Step-Audio-EditX
![]()






🔥🔥🔥 News!!!
- Jan 29, 2026:
- 🧩 New Model Release:
- Better performance, with an overall improvement of over 4%.
- More paralinguistic tags have been added, including
exhale,snort,inhale,chuckle,clears throat,giggle. - Welcome to try out at StepFun Audio Studio
- 💻 We release the SFT, DPO and GRPO training code.
- 🌟 Training and inference for vLLM are now supported. Thanks to the vLLM team!
- 🧩 New Model Release:
- Nov 28, 2025: 🚀 New Model Release: Now supporting
JapaneseandKoreanlanguages. - Nov 23, 2025: 📊 Step-Audio-Edit-Benchmark Released!
- Nov 19, 2025: ⚙️ We release a new version of our model, which supports polyphonic pronunciation control and improves the performance of emotion, speaking style, and paralinguistic editing.
- Nov 12, 2025: 📦 We release the optimized inference code and model weights of Step-Audio-EditX (HuggingFace; ModelScope) and Step-Audio-Tokenizer(HuggingFace; ModelScope)
- Nov 07, 2025: ✨ Demo Page ; 🎮 HF Space Playground
- Nov 06, 2025: 👋 We release the technical report of Step-Audio-EditX.
Introduction
We are open-sourcing Step-Audio-EditX, a powerful 3B-parameter LLM-based Reinforcement Learning audio model specialized in expressive and iterative audio editing. It excels at editing emotion, speaking style, and paralinguistics, and also features robust zero-shot text-to-speech (TTS) capabilities.
 Wechat developer group
Wechat developer group
📑 Open-source Plan
- Inference Code
- Online demo (Gradio)
- Step-Audio-Edit-Benchmark
- Model Checkpoints
- Step-Audio-Tokenizer
- Step-Audio-EditX
- Step-Audio-EditX-Int4
- Training Code
- SFT training
- DPO training
- GRPO training
- PPO training
- ⏳ Feature Support Plan
- Editing
- Polyphone pronunciation control
- More paralinguistic tags ([Cough, Crying, Stress, etc.])
- Filler word removal
- Other Languages
- Japanese, Korean
- Arabic, French, Russian, Spanish, etc.
- Editing
Features
-
Zero-Shot TTS
- Excellent zero-shot TTS cloning for Mandarin, English, Sichuanese, and Cantonese.
- To use dialect or other languages, just add a
[Sichuanese]/[Cantonese]/[Japanese]/[Korean]tag before your text. - 🔥 Polyphone pronunciation control, all you need to do is replace the polyphonic characters with pinyin.
-
[我也想过过过儿过过的生活] -> [我也想guo4guo4guo1儿guo4guo4的生活]
-
-
Emotion and Speaking Style Editing
- Remarkably effective iterative control over emotions and styles, supporting dozens of options for editing.
- Emotion Editing : [ Angry, Happy, Sad, Excited, Fearful, Surprised, Disgusted, etc. ]
- Speaking Style Editing: [ Act_coy, Older, Child, Whisper, Serious, Generous, Exaggerated, etc.]
- Editing with more emotion and more speaking styles is on the way. Get Ready! 🚀
- Remarkably effective iterative control over emotions and styles, supporting dozens of options for editing.
-
Paralinguistic Editing
- Precise control over 10 types of paralinguistic features for more natural, human-like, and expressive synthetic audio.
