LightMem: Lightweight and Efficient Memory-Augmented Generation

![]()

⭐ If you like our project, please give us a star on GitHub for the latest updates!
LightMem is a lightweight and efficient memory management framework designed for Large Language Models and AI Agents. It provides a simple yet powerful memory storage, retrieval, and update mechanism to help you quickly build intelligent applications with long-term memory capabilities.
-
🚀 Lightweight & Efficient
Minimalist design with minimal resource consumption and fast response times -
🎯 Easy to Use
Simple API design - integrate into your application with just a few lines of code -
🔌 Flexible & Extensible
Modular architecture supporting custom storage engines and retrieval strategies -
🌐 Broad Compatibility
Support for cloud APIs (OpenAI, DeepSeek) and local models (Ollama, vLLM, etc.)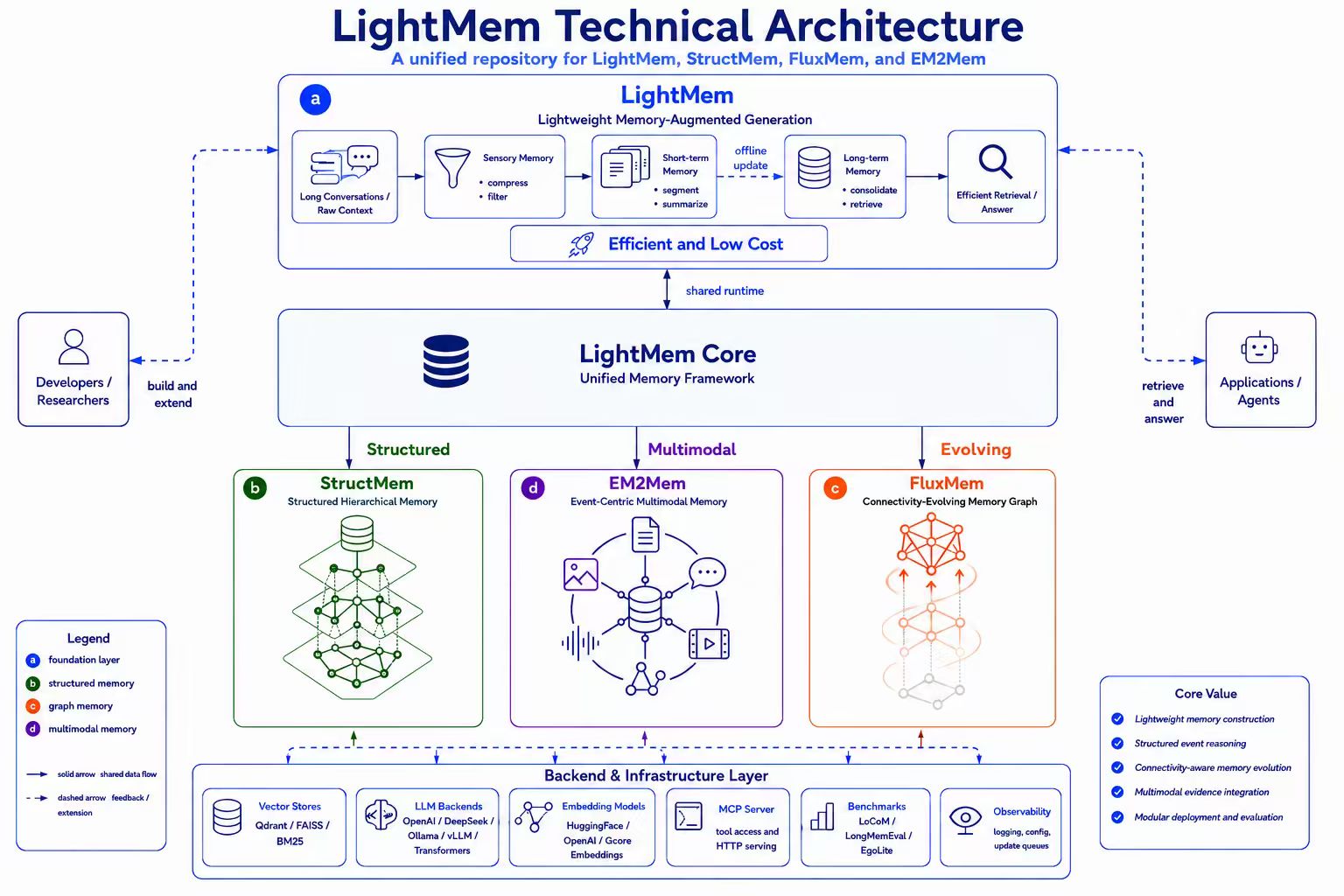
📢 News
- [2026-04-24]: 🚀 LightMem now supports the latest DeepSeek models, including
deepseek-v4-flashanddeepseek-v4-pro, withreasoning_effortand thinking-mode configuration! - [2026-04-24]: 🎉🎉🎉 StructMem: Structured Memory for Long-Horizon Behavior in LLMs has been accepted by ACL 2026!
