MinerU-Popo: Universal Post-Processing Model for Structured Document Parsing
If you like our project, please give us a star ⭐ on GitHub for the latest update.
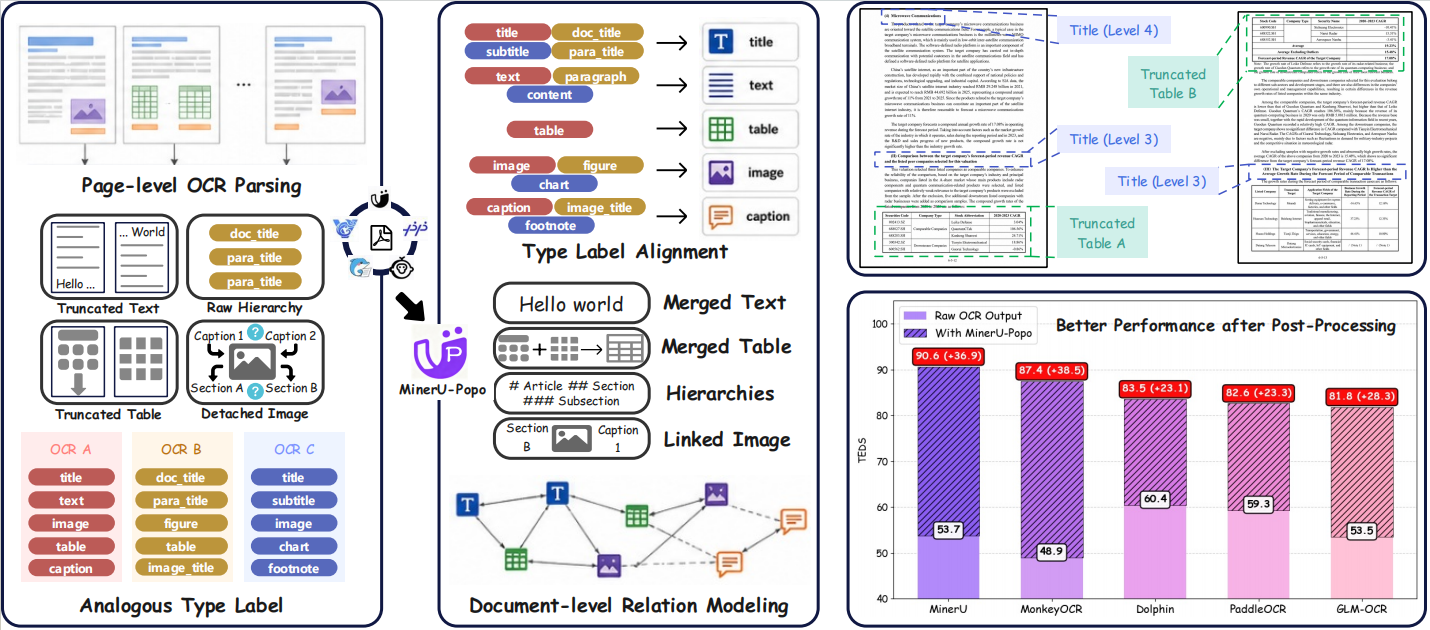
✨ Introduction
MinerU-Popo is a lightweight and universal framework for POst-Processing OCR outputs, bridging the gap between page-level OCR parsing and document-level semantic structure. It constructs document tree structures with a 4B post-processing model that performs four subtasks: table truncation analysis, text truncation analysis, title hierarchy analysis, and image-text association analysis. We handle the challenges of cross-page geometric discontinuity, redundant document parsing, and scalability to long documents via:
- Task-Oriented Data Engine: Generate representative training data and simplify the task-specific input.
- Dynamic Chunking and Synchronization: Process long document by dynamic chunks and reduce deviations across chunks to preserve global consistency.
- Document Enrichment: Structurally construct a tree, semantically generate summaries and split long-section nodes.