- Supporting Tags:
- [ Breathing, Laughter, Surprise-oh, Confirmation-en, Uhm, Surprise-ah, Surprise-wa, Sigh, Question-ei, Dissatisfaction-hnn ]
-
Available Tags
| emotion | happy | Expressing happiness | angry | Expressing anger |
| sad | Expressing sadness | fear | Expressing fear | |
| surprised | Expressing surprise | confusion | Expressing confusion | |
| empathy | Expressing empathy and understanding | embarrass | Expressing embarrassment | |
| excited | Expressing excitement and enthusiasm | depressed | Expressing a depressed or discouraged mood | |
| admiration | Expressing admiration or respect | coldness | Expressing coldness and indifference | |
| disgusted | Expressing disgust or aversion | humour | Expressing humor or playfulness | |
| speaking style | serious | Speaking in a serious or solemn manner | arrogant | Speaking in an arrogant manner |
| child | Speaking in a childlike manner | older | Speaking in an elderly-sounding manner | |
| girl | Speaking in a light, youthful feminine manner | pure | Speaking in a pure, innocent manner | |
| sister | Speaking in a mature, confident feminine manner | sweet | Speaking in a sweet, lovely manner | |
| exaggerated | Speaking in an exaggerated, dramatic manner | ethereal | Speaking in a soft, airy, dreamy manner | |
| whisper | Speaking in a whispering, very soft manner | generous | Speaking in a hearty, outgoing, and straight-talking manner | |
| recite | Speaking in a clear, well-paced, poetry-reading manner | act_coy | Speaking in a sweet, playful, and endearing manner | |
| warm | Speaking in a warm, friendly manner | shy | Speaking in a shy, timid manner | |
| comfort | Speaking in a comforting, reassuring manner | authority | Speaking in an authoritative, commanding manner | |
| chat | Speaking in a casual, conversational manner | radio | Speaking in a radio-broadcast manner | |
| soulful | Speaking in a heartfelt, deeply emotional manner | gentle | Speaking in a gentle, soft manner | |
| story | Speaking in a narrative, audiobook-style manner | vivid | Speaking in a lively, expressive manner | |
| program | Speaking in a show-host/presenter manner | news | Speaking in a news broadcasting manner | |
| advertising | Speaking in a polished, high-end commercial voiceover manner | roar | Speaking in a loud, deep, roaring manner | |
| murmur | Speaking in a quiet, low manner | shout | Speaking in a loud, sharp, shouting manner | |
| deeply | Speaking in a deep and low-pitched tone | loudly | Speaking in a loud and high-pitched tone | |
| paralinguistic | [sigh] | Sighing sound | [inhale] | Inhaling sound |
| [laugh] | Laughter sound | [chuckle] | Chuckling sound | |
| [exhale] | Exhaling sound | [clears throat] | Throat clearing sound | |
| [snort] | Snorting sound | [giggle] | Giggling sound | |
| [cough] | Coughing sound | [breath] | Breathing sound | |
| [uhm] | Hesitation sound: "Uhm" | [Confirmation-en] | Confirming: "En" | |
| [Surprise-oh] | Expressing surprise: "Oh" | [Surprise-ah] | Expressing surprise: "Ah" | |
| [Surprise-wa] | Expressing surprise: "Wa" | [Surprise-yo] | Expressing surprise: "Yo" | |
| [Dissatisfaction-hnn] | Dissatisfied sound: "Hnn" | [Question-ei] | Questioning: "Ei" | |
| [Question-ah] | Questioning: "Ah" | [Question-en] | Questioning: "En" | |
| [Question-yi] | Questioning: "Yi" | [Question-oh] | Questioning: "Oh" |
Feature Requests & Wishlist
💡 We welcome all ideas for new features! If you'd like to see a feature added to the project, please start a discussion in our Discussions section.
We'll be collecting community feedback here and will incorporate popular suggestions into our future development plans. Thank you for your contribution!
Demos
| Task | Text | Source | Edited |
|---|---|---|---|
| Emotion-Fear | 我总觉得,有人在跟着我,我能听到奇怪的脚步声。 | ||
| Style-Whisper | 比如在工作间隙,做一些简单的伸展运动,放松一下身体,这样,会让你更有精力。 | ||
| Style-Act_coy | 我今天想喝奶茶,可是不知道喝什么口味,你帮我选一下嘛,你选的都好喝~ | ||
| Paralinguistics | 你这次又忘记带钥匙了 [Dissatisfaction-hnn],真是拿你没办法。 | ||
| Denoising | Such legislation was clarified and extended from time to time thereafter. No, the man was not drunk, he wondered how we got tied up with this stranger. Suddenly, my reflexes had gone. It's healthier to cook without sugar. | ||
| Speed-Faster | 上次你说鞋子有点磨脚,我给你买了一双软软的鞋垫。 |
For more examples, see demo page.
