Public
Star 历史趋势
数据来源: GitHub API · 生成自 Stargazers.cn
README.md
Local ReAct Agent
A minimal, "hand-built" ReAct agent that runs entirely on your computer using Ollama + Llama 3.2 3B. Four short Python files, no SDK abstractions over the loop — every Action is parsed from text and dispatched manually.
No API key. No paid subscription. ~3 GB disk for the model.
Pseudo Code
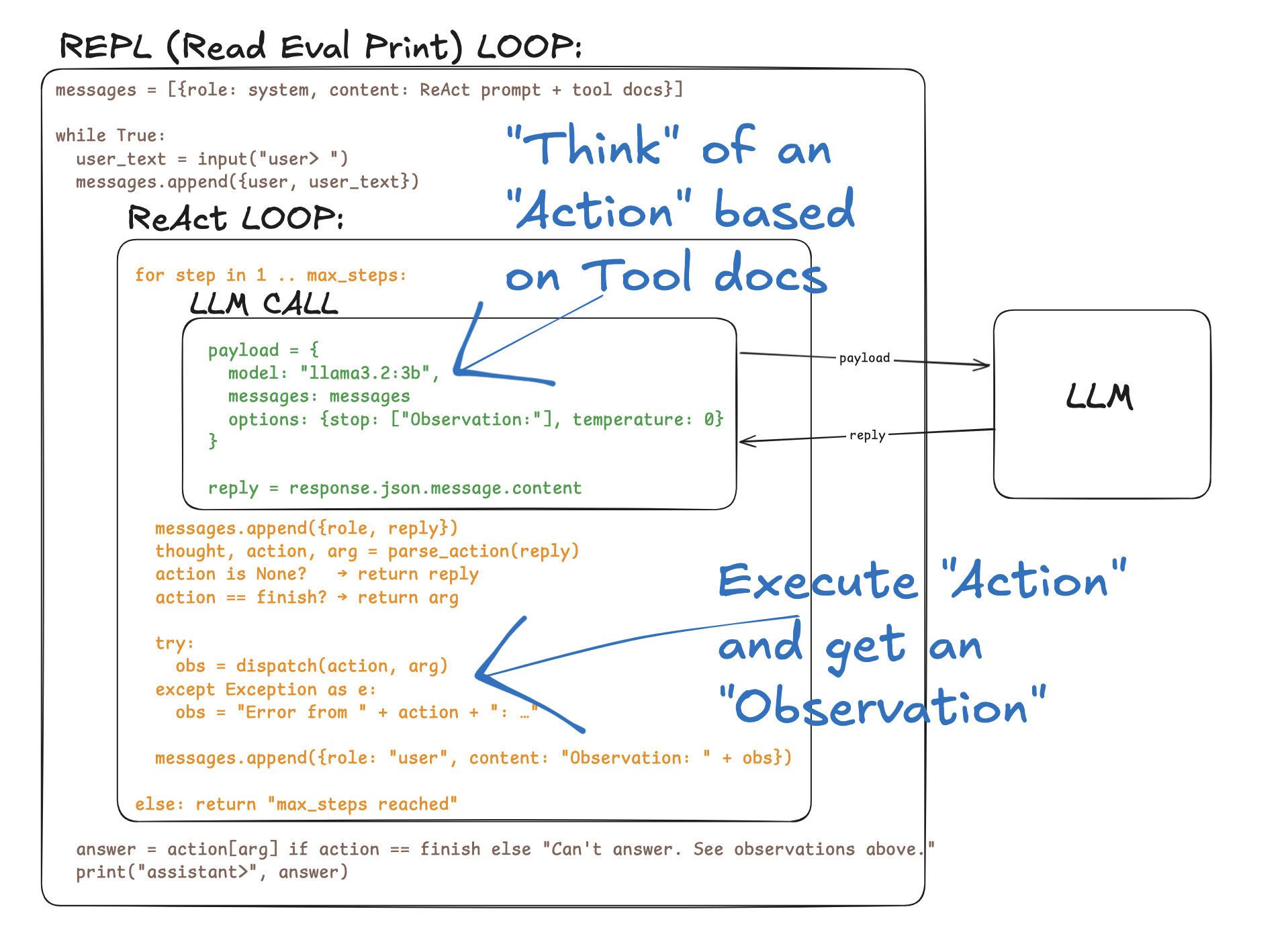
What this teaches
- Chat API roles — every message is tagged
system/user/assistant. Tool observations are injected asusermessages with anObservation:prefix (the original 2022 ReAct paper convention). - Stop sequences — Ollama's
stopparameter halts generation before the model writesObservation:, so each assistant message contains exactly one Action. A regex catches any stragglers client-side. - Prompt-as-history — the LLM is stateless. The full
messageslist is re-sent every turn. That's literally the "context window" filling up. - Inner vs outer loop — the outer loop is multi-turn conversation
(
repl.py). The inner loop is the ReAct iteration within one user turn (react.py). They're two distinct loops doing different jobs. - Tool dispatch —
tools.TOOLSis a single dict mapping name → function. The system prompt is generated from it. Adding a tool is one entry. - No SDK tool-use — the agent loop is hand-built on top of a plain chat API. Every Action is parsed from text and dispatched manually.
