERBOSE=false \ -e SIRCHMUNK_ENABLE_CLUSTER_REUSE=false \ -e SIRCHMUNK_SEARCH_PATHS=/mnt/docs \ -v /path/to/your_work_path:/data/sirchmunk \ -v /path/to/your/docs:/mnt/docs:ro \ modelscope-registry.cn-beijing.cr.aliyuncs.com/modelscope-repo/sirchmunk:ubuntu22.04-py312-0.0.7 # Stop and remove the service docker stop sirchmunk && docker rm sirchmunk
Previous Releases
| Version | Region | Image |
|---|---|---|
| v0.0.6post3 | US West | modelscope-registry.us-west-1.cr.aliyuncs.com/modelscope-repo/sirchmunk:ubuntu22.04-py312-0.0.6post3 |
| v0.0.6post3 | China Beijing | modelscope-registry.cn-beijing.cr.aliyuncs.com/modelscope-repo/sirchmunk:ubuntu22.04-py312-0.0.6post3 |
| v0.0.4 | US West | modelscope-registry.us-west-1.cr.aliyuncs.com/modelscope-repo/sirchmunk:ubuntu22.04-py312-0.0.4 |
| v0.0.4 | China Beijing | modelscope-registry.cn-beijing.cr.aliyuncs.com/modelscope-repo/sirchmunk:ubuntu22.04-py312-0.0.4 |
Open http://localhost:8584 to access the WebUI, or call the API directly:
import requests response = requests.post( "http://localhost:8584/api/v1/search", json={ "query": "your search question here", "paths": ["/mnt/docs"], }, ) print(response.json())
📖 For full Docker parameters and usage, see docker/README.md.
