Supertonic — Lightning Fast, On-Device, Accurate TTS

Supertonic is a lightning-fast, on-device text-to-speech system designed for local inference with minimal overhead. Powered by ONNX Runtime, it runs entirely on your device—no cloud, no API calls, no privacy concerns.
📰 Update News
- 2026.04.29 - 🎉 Supertonic 3 released with 31-language support, improved reading accuracy, fewer repeat/skip failures, and v2-compatible public ONNX assets. Demo | Models
- 2026.01.22 - Voice Builder is now live! Turn your voice into a deployable, edge-native TTS with permanent ownership.
- 2026.01.06 - 🎉 Supertonic 2 released with 5-language support. The v2 code path is preserved on the
release/supertonic-2branch. - 2025.12.10 - Added
supertonicPyPI package! Install viapip install supertonic. For details, visit supertonic-py documentation - 2025.12.10 - Added 6 new voice styles (M3, M4, M5, F3, F4, F5). See Voices for details
- 2025.12.08 - Optimized ONNX models via OnnxSlim now available on Hugging Face Models
- 2025.11.24 - Added Flutter SDK support with macOS compatibility
Quick Start
Install the Python SDK and generate speech immediately. On the first run, Supertonic downloads the model assets from Hugging Face automatically.
pip install supertonic
Python
from supertonic import TTS # First run downloads the model from Hugging Face automatically. tts = TTS(auto_download=True) style = tts.get_voice_style(voice_name="M1") text = "A gentle breeze moved through the open window while everyone listened to the story." wav, duration = tts.synthesize(text, voice_style=style, lang="en") tts.save_audio(wav, "output.wav") print(f"Generated {duration:.2f}s of audio")
Getting Started
First, clone the repository:
git clone https://github.com/supertone-inc/supertonic.git cd supertonic
Prerequisites
Before running the examples, download the ONNX models and preset voices, and place them in the assets directory:
Note: The Hugging Face repository uses Git LFS. Please ensure Git LFS is installed and initialized before cloning or pulling large model files.
- macOS:
brew install git-lfs && git lfs install- Generic: see
https://git-lfs.comfor installers
git lfs install git clone https://huggingface.co/Supertone/supertonic-3 assets
Some language examples need native runtimes:
- Go: install the ONNX Runtime C library. On macOS,
brew install onnxruntimeis enough; the Go example auto-detects Homebrew paths. - Java: use a JDK, not just a JRE. On macOS,
brew install openjdk@17works. - C#: targets .NET 9 and allows major-version roll-forward, so .NET 9 or newer runtimes can run it.
Then run the Python example:
cd py uv sync uv run example_onnx.py
This generates outputs/output.wav using the default preset voice.
Other Runtime Examples
Run Supertonic in other languages and platforms
Node.js Example (Details)
cd nodejs npm install npm start
Browser Example (Details)
cd web npm install npm run dev
Java Example (Details)
cd java mvn clean install mvn exec:java
C++ Example (Details)
cd cpp mkdir build && cd build cmake .. && cmake --build . --config Release ./example_onnx
C# Example (Details)
cd csharp dotnet restore dotnet run
Go Example (Details)
cd go go mod download go run example_onnx.go helper.go
Swift Example (Details)
cd swift swift build -c release .build/release/example_onnx
Rust Example (Details)
cd rust cargo build --release ./target/release/example_onnx
iOS Example (Details)
cd ios/ExampleiOSApp xcodegen generate open ExampleiOSApp.xcodeproj
In Xcode: Targets → ExampleiOSApp → Signing: select your Team, then choose your iPhone as run destination and build.
Technical Details
- Runtime: ONNX Runtime for cross-platform inference
- Browser Support: onnxruntime-web for client-side inference
- Batch Processing: Supports batch inference for improved throughput
- Audio Output: Outputs 16-bit WAV files
Performance Highlights
Supertonic 3 is designed for practical on-device inference: compact enough to run locally, while staying competitive with much larger open TTS systems.