Files
| File | Lines | What it does |
|---|---|---|
llm.py | ~40 | One pure function: chat(messages, stop) → text |
tools.py | ~95 | calculate (AST eval), web_search (DuckDuckGo, no key), dispatch |
react.py | ~95 | SYSTEM_PROMPT, parse_action, agent_turn |
repl.py | ~55 | Multi-turn REPL with /clear//history commands |
requirements.txt | 2 | httpx, ddgs |
Prereqs
- Python 3.10+
- Linux / macOS with Homebrew (other installers work too)
- ~3 GB free disk (Llama 3.2 3B is ~2 GB)
One-time setup
brew install ollama brew services start ollama # daemon on localhost:11434 ollama pull llama3.2:3b # ~2 GB, one-time download
Per-session setup
cd /path/to/agent-loop python3 -m venv .venv source .venv/bin/activate pip install -r requirements.txt
Run
python -m repl
REPL commands
Typed at the user> prompt. Handled by repl.py, never sent to the model.
| Command | Effect |
|---|---|
quit / exit / Ctrl-D | Leave the REPL |
/clear | Drop the conversation history (keeps the system prompt) |
/history | Dump every message in the current context, indexed and role-tagged |
Anything else is treated as a user question and triggers one agent_turn.
Sample session:
user> add 100 to the year of the last presidential election in Chile
[step 1] thought: I need to find the year of the last presidential election in Chile.
[step 1] action: web_search[last presidential election in Chile]
[step 1] observ: - 2025 Chilean general election - Wikipedia: General elections were held in Chile on 16 November 2025. Voters went to th...
[step 2] thought: The last presidential election in Chile was in 2025, so I need to add 100 to that year.
[step 2] action: calculate[2025 + 100]
[step 2] observ: 2125
[step 3] thought: The result of adding 100 to the year of the last presidential election in Chile is indeed 2125.
[step 3] action: finish[2125]
assistant> 2125
user> divide that by 5
[step 1] thought: I need to divide 2125 by 5 to get the final answer.
[step 1] action: calculate[2125 / 5]
[step 1] observ: 425.0
[step 2] thought: The result of dividing 2125 by 5 is indeed 425.0, which makes sense as it's a simple division problem.
[step 2] action: finish[425.0]
assistant> 425.0
user> /clear
(history cleared)
Customize
- Add a tool — add one entry to
tools.TOOLS. The system prompt picks it up automatically viadocs(). - Swap the model — change
MODELinllm.py. Tiny models that work (sometimes):llama3.2:1b(faster, less reliable format),qwen2.5:3b,qwen2.5:1.5b. - More steps — raise
max_stepsinagent_turn(default 8). - Less deterministic — raise
temperaturein thechatcall (default 0).
Troubleshooting
httpx.ConnectError: Ollama isn't running.brew services start ollama.- First turn is slow (~10 s): model loading into memory. Subsequent turns use the warm cache.
- Model emits text instead of
Action: ...: format drift. The loop catches it and prints(no action - using reply as final). Llama 3.2 3B is reliable; smaller models drift more. - Tool raises an exception: caught and reported as
Observation: Error from <tool>: <message>so the model can react. - Answers are not logical: we are not using a Frontier model here.
关于 About
No description, website, or topics provided.
语言 Languages
Python100.0%
提交活跃度 Commit Activity
代码提交热力图
过去 52 周的开发活跃度1
Total Commits峰值: 1次/周
LessMore