🏗️ How it Works
Sirchmunk Framework
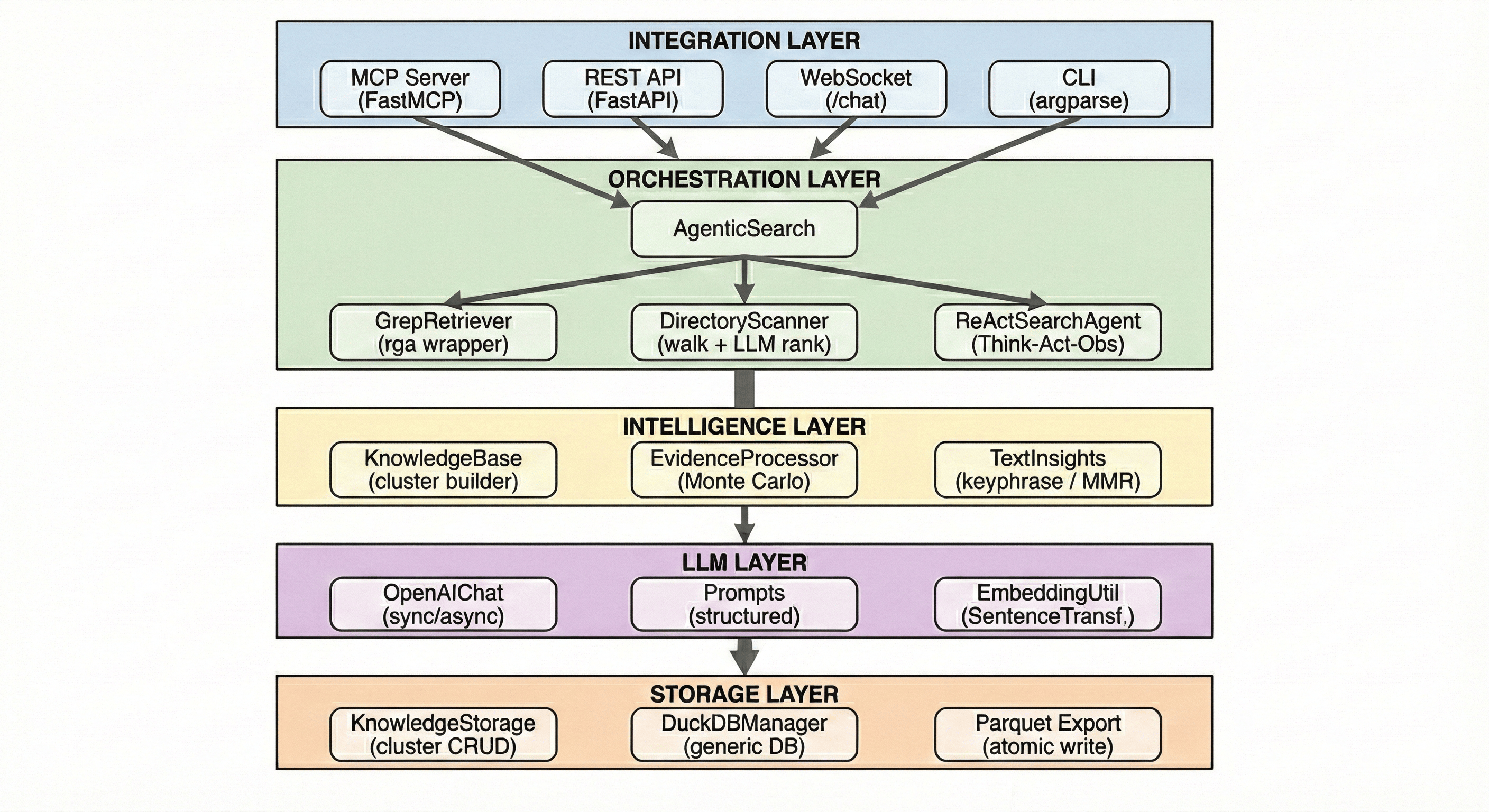
Core Components
| Component | Description |
|---|---|
| AgenticSearch | Search orchestrator with LLM-enhanced retrieval capabilities |
| KnowledgeBase | Transforms raw results into structured knowledge clusters with evidences |
| EvidenceProcessor | Evidence processing based on the MonteCarlo Importance Sampling |
| GrepRetriever | High-performance indexless file search with parallel processing |
| OpenAIChat | Unified LLM interface supporting streaming and usage tracking |
| MonitorTracker | Real-time system and application metrics collection |
Monte Carlo Evidence Sampling
Traditional retrieval systems read entire documents or rely on fixed-size chunks, leading to either wasted tokens or lost context. Sirchmunk takes a fundamentally different approach inspired by Monte Carlo methods — treating evidence extraction as a sampling problem rather than a parsing problem.
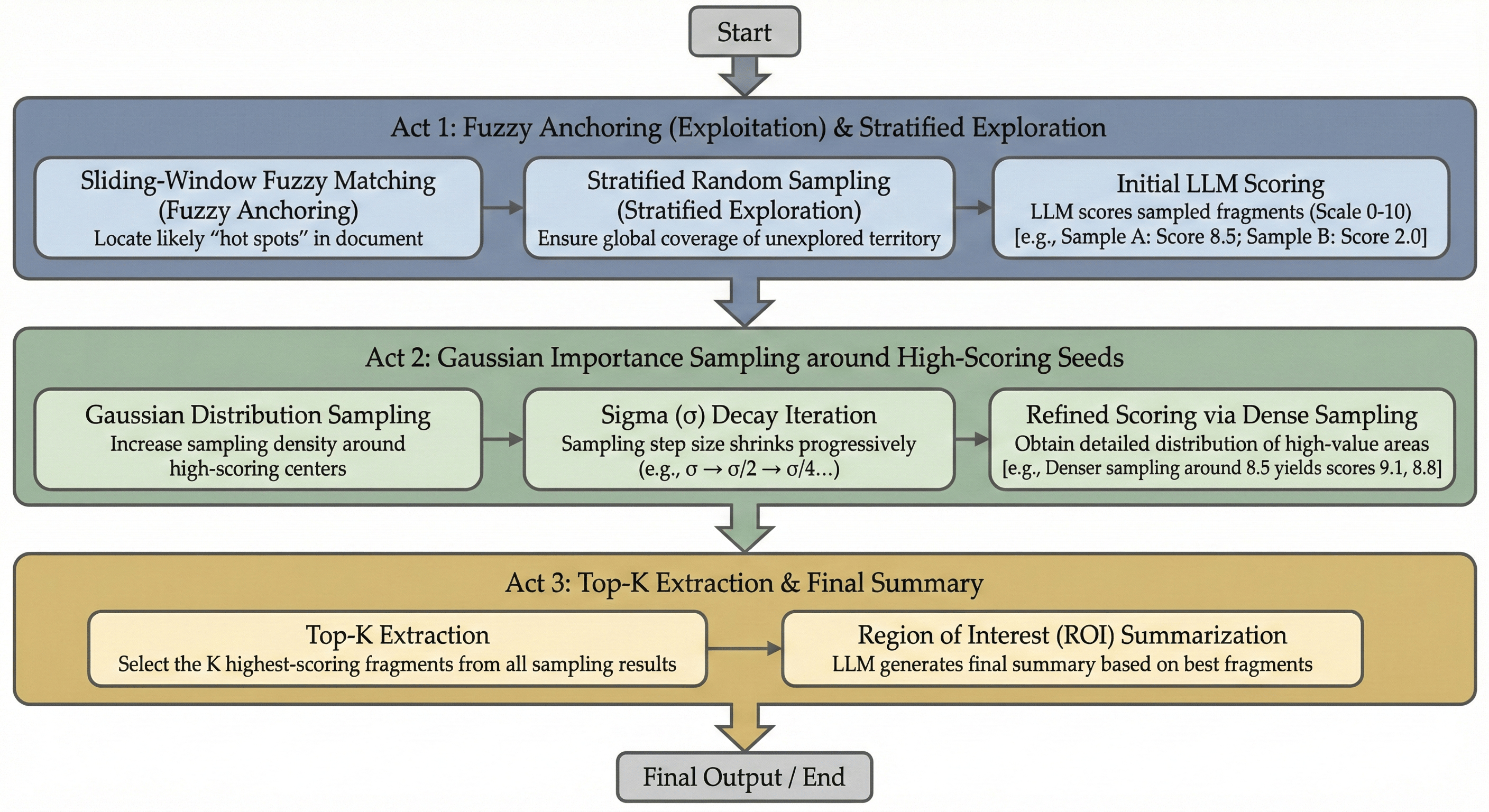
Monte Carlo Evidence Sampling — A three-phase exploration-exploitation strategy for extracting relevant evidence from large documents.
The algorithm operates in three phases:
-
Phase 1 — Cast the Net (Exploration): Fuzzy anchor matching combined with stratified random sampling. The system identifies seed regions of potential relevance while maintaining broad coverage through randomized probing — ensuring no high-value region is missed.
-
Phase 2 — Focus (Exploitation): Gaussian importance sampling centered around high-scoring seeds from Phase 1. The sampling density concentrates on the most promising regions, extracting surrounding context and scoring each snippet for relevance.
-
Phase 3 — Synthesize: The top-K scored snippets are passed to the LLM, which synthesizes them into a coherent Region of Interest (ROI) summary with a confidence flag — enabling the pipeline to decide whether evidence is sufficient or a ReAct agent should be invoked for deeper exploration.
Key properties:
- Document-agnostic: The same algorithm works equally well on a 2-page memo and a 500-page technical manual — no document-specific chunking heuristics needed.
- Token-efficient: Only the most relevant regions are sent to the LLM, dramatically reducing token consumption compared to full-document approaches.
- Exploration-exploitation balance: Random exploration prevents tunnel vision, while importance sampling ensures depth where it matters most.