Model Download
| Models | 🤗 Hugging Face | ModelScope |
|---|---|---|
| Step-Audio-EditX | stepfun-ai/Step-Audio-EditX | stepfun-ai/Step-Audio-EditX |
| Step-Audio-EditX | stepfun-ai/Step-Audio-EditX-AWQ-4bit | stepfun-ai/Step-Audio-EditX-AWQ-4bit |
| Step-Audio-Tokenizer | stepfun-ai/Step-Audio-Tokenizer | stepfun-ai/Step-Audio-Tokenizer |
Model Usage
📜 Requirements
The following table shows the requirements for running Step-Audio-EditX model (batch size = 1):
| Model | Parameters | Setting (sample frequency) | GPU Optimal Memory |
|---|---|---|---|
| Step-Audio-EditX | 3B | 41.6Hz | 12 GB |
- An NVIDIA GPU with CUDA support is required.
- The model is tested on a single L40S GPU.
- 12GB is just a critical value, and 16GB GPU memory shoule be safer.
- Tested operating system: Linux
🔧 Dependencies and Installation
- Python >= 3.12
- PyTorch >= 2.9.1
- CUDA Toolkit
git clone https://github.com/stepfun-ai/Step-Audio-EditX.git cd Step-Audio-EditX uv sync --refresh source .venv/bin/activate git lfs install git clone https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer git clone https://huggingface.co/stepfun-ai/Step-Audio-EditX git clone https://huggingface.co/stepfun-ai/Step-Audio-EditX-AWQ-4bit/
After downloading the models, where_you_download_dir should have the following structure:
where_you_download_dir
├── Step-Audio-Tokenizer
├── Step-Audio-EditX
Run with Docker
You can set up the environment required for running Step-Audio-EditX using the provided Dockerfile.
# build docker docker build . -t step-audio-editx # run docker docker run --rm --gpus all \ -v /your/code/path:/app \ -v /your/model/path:/model \ -p 7860:7860 \ step-audio-editx
Local Inference Demo
[!TIP] For optimal performance, keep audio under 30 seconds per inference.
# zero-shot cloning # The path of the generated audio file is output/fear_zh_female_prompt_cloned.wav python3 tts_infer.py \ --model-path where_you_download_dir \ --tokenizer-path where_you_download_dir \ --prompt-text "我总觉得,有人在跟着我,我能听到奇怪的脚步声。" \ --prompt-audio "examples/fear_zh_female_prompt.wav" \ --generated-text "可惜没有如果,已经发生的事情终究是发生了。" \ --edit-type "clone" \ --output-dir ./output python3 tts_infer.py \ --model-path where_you_download_dir \ --tokenizer-path where_you_download_dir \ --prompt-text "His political stance was conservative, and he was particularly close to margaret thatcher." \ --prompt-audio "examples/zero_shot_en_prompt.wav" \ --generated-text "Underneath the courtyard is a large underground exhibition room which connects the two buildings. " \ --edit-type "clone" \ --output-dir ./output # edit # There will be one or multiple wave files corresponding to each edit iteration, for example: output/fear_zh_female_prompt_edited_iter1.wav, output/fear_zh_female_prompt_edited_iter2.wav, ... # emotion; fear python3 tts_infer.py \ --model-path where_you_download_dir \ --tokenizer-path where_you_download_dir \ --prompt-text "我总觉得,有人在跟着我,我能听到奇怪的脚步声。" \ --prompt-audio "examples/fear_zh_female_prompt.wav" \ --edit-type "emotion" \ --edit-info "fear" \ --output-dir ./output # emotion; happy python3 tts_infer.py \ --model-path where_you_download_dir \ --tokenizer-path where_you_download_dir \ --prompt-text "You know, I just finished that big project and feel so relieved. Everything seems easier and more colorful, what a wonderful feeling!" \ --prompt-audio "examples/en_happy_prompt.wav" \ --edit-type "emotion" \ --edit-info "happy" \ --output-dir ./output # style; whisper # for style whisper, the edit iteration num should be set bigger than 1 to get better results. python3 tts_infer.py \ --model-path where_you_download_dir \ --tokenizer-path where_you_download_dir \ --prompt-text "比如在工作间隙,做一些简单的伸展运动,放松一下身体,这样,会让你更有精力." \ --prompt-audio "examples/whisper_prompt.wav" \ --edit-type "style" \ --edit-info "whisper" \ --output-dir ./output # paraliguistic # supported tags, Breathing, Laughter, Surprise-oh, Confirmation-en, Uhm, Surprise-ah, Surprise-wa, Sigh, Question-ei, Dissatisfaction-hnn python3 