- [2026-03-21]: 🚀 We provide a more comprehensive baseline evaluation framework, supporting the benchmarking of memory layers such as Mem0, A-MEM, EverMemOS, LangMem on multiple datasets like LoCoMo and LongMemEval.
- [2026-02-15]: 🚀 StructMem is released: A hierarchical memory framework that preserves event-level memory bindings and cross-event memory connections.
- [2026-01-26]: 🎉🎉🎉 LightMem: Lightweight and Efficient Memory-Augmented Generation has been accepted by ICLR 2026!
- [2026-01-17]: 🚀 We provide a comprehensive baseline evaluation framework, supporting the benchmarking of memory layers such as Mem0, A-MEM, and LangMem on multiple datasets like LoCoMo and LongMemEval.
- [2025-12-09]: 🎬 Released a Demo Video showcasing long-context handling, along with comprehensive Tutorial Notebooks for various scenarios!
- [2025-11-30]: 🚌 LightMem now supports calling multiple tools provided by its MCP Server.
- [2025-11-26]: 🚀 Added full LoCoMo dataset support, delivering strong results with leading performance and efficiency! Here is the reproduction script!
- [2025-11-09]: ✨ LightMem now supports local deployment via Ollama, vLLM, and Transformers auto-loading!
- [2025-10-12]: 🎉 LightMem project is officially Open-Sourced!
🧭 Project Navigation
This repository hosts multiple memory methods. The table below provides an overview and links to each method's documentation:
| Method | Description | Paper | Documentation |
|---|---|---|---|
| LightMem | Lightweight and efficient memory-augmented generation framework | ICLR 2026 | README.md |
| FluxMem | Connectivity-evolving memory framework modeling memory as a heterogeneous graph | arXiv (under review at EMNLP 2026) | FluxMem.md |
| EM²Mem | Event-centric multimodal memory for long-video question answering | Coming soon | EM2Mem.md |
| StructMem | Structured hierarchical memory preserving event-level bindings and cross-event connections | ACL 2026 | StructMem.md |
🧪 Reproduction Scripts for LoCoMo & LongMemEval
We provide lightweight, ready-to-run scripts for reproducing results on LoCoMo, LongMemEval, and their combined baselines.
| Dataset | Description | Script | Result |
|---|---|---|---|
| LongMemEval | Run LightMem on LongMemEval, including evaluation and offline memory update. | run_lightmem_longmemeval.md | LongMemEval Results |
| LoCoMo | Scripts for reproducing LightMem results on LoCoMo. | run_lightmem_locomo.md | LoCoMo Results |
| LongMemEval & LoCoMo | Unified baseline scripts for running both datasets. | run_baselines.md | Baseline Results |
🧪 Baseline Evaluation
We provide a comprehensive baseline evaluation framework, supporting the benchmarking of memory layers such as Mem0, A-MEM, and LangMem on multiple datasets like LoCoMo and LongMemEval.