Self-Evolving Knowledge Clusters
Sirchmunk does not discard search results after answering a query. Instead, every search produces a KnowledgeCluster — a structured, reusable knowledge unit that grows smarter over time. This is what makes the system self-evolving.
What is a KnowledgeCluster?
A KnowledgeCluster is a richly annotated object that captures the full cognitive output of a single search cycle:
| Field | Purpose |
|---|---|
| Evidences | Source-linked snippets extracted via Monte Carlo sampling, each with file path, summary, and raw text |
| Content | LLM-synthesized markdown with structured analysis and references |
| Patterns | 3–5 distilled design principles or mechanisms identified from the evidence |
| Confidence | A consensus score [0, 1] indicating the reliability of the cluster |
| Queries | Historical queries that contributed to or reused this cluster (FIFO, max 5) |
| Hotness | Activity score reflecting query frequency and recency |
| Embedding | 384-dim vector derived from accumulated queries, enabling semantic retrieval |
Lifecycle: From Creation to Evolution
┌─────── New Query ───────┐
│ ▼
│ ┌──────────────────────────────┐
│ │ Phase 0: Semantic Reuse │──── Match found ──→ Return cached cluster
│ │ (cosine similarity ≥ 0.85) │ + update hotness/queries/embedding
│ └──────────┬───────────────────┘
│ No match
│ ▼
│ ┌──────────────────────────────┐
│ │ Phase 1–3: Full Search │
│ │ (keywords → retrieval → │
│ │ Monte Carlo → LLM synth) │
│ └──────────┬───────────────────┘
│ ▼
│ ┌──────────────────────────────┐
│ │ Build New Cluster │
│ │ Deterministic ID: C{sha256} │
│ └──────────┬───────────────────┘
│ ▼
│ ┌──────────────────────────────┐
│ │ Phase 5: Persist │
│ │ Embed queries → DuckDB → │
│ │ Parquet (atomic sync) │
└─────└──────────────────────────────┘
-
Reuse Check (Phase 0): Before any retrieval, the query is embedded and compared against all stored clusters via cosine similarity. If a high-confidence match is found, the existing cluster is returned instantly — saving LLM tokens and search time entirely.
-
Creation (Phase 1–3): When no reuse match is found, the full pipeline runs: keyword extraction, file retrieval, Monte Carlo evidence sampling, and LLM synthesis produce a new
KnowledgeCluster. -
Persistence (Phase 5): The cluster is stored in an in-memory DuckDB table and periodically flushed to Parquet files. Atomic writes and mtime-based reload ensure multi-process safety.
-
Evolution on Reuse: Each time a cluster is reused, the system:
- Appends the new query to the cluster's query history (FIFO, max 5)
- Increases hotness (
+0.1, capped at 1.0) - Recomputes the embedding from the updated query set — broadening the cluster's semantic catchment area
- Updates version and timestamp
Key Properties
- Zero-cost acceleration: Repeated or semantically similar queries are answered from cached clusters without any LLM inference, making subsequent searches near-instantaneous.
- Query-driven embeddings: Cluster embeddings are derived from queries rather than content, ensuring that retrieval aligns with how users actually ask questions — not how documents are written.
- Semantic broadening: As diverse queries reuse the same cluster, its embedding drifts to cover a wider semantic neighborhood, naturally improving recall for related future queries.
- Lightweight persistence: DuckDB in-memory + Parquet on disk — no external database infrastructure required. Background daemon sync with configurable flush intervals keeps overhead minimal.
Data Storage
All persistent data is stored in the configured SIRCHMUNK_WORK_PATH (default: ~/.sirchmunk/):
{SIRCHMUNK_WORK_PATH}/
├── .cache/
├── history/ # Chat session history (DuckDB)
│ └── chat_history.db
└── knowledge/ # Knowledge clusters (Parquet)
└── knowledge_clusters.parquet
🔗 HTTP Client Access (Search API)
When the server is running (sirchmunk serve or sirchmunk web serve), the Search API is accessible via any HTTP client.