tts_infer.py \ --model-path where_you_download_dir \ --tokenizer-path where_you_download_dir \ --prompt-text "我觉得这个计划大概是可行的,不过还需要再仔细考虑一下。" \ --prompt-audio "examples/paralingustic_prompt.wav" \ --generated-text "我觉得这个计划大概是可行的,[Uhm]不过还需要再仔细考虑一下。" \ --edit-type "paralinguistic" \ --output-dir ./output # denoise # Prompt text is not needed. python3 tts_infer.py \ --model-path where_you_download_dir \ --tokenizer-path where_you_download_dir \ --prompt-audio "examples/denoise_prompt.wav"\ --edit-type "denoise" \ --output-dir ./output # vad # Prompt text is not needed. python3 tts_infer.py \ --model-path where_you_download_dir \ --tokenizer-path where_you_download_dir \ --prompt-audio "examples/vad_prompt.wav" \ --edit-type "vad" \ --output-dir ./output # speed # supported edit-info: faster, slower, more faster, more slower python3 tts_infer.py \ --model-path where_you_download_dir \ --tokenizer-path where_you_download_dir \ --prompt-text "上次你说鞋子有点磨脚,我给你买了一双软软的鞋垫。" \ --prompt-audio "examples/speed_prompt.wav" \ --edit-type "speed" \ --edit-info "more faster" \ --output-dir ./output
Launch Web Demo
Start a local server for online inference. Assume you have one GPU with at least 12GB memory available and have already downloaded all the models.
# Standard launch python app.py --model-path where_you_download_dir --tokenizer-path where_you_download_dir --model-source local # Using pre-quantized AWQ 4-bit models, memory-efficient mode (for limited GPU memory, ~6-8GB usage) python app.py \ --model-path path/to/quantized/model \ --tokenizer-path where_you_download_dir \ --model-source local \ --gpu-memory-utilization 0.1 \ --enforce-eager \ --max-num-seqs 1 \ --cosyvoice-dtype bfloat16 \ --no-cosyvoice-cuda-graph
Available Parameters
| Parameter | Default | Description |
|---|---|---|
--model-path | (required) | Path to the model directory |
--model-source | auto | Model source: auto, local, modelscope, huggingface |
--gpu-memory-utilization | 0.5 | GPU memory ratio for vLLM KV cache (0.0-1.0) |
--max-model-len | 3072 | Maximum sequence length, affects KV cache size |
--enforce-eager | True | Disable vLLM CUDA Graphs (saves ~0.5GB memory) |
--max-num-seqs | 1 | Maximum concurrent sequences (vLLM default: 256, lower = less memory) |
--dtype | bfloat16 | Model dtype: float16, bfloat16 |
--quantization | None | Quantization method: awq, gptq, fp8 |
--cosyvoice-dtype | bfloat16 | CosyVoice vocoder dtype: float32, bfloat16, float16 |
--no-cosyvoice-cuda-graph | False | Disable CosyVoice CUDA Graphs (saves memory) |
--enable-auto-transcribe | False | Enable automatic audio transcription |
Memory Usage Guide
| Configuration | Estimated GPU Memory | Use Case |
|---|---|---|
| Standard (defaults) | ~12-15 GB | Best quality and speed |
| Memory-efficient | ~6-8 GB | Limited GPU memory, some quality trade-off |
| AWQ 4-bit quantized | ~8-10 GB | Good balance of quality and memory |
Training
Please refer to script/ReadMe.md
🔄 Model Quantization (Optional)
For users with limited GPU memory, you can create quantized versions of the model to reduce memory requirements:
# Create an AWQ 4-bit quantized model python quantization/awq_quantize.py --model_path path/to/Step-Audio-EditX # Advanced quantization options python quantization/awq_quantize.py
For detailed quantization options and parameters, see quantization/README.md.
Technical Details
 Step-Audio-EditX comprises three primary components:
Step-Audio-EditX comprises three primary components:
- A dual-codebook audio tokenizer, which converts reference or input audio into discrete tokens.
- An audio LLM that generates dual-codebook token sequences.
- An audio decoder, which converts the dual-codebook token sequences predicted by the audio LLM back into audio waveforms using a flow matching approach.
Audio-Edit enables iterative control over emotion and speaking style across all voices, leveraging large-margin data during SFT and PPO training.
Evaluation
Comparison between Step-Audio-EditX and Closed-Source models.