🎥 Demo & Tutorials
Watch Demo: YouTube | Bilibili
📚 Hands-on Tutorials
We provide ready-to-use Jupyter notebooks corresponding to the demo and other use cases. You can find them in the tutorial-notebooks directory.
| Scenario | Description | Notebook Link |
|---|---|---|
| Travel Planning | A complete guide to building a travel agent with memory. | LightMem_Example_travel.ipynb |
| Code Assistant | A complete guide to building a code agent with memory. | LightMem_Example_code.ipynb |
| LongMemEval | A tutorial on how to run evaluations on LongMemEval benchmarks using LightMem. | LightMem_Example_longmemeval.ipynb |
☑️ Todo List
LightMem is continuously evolving! Here's what's coming:
- Offline Pre-computation of KV Cache for Update (Lossless)
- Online Pre-computation of KV Cache Before Q&A (Lossy)
- Integration More Models and Feature Enhancement
- Coordinated Use of Context and Long-Term Memory Storage
- Multi Modal Memory
📑 Table of Contents
- 📢 News
- 🧪 Reproduction Scripts
- 🧪 Baseline Evaluation
- 🧭 Project Navigation
- 🎥 Demo & Tutorials
- ☑️ Todo List
- 🔧 Installation
- ⚡ Quick Start
- 🏗️ Architecture
- 💡 Examples
- 📁 Experimental Results
- ⚙️ Configuration
- 👥 Contributors
- 🔗 Related Projects
🔧 Installation
Installation Steps
Option 1: Install from Source
# Clone the repository
git clone https://github.com/zjunlp/LightMem.git
cd LightMem
# Create virtual environment
conda create -n lightmem python=3.11 -y
conda activate lightmem
# Install dependencies
unset ALL_PROXY
pip install -e .Option 2: Install via pip
pip install lightmem # Coming soon⚡ Quick Start
-
Modify the
JUDGE_MODEL,LLM_MODEL, and their respectiveAPI_KEYandBASE_URLinAPI Configuration. -
Download
LLMLINGUA_MODELfrom microsoft/llmlingua-2-bert-base-multilingual-cased-meetingbank andEMBEDDING_MODELfrom sentence-transformers/all-MiniLM-L6-v2 and modify their paths inModel Paths. -
Download the dataset from longmemeval-cleaned, and modidy the path in
Data Configuration.
cd experiments
python run_lightmem_qwen.py🏗️ Architecture
🗺️ Core Modules Overview
LightMem adopts a modular design, breaking down the memory management process into several pluggable components. The core directory structure exposed to users is outlined below, allowing for easy customization and extension:
LightMem/
├── src/lightmem/ # Main package
│ ├── __init__.py # Package initialization
│ ├── configs/ # Configuration files
│ ├── factory/ # Factory methods
│ ├── memory/ # Core memory management
│ └── memory_toolkits/ # Memory toolkits
├── mcp/ # LightMem MCP server
├── experiments/ # Experiment scripts
├── datasets/ # Datasets files
└── examples/ # Examples🧩 Supported Backends per Module
The following table lists the backends values currently recognized by each configuration module. Use the model_name field (or the corresponding config object) to select one of these backends.
| Module (config) | Supported backends |
|---|---|
PreCompressorConfig | llmlingua-2, entropy_compress |
TopicSegmenterConfig | llmlingua-2 |
MemoryManagerConfig | openai, deepseek, ollama, vllm, etc. |
TextEmbedderConfig | huggingface |
MMEmbedderConfig | huggingface |
RetrieverConfig | qdrant, FAISS, BM25 |
💡 Examples
Initialize LightMem
import os
from datetime import datetime
from lightmem.memory.lightmem import LightMemory
LOGS_ROOT = "./logs"
RUN_TIMESTAMP = datetime.now().strftime("%Y%m%d_%H%M%S")
RUN_LOG_DIR = os.path.join(LOGS_ROOT, RUN_TIMESTAMP)
os.makedirs(RUN_LOG_DIR, exist_ok=True)
API_KEY='your_api_key'
API_BASE_URL='your_api_base_url'
LLM_MODEL='your_model_name' # such as 'gpt-4o-mini' (API) or 'gemma3:latest' (Local Ollama) ...
EMBEDDING_MODEL_PATH='/your/path/to/models/all-MiniLM-L6-v2'
LLMLINGUA_MODEL_PATH='/your/path/to/models/llmlingua-2-bert-base-multilingual-cased-meetingbank'
config_dict = {
"pre_compress": True,
"pre_compressor": {
"model_name": "llmlingua-2",
"configs": {
"llmlingua_config": {
"model_name": LLMLINGUA_MODEL_PATH,
"device_map": "cuda",
"use_llmlingua2": True,
},
}
},
"topic_segment": True,
"precomp_topic_shared": True,
"topic_segmenter": {
"model_name": "llmlingua-2",
},
"messages_use": "user_only",
"metadata_generate": True,
"text_summary": True,
"memory_manager": {
"model_name": 'xxx', # such as 'openai' or 'ollama' ...