API Endpoints
| Method | Endpoint | Description |
|---|---|---|
POST | /api/v1/search | Execute a search query (JSON response when complete) |
POST | /api/v1/search/stream | Same body as /search; Server-Sent Events stream of logs + final result / error |
GET | /api/v1/search/status | Check server and LLM configuration status (includes max_concurrent_searches) |
Interactive Docs: http://localhost:8584/docs (Swagger UI)
cURL Examples
paths rules (same for /search and /search/stream):
- Type: a single string or an array of strings (
"paths": "/one/dir"or"paths": ["/a", "/b"]). - If you omit
paths, sendnull,"",[], or only blank strings, the server usesSIRCHMUNK_SEARCH_PATHSfrom its environment (typically set in~/.sirchmunk/.env, loaded at startup). If that is unset too, search falls back to the server process current working directory. - Priority: explicit non-empty request
paths→SIRCHMUNK_SEARCH_PATHS→ cwd.
# FAST mode (default, greedy search with 2 LLM calls) curl -X POST http://localhost:8584/api/v1/search \ -H "Content-Type: application/json" \ -d '{ "query": "How does authentication work?", "paths": ["/path/to/project"] }' # Single path as a string (equivalent to a one-element list) curl -X POST http://localhost:8584/api/v1/search \ -H "Content-Type: application/json" \ -d '{ "query": "How does authentication work?", "paths": "/path/to/project" }' # Omit paths — use SIRCHMUNK_SEARCH_PATHS from ~/.sirchmunk/.env on the server curl -X POST http://localhost:8584/api/v1/search \ -H "Content-Type: application/json" \ -d '{"query": "How does authentication work?"}' # DEEP mode (comprehensive analysis with Monte Carlo sampling) curl -X POST http://localhost:8584/api/v1/search \ -H "Content-Type: application/json" \ -d '{ "query": "database connection pooling", "paths": ["/path/to/project/src"], "mode": "DEEP" }' # Filename search (no LLM required) curl -X POST http://localhost:8584/api/v1/search \ -H "Content-Type: application/json" \ -d '{ "query": "config", "paths": ["/path/to/project"], "mode": "FILENAME_ONLY" }' # Full parameters (see Request Parameters table) curl -X POST http://localhost:8584/api/v1/search \ -H "Content-Type: application/json" \ -d '{ "query": "database connection pooling", "paths": ["/path/to/project/src"], "mode": "DEEP", "max_depth": 10, "top_k_files": 20, "max_loops": 10, "include_patterns": ["*.py", "*.java"], "exclude_patterns": ["*test*", "*__pycache__*"], "return_context": true }' # Check server status curl http://localhost:8584/api/v1/search/status
Python Client Examples
Using requests:
import requests response = requests.post( "http://localhost:8584/api/v1/search", json={ "query": "How does authentication work?", "paths": ["/path/to/project"], }, timeout=60 ) data = response.json() if data["success"]: payload = data.get("data") or {} # API returns type "summary" | "files" | "context" print(payload.get("summary", payload))
Using httpx (async):
import httpx import asyncio async def search(): async with httpx.AsyncClient(timeout=300) as client: resp = await client.post( "http://localhost:8584/api/v1/search", json={ "query": "find all API endpoints", # Optional: omit "paths" to use server SIRCHMUNK_SEARCH_PATHS "paths": ["/path/to/project"], } ) data = resp.json() if data.get("success"): p = data.get("data") or {} print(p.get("summary", p)) asyncio.run(search())
JavaScript Client Example
const response = await fetch("http://localhost:8584/api/v1/search", { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify({ query: "How does authentication work?", paths: ["/path/to/project"], }) }); const data = await response.json(); if (data.success) { const p = data.data || {}; console.log(p.summary ?? p); }
SSE streaming search (/api/v1/search/stream)
Use this endpoint when you need real-time search logs (same pipeline as POST /api/v1/search). The response is text/event-stream (Server-Sent Events). The JSON body is identical to /api/v1/search (paths optional; string or array — see cURL section above).