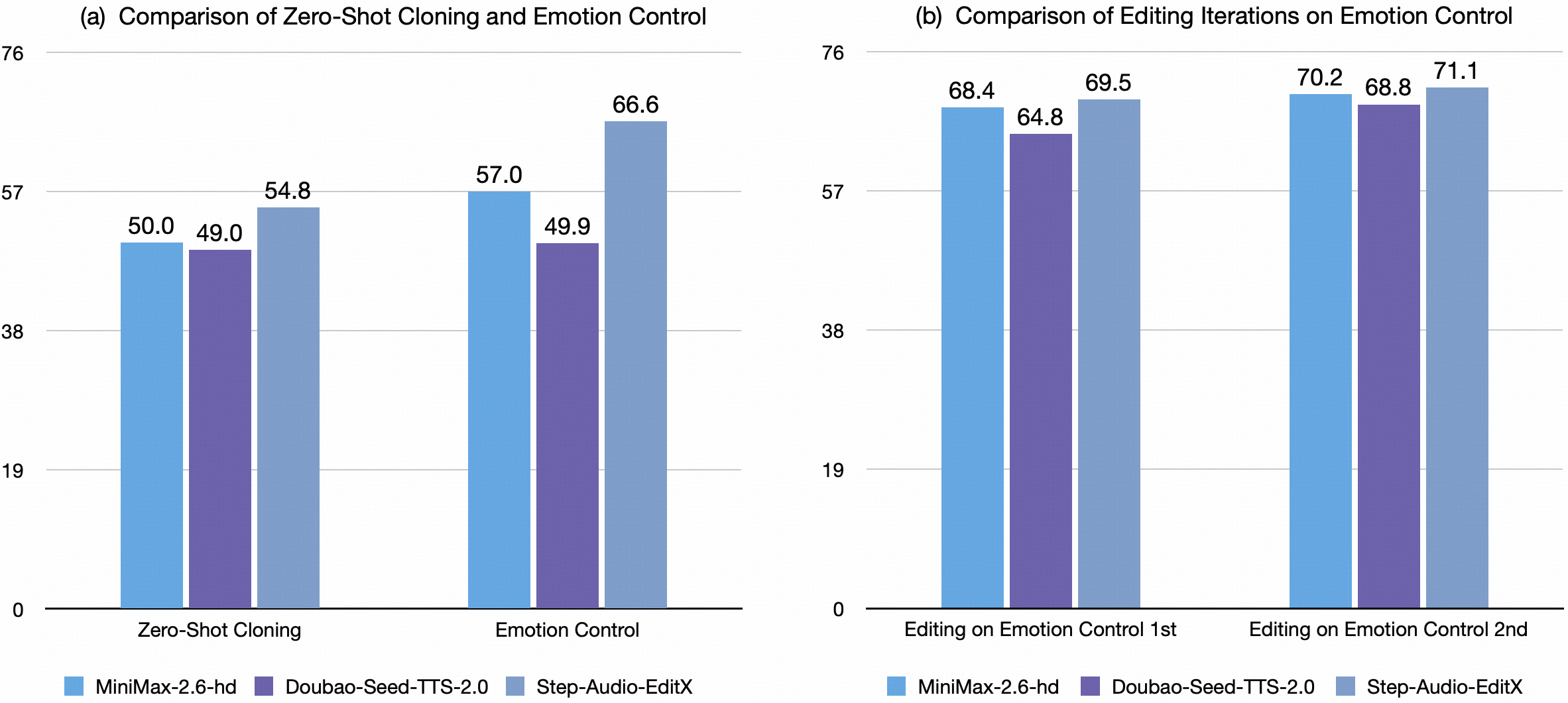
- Step-Audio-EditX demonstrates superior performance over Minimax and Doubao in both zero-shot cloning and emotion control.
- Emotion editing of Step-Audio-EditX significantly improves the emotion-controlled audio outputs of all three models after just one iteration. With further iterations, their overall performance continues to improve.
Generalization on Closed-Source Models.
-
For emotion and speaking style editing, the built-in voices of leading closed-source systems possess considerable in-context capabilities, allowing them to partially convey the emotions in the text. After a single editing round with Step-Audio-EditX, the emotion and style accuracy across all voice models exhibited significant improvement. Further enhancement was observed over the next two iterations, robustly demonstrating our model's strong generalization.