Reading Accuracy
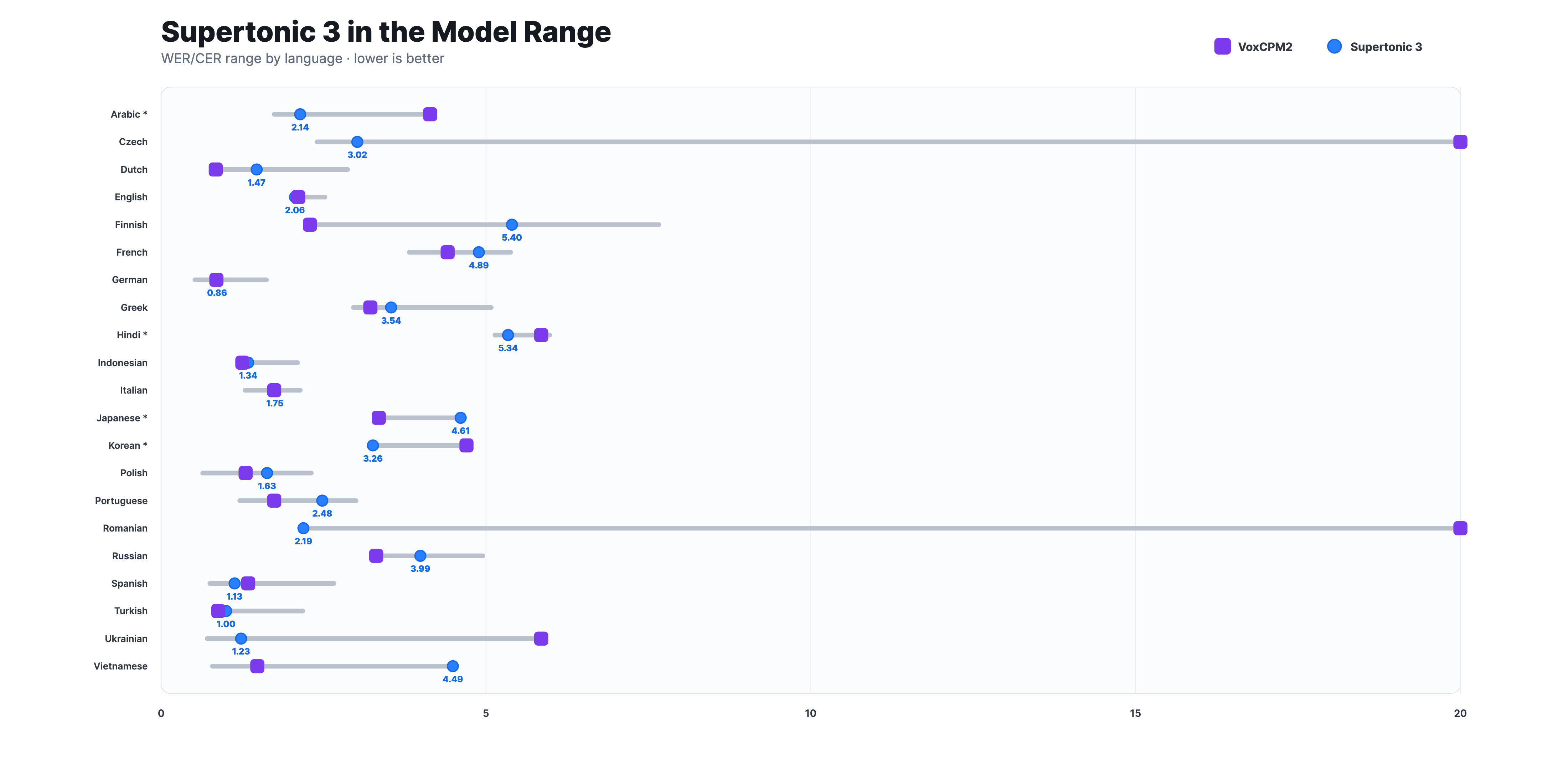
Across measured languages, Supertonic 3 stays within a competitive WER/CER range against much larger open TTS models such as VoxCPM2, while preserving a lightweight on-device deployment path. Asterisked languages use CER; the others use WER.