Event types
SSE event | data (JSON) | Meaning |
|---|---|---|
log | {"level":"info",...,"message":"..."} | One log line from the search pipeline |
result | {"success":true,"data":{...}} | Final outcome (same shape as /search data: summary, files, or context) |
error | {"error":"..."} | Fatal error; stream ends |
Comment lines starting with : are keep-alives (safe to ignore).
Concurrency
Concurrent streaming searches are limited server-side by SIRCHMUNK_MAX_CONCURRENT_SEARCHES (default 3). Extra clients wait until a slot is free. See GET /api/v1/search/status → max_concurrent_searches.
cURL (use -N / --no-buffer so chunks print as they arrive)
curl -N -X POST "http://localhost:8584/api/v1/search/stream" \ -H "Content-Type: application/json" \ -H "Accept: text/event-stream" \ -d '{ "query": "How does authentication work?", "paths": ["/path/to/project"], "mode": "FAST" }'
Python — requests (streaming lines)
import json import requests url = "http://localhost:8584/api/v1/search/stream" payload = { "query": "How does authentication work?", "paths": ["/path/to/project"], "mode": "FAST", } event_type = "" with requests.post( url, json=payload, stream=True, timeout=(10, 600), headers={"Accept": "text/event-stream"}, ) as resp: resp.raise_for_status() for raw in resp.iter_lines(decode_unicode=True): if raw is None or raw == "": continue if raw.startswith(":"): continue if raw.startswith("event: "): event_type = raw[7:].strip() continue if raw.startswith("data: "): obj = json.loads(raw[6:]) if event_type == "log": print(f"[{obj.get('level', 'info')}] {obj.get('message', '')}") elif event_type == "result": print("DONE:", json.dumps(obj, indent=2, ensure_ascii=False)) elif event_type == "error": print("ERROR:", obj.get("error")) event_type = ""
Python — httpx
import json import httpx url = "http://localhost:8584/api/v1/search/stream" payload = {"query": "find API routes", "paths": ["/path/to/project"], "mode": "DEEP"} event_type = "" with httpx.Client(timeout=httpx.Timeout(600.0, connect=10.0)) as client: with client.stream( "POST", url, json=payload, headers={"Accept": "text/event-stream"}, ) as resp: resp.raise_for_status() for line in resp.iter_lines(): if not line or line.startswith(":"): continue if line.startswith("event: "): event_type = line[7:].strip() continue if line.startswith("data: "): obj = json.loads(line[6:]) if event_type == "log": print(obj.get("message", "")) elif event_type == "result": data = obj.get("data", {}) print(data.get("summary") or data) event_type = ""
JavaScript — fetch + readable stream (EventSource is GET-only; POST SSE needs fetch)
async function searchStream(baseUrl, body) { const res = await fetch(`${baseUrl}/api/v1/search/stream`, { method: "POST", headers: { "Content-Type": "application/json", Accept: "text/event-stream", }, body: JSON.stringify(body), }); if (!res.ok) throw new Error(await res.text()); const reader = res.body.getReader(); const dec = new TextDecoder(); let buf = ""; let currentEvent = ""; while (true) { const { done, value } = await reader.read(); if (done) break; buf += dec.decode(value, { stream: true }); const parts = buf.split("\n\n"); buf = parts.pop() || ""; for (const block of parts) { let dataLine = null; for (const line of block.split("\n")) { if (line.startsWith("event:")) currentEvent = line.slice(6).trim(); else if (line.startsWith("data:")) dataLine = line.slice(5).trim(); } if (!dataLine) continue; const obj = JSON.parse(dataLine); if (currentEvent === "log") console.log(`[${obj.level}]`, obj.message); if (currentEvent === "result") console.log("result", obj); if (currentEvent === "error") console.error(obj.error); } } } await searchStream("http://localhost:8584", { query: "How does authentication work?", paths: ["/path/to/project"], mode: "FAST", });
CLI
sirchmunk search --api uses this streaming endpoint when available and prints log lines to stderr/stdout as they arrive, then prints the final summary.