-
For paralinguistic editing, after editing with Step-Audio-EditX, the performance of paralinguistic reproduction is comparable to that achieved by the built-in voices of closed-source models when synthesizing native paralinguistic content directly. (sub means replacement of paralinguistic tags with native words)
| Language | Model | Emotion ↑ | Speaking Style ↑ | Paralinguistic ↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Iter0 | Iter1 | Iter2 | Iter3 | Iter0 | Iter1 | Iter2 | Iter3 | Iter0 | sub | Iter1 | ||
| Chinese | MiniMax-2.6-hd | 71.6 | 78.6 | 81.2 | 83.4 | 36.7 | 58.8 | 63.1 | 67.3 | 1.73 | 2.80 | 2.90 |
| Doubao-Seed-TTS-2.0 | 67.4 | 77.8 | 80.6 | 82.8 | 38.2 | 60.2 | 65.0 | 64.9 | 1.67 | 2.81 | 2.90 | |
| GPT-4o-mini-TTS | 62.6 | 76.0 | 77.0 | 81.8 | 45.9 | 64.0 | 65.7 | 69.7 | 1.71 | 2.88 | 2.93 | |
| ElevenLabs-v2 | 60.4 | 74.6 | 77.4 | 79.2 | 43.8 | 63.3 | 69.7 | 70.8 | 1.70 | 2.71 | 2.92 | |
| English | MiniMax-2.6-hd | 55.0 | 64.0 | 64.2 | 66.4 | 51.9 | 60.3 | 62.3 | 64.3 | 1.72 | 2.87 | 2.88 |
| Doubao-Seed-TTS-2.0 | 53.8 | 65.8 | 65.8 | 66.2 | 47.0 | 62.0 | 62.7 | 62.3 | 1.72 | 2.75 | 2.92 | |
| GPT-4o-mini-TTS | 56.8 | 61.4 | 64.8 | 65.2 | 52.3 | 62.3 | 62.4 | 63.4 | 1.90 | 2.90 | 2.88 | |
| ElevenLabs-v2 | 51.0 | 61.2 | 64.0 | 65.2 | 51.0 | 62.1 | 62.6 | 64.0 | 1.93 | 2.87 | 2.88 | |
| Average | MiniMax-2.6-hd | 63.3 | 71.3 | 72.7 | 74.9 | 44.2 | 59.6 | 62.7 | 65.8 | 1.73 | 2.84 | 2.89 |
| Doubao-Seed-TTS-2.0 | 60.6 | 71.8 | 73.2 | 74.5 | 42.6 | 61.1 | 63.9 | 63.6 | 1.70 | 2.78 | 2.91 | |
| GPT-4o-mini-TTS | 59.7 | 68.7 | 70.9 | 73.5 | 49.1 | 63.2 | 64.1 | 66.6 | 1.81 | 2.89 | 2.90 | |
| ElevenLabs-v2 | 55.7 | 67.9 | 70.7 | 72.2 | 47.4 | 62.7 | 66.1 | 67.4 | 1.82 | 2.79 | 2.90 | |
| Language | Model | Emotion ↑ | Speaking Style ↑ | Paralinguistic ↑ | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Iter0 | Iter1 | Iter2 | Iter3 | Iter0 | Iter1 | Iter2 | Iter3 | Iter0 | Iter1 | ||
| Chinese | 20251112 | 57.0 | 71.7 | 74.5 | 77.7 | 41.6 | 62.1 | 65.8 | 69.2 | 1.80 | 2.89 |