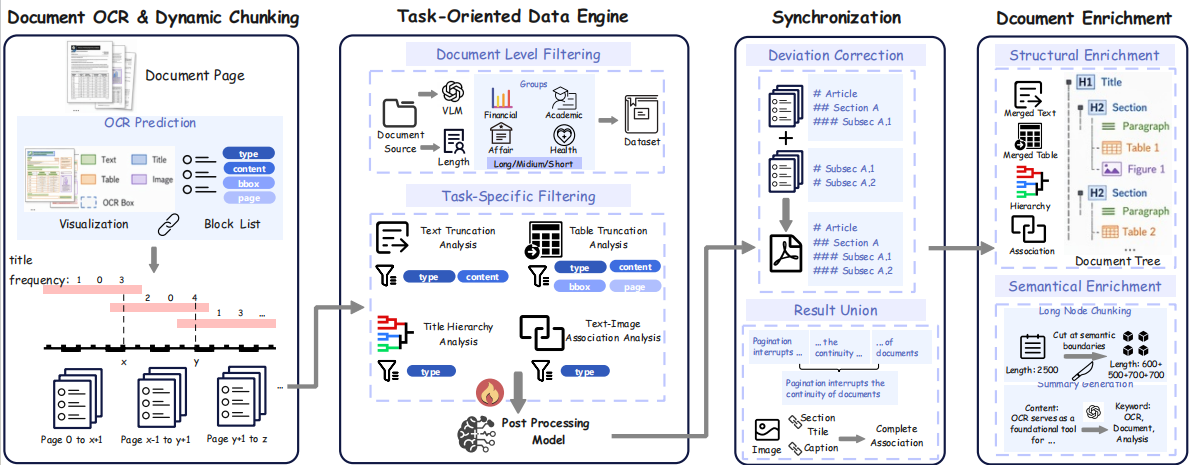
📊 Performance
Better Hierarchy (TEDS) after Post-Processing
| Basic OCR | Before | After |
|---|---|---|
| MinerU | 53.7 | 90.6 |
| MonkeyOCR | 48.9 | 87.4 |
| Dolphin | 60.4 | 83.5 |
| PaddleOCR | 59.3 | 82.6 |
| GLM-OCR | 53.5 | 81.8 |
Advantages Compared to Directly Using Pre-trained Model
| Model | TEDS | Doc/s |
|---|---|---|
| MinerU-Popo | 90.6 | 0.37 |
| Qwen3-VL-2B | 21.2 | 0.22 |
| Qwen3-VL-4B | 56.5 | 0.20 |
| Qwen3-VL-8B | 65.9 | 0.16 |
| Qwen3-VL-32B | 78.0 | 0.04 |
Benefits for Downstream Retrieval and Analysis (Acc on ViDoRe V3)
| Method | C.S. | Fin. | H.R. | Ind. | Phar. |
|---|---|---|---|---|---|
| MinerU-Popo | 84.4 | 49.5 | 66.8 | 58.7 | 71.6 |
| Raw RAG | 82.3 | 48.7 | 63.2 | 60.4 | 64.4 |
| Visual RAG | 80.7 | 58.4 | 64.8 | 59.7 | 67.6 |
⚙️ Setup
Prepare Environment
Install from Source
conda create -n popo python=3.10
conda activate popo
pip install -r requirements.txtInstall from Docker Image
docker run -it --rm --gpus=all --ipc=host --network=host dockerrr8277/mineru-popo-vllm:latestDownload Model
Download the MinerU-Popo post-processing model:
hf download DreamEternal/MinerU-Popo --local-dir models/Mineru-PopoModel Configuration
In the Configuration,
for transformer inference, edit the environment POPO_MODEL_PATH. For vllm inference, edit the url and key in function popo_generate.
For enrichment and question answering, further edit the url and key in qwen_generate and gpt_generate.
💻 Usage
The post-processing pipeline takes page-level parsing results from OCR/layout systems, normalizes them into a unified schema, runs MinerU-Popo inference, and finally builds document trees.
Step 1: Prepare OCR/Layout Outputs
Run your preferred page-level parser first, such as MinerU, MonkeyOCR, Dolphin, PaddleOCR-VL, or GLM-OCR. Place each model's output under:
post-process/<model_name>/For example:
post-process/mineru/
post-process/monkeyocr/
post-process/PaddleOCR-VL-1.5/
post-process/dolphin/
post-process/glm-ocr/Step 2: Normalize Labels
Convert raw model-specific labels and bounding boxes into the unified MinerU-Popo input format:
bash scripts/run_label_normalization.shThe normalized outputs are written to:
outputs/label_normalization/<model_name>/Step 3: Run MinerU-Popo Inference
Run MinerU-Popo on the normalized labels:
bash scripts/run_inference.shThe inference outputs are written to:
outputs/inference/<model_name>/Step 4: Build Document Trees
Build structured document trees from the inference outputs:
bash scripts/build_tree.shThe final tree outputs and text previews are written to:
outputs/build_tree/<model_name>/
outputs/build_tree_txt/<model_name>/Example tree outputs are provided in:
output_cases/🙏 Acknowledgements
- MinerU and other OCR system (MonkeyOCR, Dolphin, PaddleOCR, GLM-OCR) for page-level parsing.
- ViDoRe V3 and MMDA as benchmarks.
📚 Citation
If you find this project useful for your research, please consider giving us a star and citing our paper:
@article{xu2026mineru,
title={MinerU-Popo: Universal Post-Processing Model for Structured Document Parsing},
author={Xu, Bangrui and Miao, Ziyang and Zhou, Xuanhe and Lin, Yiming and Tang, Zirui and Zhao, Xiaomeng and Wu, Fan and Tan, Cheng and Wang, Bin and He, Conghui},
journal={arXiv preprint arXiv:2605.24973},
year={2026}
}📄 License
This project is licensed under the MIT License. See the LICENSE file for details.