Supertonic 2 to Supertonic 3
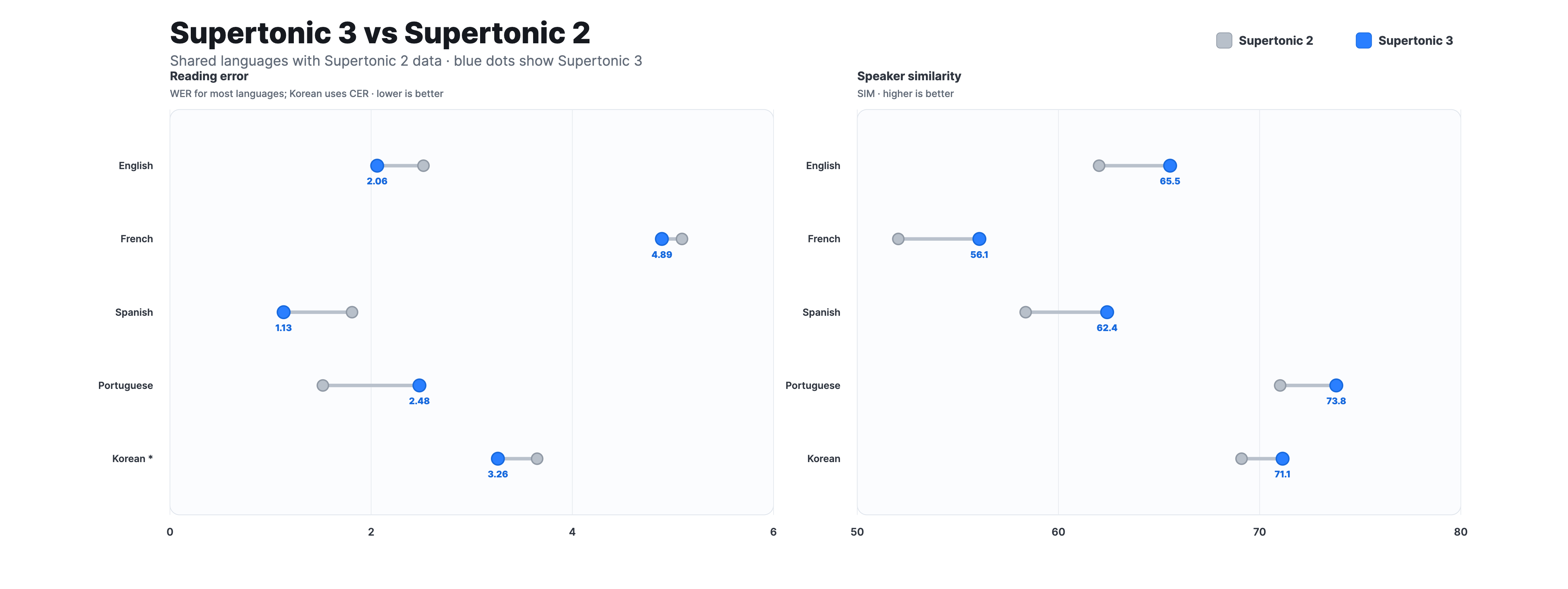
Compared with Supertonic 2, Supertonic 3 reduces repeat and skip failures, improves speaker similarity across the shared-language set, and expands language coverage from 5 to 31 languages. It keeps the v2-compatible public ONNX interface, so existing integrations can move to v3 with the same inference contract.