| 20251128 | 58.7 | 73.6 | 75.1 | 77.8 | 40.4 | 62.1 | 65.3 | 68.0 | 1.80 | 2.89 | |
| 20260129 | 60.1 | 75.0 | 79.1 | 81.6 | 51.1 | 70.0 | 68.9 | 62.4 | 2.07 | 2.91 | |
| English | 20251112 | 49.9 | 60.5 | 61.5 | 63.7 | 50.3 | 62.4 | 64.3 | 63.1 | 2.02 | 2.88 |
| 20251128 | 51.2 | 60.0 | 63.1 | 64.2 | 48.8 | 63.4 | 62.3 | 64.4 | 2.02 | 2.89 | |
| 20260129 | 51.0 | 63.1 | 65.5 | 67.0 | 43.3 | 60.4 | 66.5 | 69.6 | 2.18 | 2.93 | |
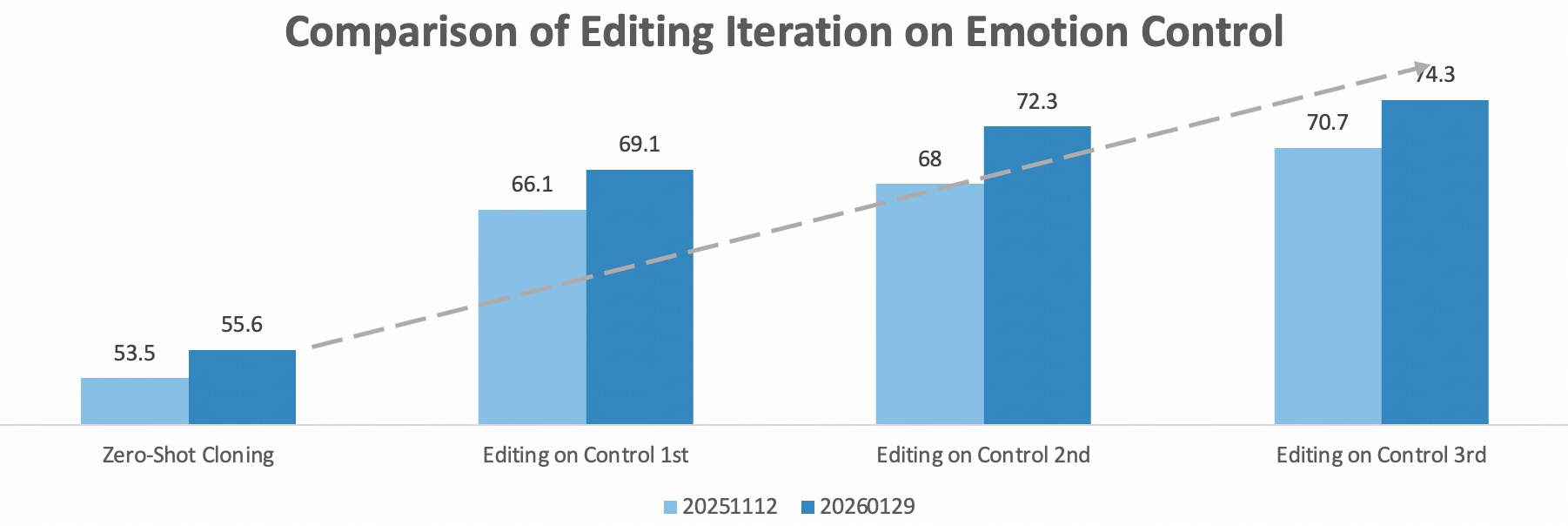
| Average | 20251112 | 53.5 | 66.1 | 68.0 | 70.7 | 46.0 | 62.3 | 65.1 | 66.2 | 1.91 | 2.89 |
| 20251128 | 55.0 | 66.8 | 69.1 | 71.0 | 44.6 | 62.8 | 63.8 | 66.2 | 1.91 | 2.89 | |
| 20260129 | 55.6 | 69.1 | 72.3 | 74.3 | 47.2 | 65.2 | 67.7 | 66.0 | 2.12 | 2.92 | |
Acknowledgements
Part of the code and data for this project comes from:
Thank you to all the open-source projects for their contributions to this project!
License Agreement
- The code in this open-source repository is licensed under the Apache 2.0 License.
Citation
@misc{yan2025stepaudioeditxtechnicalreport,
title={Step-Audio-EditX Technical Report},
author={Chao Yan and Boyong Wu and Peng Yang and Pengfei Tan and Guoqiang Hu and Yuxin Zhang and Xiangyu and Zhang and Fei Tian and Xuerui Yang and Xiangyu Zhang and Daxin Jiang and Gang Yu},
year={2025},
eprint={2511.03601},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2511.03601},
}
⚠️ Usage Disclaimer
- Do not use this model for any unauthorized activities, including but not limited to:
- Voice cloning without permission
- Identity impersonation
- Fraud
- Deepfakes or any other illegal purposes
- Ensure compliance with local laws and regulations, and adhere to ethical guidelines when using this model.
- The model developers are not responsible for any misuse or abuse of this technology.
We advocate for responsible generative AI research and urge the community to uphold safety and ethical standards in AI development and application. If you have any concerns regarding the use of this model, please feel free to contact us.