Request Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
query | string | required | Search query or question |
paths | string | string[] | optional | One path or many. Omit / null / "" / [] / only blanks → server SIRCHMUNK_SEARCH_PATHS (e.g. ~/.sirchmunk/.env), then cwd. Request paths override env. |
mode | string | "FAST" | FAST, DEEP, or FILENAME_ONLY |
enable_dir_scan | bool | true | Enable directory scanning (FAST/DEEP) for file discovery |
max_depth | int | null | Maximum directory depth |
top_k_files | int | null | Number of top files to return |
max_loops | int | null | Maximum ReAct iterations (DEEP mode) |
max_token_budget | int | null | LLM token budget (DEEP mode, default 128K) |
include_patterns | string[] | null | File glob patterns to include |
exclude_patterns | string[] | null | File glob patterns to exclude |
return_context | bool | false | Return SearchContext with cluster and telemetry |
Note:
FILENAME_ONLYmode does not require an LLM API key.FASTandDEEPmodes require a configured LLM.
❓ FAQ
How is this different from traditional RAG systems?
Sirchmunk takes an indexless approach:
- No pre-indexing: Direct file search without vector database setup
- Self-evolving: Knowledge clusters evolve based on search patterns
- Multi-level retrieval: Adaptive keyword granularity for better recall
- Evidence-based: Monte Carlo sampling for precise content extraction
What LLM providers are supported?
Any OpenAI-compatible API endpoint, including (but not limited to):
- OpenAI (GPT-5.2, ...)
- MiniMax (MiniMax-M3, MiniMax-M2.7, MiniMax-M2.7-highspeed)
- DeepSeek, Moonshot, Mistral, Groq, Together AI, Cohere
- Google Gemini, Zhipu (GLM), Baichuan, Yi, SiliconFlow, Volcengine
- Azure OpenAI
- Local models served via Ollama, llama.cpp, vLLM, SGLang etc.
- Claude via API proxy
To use MiniMax, configure:
LLM_BASE_URL=https://api.minimax.io/v1 LLM_API_KEY=your-minimax-api-key LLM_MODEL_NAME=MiniMax-M3
For more details, see MiniMax OpenAI-Compatible API.
How do I add documents to search?
Simply specify the path in your search query:
result = await searcher.search( query="Your question", paths=["/path/to/folder", "/path/to/file.pdf"] )
No pre-processing or indexing required!
Where are knowledge clusters stored?
Knowledge clusters are persisted in Parquet format at:
{SIRCHMUNK_WORK_PATH}/.cache/knowledge/knowledge_clusters.parquet
You can query them using DuckDB or the KnowledgeManager API.
How do I monitor LLM token usage?
- Web Dashboard: Visit the Monitor page for real-time statistics
- API:
GET /api/v1/monitor/llmreturns usage metrics - Code: Access
searcher.llm_usagesafter search completion
📋 Roadmap
- Text-retrieval from raw files
- Knowledge structuring & persistence
- Real-time chat with RAG
- Web UI support
- Multi-turn conversation with context management
- Web search integration
- Multi-modal support (images, videos)
- Distributed search across nodes
- Knowledge visualization and deep analytics
- More file type support
🤝 Contributing
We welcome contributions !
📄 License
This project is licensed under the Apache License 2.0.
ModelScope · ⭐ Star us · 🐛 Report a bug · 💬 Discussions
✨ Sirchmunk: Raw data to self-evolving intelligence, real-time.
❤️ Thanks for Visiting ✨ Sirchmunk !