Runtime Footprint
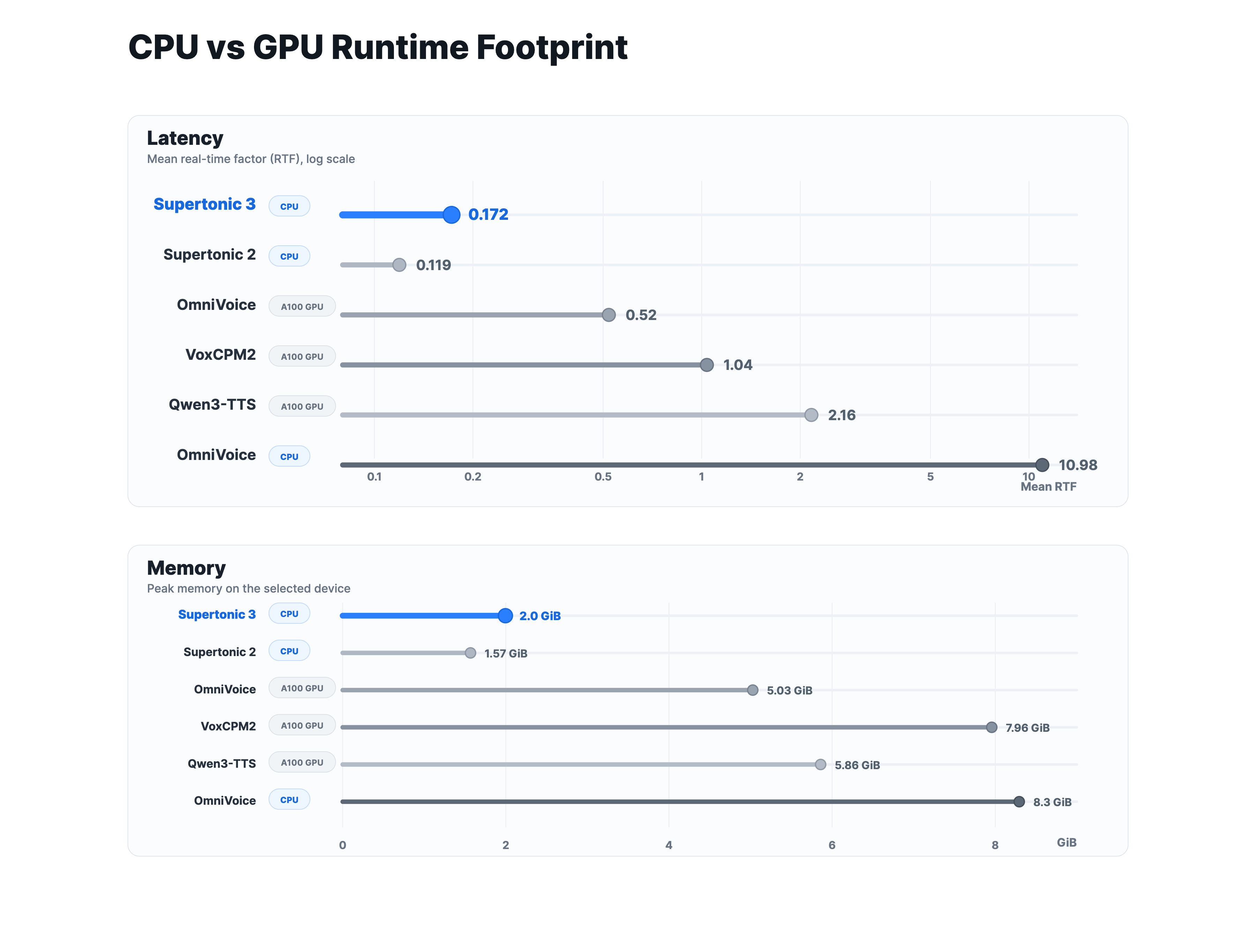
Supertonic 3 runs fast on CPU, even compared with larger baselines measured on A100 GPU, and uses substantially less memory. The open-weight fixed-voice setting does not require a GPU, which makes local, browser, and edge deployment much easier.
Model Size
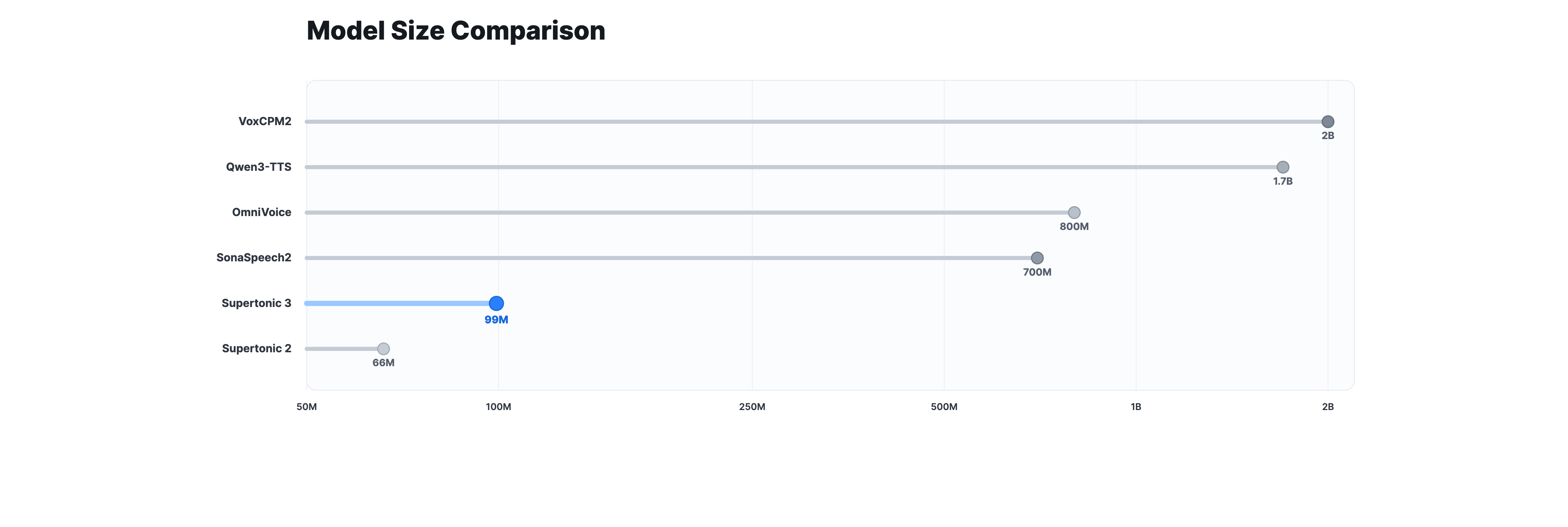
At about 99M parameters across the public ONNX assets, Supertonic 3 is much smaller than 0.7B to 2B class open TTS systems. The smaller model size is a practical advantage for download size, startup time, and on-device inference.
Demo
Try it now: Experience Supertonic in your browser with our Interactive Demo, or get started with pre-trained models from Hugging Face Hub
Raspberry Pi
Watch Supertonic running on a Raspberry Pi, demonstrating on-device, real-time text-to-speech synthesis:
https://github.com/user-attachments/assets/ea66f6d6-7bc5-4308-8a88-1ce3e07400d2
E-Reader
Experience Supertonic on an Onyx Boox Go 6 e-reader in airplane mode, achieving an average RTF of 0.3× with zero network dependency:
https://github.com/user-attachments/assets/64980e58-ad91-423a-9623-78c2ffc13680
Chrome Extension
Turns any webpage into audio in under one second, delivering lightning-fast, on-device text-to-speech with zero network dependency—free, private, and effortless:
https://github.com/user-attachments/assets/cc8a45fc-5c3e-4b2c-8439-a14c3d00d91c
Why Supertonic?
- Blazingly Fast: Optimized for low-latency, on-device speech generation across desktop, browser, and edge deployments
- Lightweight: Compact ONNX assets designed for efficient local execution
- On-Device Capable: Complete privacy and zero network dependency
- Accurate Reading: Improved reading stability with fewer repeat and skip failures
- Expressive Tags: Supports simple expression tags such as
<laugh>,<breath>, and<sigh> - Flexible Deployment: Ready-to-use examples across Python, JavaScript, browser, mobile, and native runtimes
Language Support
Supertonic 3 supports 31 languages:
| Code | Language | Code | Language | Code | Language | Code | Language |
|---|---|---|---|---|---|---|---|
en | English | ko | Korean | ja | Japanese | ar | Arabic |
bg | Bulgarian | cs | Czech | da | Danish | de | German |
el | Greek | es | Spanish | et | Estonian | fi | Finnish |
fr | French | hi | Hindi | hr | Croatian | hu | Hungarian |
id | Indonesian | it | Italian | lt | Lithuanian | lv | Latvian |
nl | Dutch | pl | Polish | pt | Portuguese | ro | Romanian |
ru | Russian | sk | Slovak | sl | Slovenian | sv | Swedish |
tr | Turkish | uk | Ukrainian | vi | Vietnamese |
We provide ready-to-use TTS inference examples across multiple ecosystems:
| Language/Platform | Path | Description |
|---|---|---|
| Python | py/ | ONNX Runtime inference |
| Node.js | nodejs/ | Server-side JavaScript |
| Browser | web/ | WebGPU/WASM inference |
| Java | java/ | Cross-platform JVM |
| C++ | cpp/ | High-performance C++ |
| C# | csharp/ | .NET ecosystem |
| Go | go/ | Go implementation |
| Swift | swift/ | macOS applications |
| iOS | ios/ | Native iOS apps |
| Rust | rust/ | Memory-safe systems |
| Flutter | flutter/ | Cross-platform apps |
For detailed usage instructions, please refer to the README.md in each language directory.
Natural Text Handling
Supertonic is designed to handle complex, real-world text inputs that contain natural prose, punctuation, abbreviations, and proper nouns.
🎧 View audio samples more easily: Check out our Interactive Demo for a better viewing experience of all audio examples
Overview of Test Cases:
| Category | Key Challenges | Supertonic | ElevenLabs | OpenAI | Gemini | Microsoft |
|---|---|---|---|---|---|---|
| Financial Expression | Decimal currency, abbreviated magnitudes (M, K), currency symbols, currency codes | ✅ | ❌ | ❌ | ❌ | ❌ |
| Phone Number | Area codes, hyphens, extensions (ext.) | ✅ | ❌ | ❌ | ❌ | ❌ |
| Technical Unit | Decimal numbers with units, abbreviated technical notations | ✅ | ❌ | ❌ | ❌ | ❌ |
Example 1: Financial Expression
Text:
"The startup secured $5.2M in venture capital, a huge leap from their initial $450K seed round."
Challenges:
- Decimal point in currency ($5.2M should be read as "five point two million")
- Abbreviated magnitude units (M for million, K for thousand)
- Currency symbol ($) that needs to be properly pronounced as "dollars"
Audio Samples:
| System | Result | Audio Sample |
|---|---|---|
| Supertonic | ✅ | 🎧 Play Audio |
| ElevenLabs Flash v2.5 | ❌ | 🎧 Play Audio |
| OpenAI TTS-1 | ❌ | 🎧 Play Audio |
| Gemini 2.5 Flash TTS | ❌ | 🎧 Play Audio |
| VibeVoice Realtime 0.5B | ❌ | 🎧 Play Audio |
Example 2: Phone Number
Text:
"You can reach the hotel front desk at (212) 555-0142 ext. 402 anytime."
Challenges:
- Area code in parentheses that should be read as separate digits
- Phone number with hyphen separator (555-0142)
- Abbreviated extension notation (ext.)
- Extension number (402)
Audio Samples:
| System | Result | Audio Sample |
|---|---|---|
| Supertonic | ✅ | 🎧 Play Audio |
| ElevenLabs Flash v2.5 | ❌ | 🎧 Play Audio |
| OpenAI TTS-1 | ❌ | 🎧 Play Audio |
| Gemini 2.5 Flash TTS | ❌ | 🎧 Play Audio |
| VibeVoice Realtime 0.5B | ❌ | 🎧 Play Audio |
Example 3: Technical Unit
Text:
"Our drone battery lasts 2.3h when flying at 30kph with full camera payload."
Challenges:
- Decimal time duration with abbreviation (2.3h = two point three hours)
- Speed unit with abbreviation (30kph = thirty kilometers per hour)
- Technical abbreviations (h for hours, kph for kilometers per hour)
- Technical/engineering context requiring proper pronunciation
Audio Samples:
| System | Result | Audio Sample |
|---|---|---|
| Supertonic | ✅ | 🎧 Play Audio |
| ElevenLabs Flash v2.5 | ❌ | 🎧 Play Audio |
| OpenAI TTS-1 | ❌ | 🎧 Play Audio |
| Gemini 2.5 Flash TTS | ❌ | 🎧 Play Audio |
| VibeVoice Realtime 0.5B | ❌ | 🎧 Play Audio |
Note: These samples demonstrate how each system handles text normalization and pronunciation of complex expressions without requiring pre-processing or phonetic annotations.
Built with Supertonic
| Project | Description | Links |
|---|---|---|
| TLDRL | Free, on-device TTS extension for reading any webpage | Chrome |
| Read Aloud | Open-source TTS browser extension | Chrome · Edge · GitHub |
| PageEcho | E-Book reader app for iOS | App Store |
| VoiceChat | On-device voice-to-voice LLM chatbot in the browser | Demo · GitHub |
| OmniAvatar | Talking avatar video generator from photo + speech | Demo |
| CopiloTTS | Kotlin Multiplatform TTS SDK via ONNX Runtime | GitHub |
| Voice Mixer | PyQt5 tool for mixing and modifying voice styles | GitHub |
| Supertonic MNN | Lightweight library based on MNN (fp32/fp16/int8) | GitHub · PyPI |
| Transformers.js | Hugging Face's JS library with Supertonic support | GitHub PR · Demo |
| Pinokio | 1-click localhost cloud for Mac, Windows, and Linux | Pinokio · GitHub |
Citation
The following papers describe the core technologies used in Supertonic. If you use this system in your research or find these techniques useful, please consider citing the relevant papers:
SupertonicTTS: Main Architecture
This paper introduces the overall architecture of SupertonicTTS, including the speech autoencoder, flow-matching based text-to-latent module, and efficient design choices.
@article{kim2025supertonic, title={SupertonicTTS: Towards Highly Efficient and Streamlined Text-to-Speech System}, author={Kim, Hyeongju and Yang, Jinhyeok and Yu, Yechan and Ji, Seunghun and Morton, Jacob and Bous, Frederik and Byun, Joon and Lee, Juheon}, journal={arXiv preprint arXiv:2503.23108}, year={2025}, url={https://arxiv.org/abs/2503.23108} }
Length-Aware RoPE: Text-Speech Alignment
This paper presents Length-Aware Rotary Position Embedding (LARoPE), which improves text-speech alignment in cross-attention mechanisms.
@article{kim2025larope, title={Length-Aware Rotary Position Embedding for Text-Speech Alignment}, author={Kim, Hyeongju and Lee, Juheon and Yang, Jinhyeok and Morton, Jacob}, journal={arXiv preprint arXiv:2509.11084}, year={2025}, url={https://arxiv.org/abs/2509.11084} }
Self-Purifying Flow Matching: Training with Noisy Labels
This paper describes the self-purification technique for training flow matching models robustly with noisy or unreliable labels.
@article{kim2025spfm, title={Training Flow Matching Models with Reliable Labels via Self-Purification}, author={Kim, Hyeongju and Yu, Yechan and Yi, June Young and Lee, Juheon}, journal={arXiv preprint arXiv:2509.19091}, year={2025}, url={https://arxiv.org/abs/2509.19091} }
License
This project's sample code is released under the MIT License. - see the LICENSE for details.
The accompanying model is released under the OpenRAIL-M License. - see the LICENSE file for details.
This model was trained using PyTorch, which is licensed under the BSD 3-Clause License but is not redistributed with this project. - see the LICENSE for details.
Copyright (c) 2026 Supertone Inc.