"configs": {
"model": LLM_MODEL,
"api_key": API_KEY,
"max_tokens": 16000,
"xxx_base_url": API_BASE_URL # API model specific, such as 'openai_base_url' or 'deepseek_base_url' ...
}
},
"extract_threshold": 0.1,
"index_strategy": "embedding",
"text_embedder": {
"model_name": "huggingface",
"configs": {
"model": EMBEDDING_MODEL_PATH,
"embedding_dims": 384,
"model_kwargs": {"device": "cuda"},
},
},
"retrieve_strategy": "embedding",
"embedding_retriever": {
"model_name": "qdrant",
"configs": {
"collection_name": "my_long_term_chat",
"embedding_model_dims": 384,
"path": "./my_long_term_chat",
}
},
"summary_retriever": {
"model_name": "qdrant",
"configs": {
"collection_name": "my_chat_summaries",
"embedding_model_dims": 384,
"path": "./my_chat_summaries",
}
},
"update": "offline",
"logging": {
"level": "DEBUG",
"file_enabled": True,
"log_dir": RUN_LOG_DIR,
}
}
lightmem = LightMemory.from_config(config_dict)Add Memory
session = {
"timestamp": "2025-01-10",
"turns": [
[
{"role": "user", "content": "My favorite ice cream flavor is pistachio, and my dog's name is Rex."},
{"role": "assistant", "content": "Got it. Pistachio is a great choice."}],
]
}
for turn_messages in session["turns"]:
timestamp = session["timestamp"]
for msg in turn_messages:
msg["time_stamp"] = timestamp
store_result = lightmem.add_memory(
messages=turn_messages,
force_segment=True,
force_extract=True
)Offline Update
lightmem.construct_update_queue_all_entries()
lightmem.offline_update_all_entries(score_threshold=0.8)Generate summaries
summary_result = lightmem.summarize()Retrieve Memory
question = "What is the name of my dog?"
related_memories = lightmem.retrieve(question, limit=5)
print(related_memories)MCP Server
LightMem also supports the Model Context Protocol (MCP) server:
# Running at Root Directory
cd LightMem
# Environment
pip install '.[mcp]'
# MCP Inspector [Optional]
npx @modelcontextprotocol/inspector python mcp/server.py
# Start API by HTTP (http://127.0.0.1:8000/mcp)
fastmcp run mcp/server.py:mcp --transport http --port 8000The MCP config json file of your local client may looks like:
{
"yourMcpServers": {
"LightMem": {
"url": "http://127.0.0.1:8000/mcp",
"otherParameters": "..."
}
}
}📁 Experimental Results
For transparency and reproducibility, we have shared the results of our experiments on Google Drive. This includes model outputs, evaluation logs, and predictions used in our study.
🔗 Access the data here: Google Drive - Experimental Results
Please feel free to download, explore, and use these resources for research or reference purposes.
LOCOMO:
Overview
backbone: gpt-4o-mini, judge model: gpt-4o-mini & qwen2.5-32b-instruct
| Method | ACC(%) gpt-4o-mini | ACC(%) qwen2.5-32b-instruct | Memory-Con Tokens(k) Total | QA Tokens(k) total | Total(k) | Calls | Runtime(s) total |
|---|---|---|---|---|---|---|---|
| FullText | 73.83 | 73.18 | – | 54,884.479 | 54,884.479 | – | 6,971 |
| NaiveRAG | 63.64 | 63.12 | – | 3,870.187 | 3,870.187 | – | 1,884 |
| A-MEM | 64.16 | 60.71 | 11,494.344 | 10,170.567 | 21,664.907 | 11,754 | 67,084 |
| MemoryOS(eval) | 58.25 | 61.04 | 2,870.036 | 7,649.343 | 10,519.379 | 5,534 | 26,129 |
| MemoryOS(pypi) | 54.87 | 55.91 | 5,264.801 | 6,126.111 | 11,390.004 | 10,160 | 37,912 |
| Mem0 | 36.49 | 37.01 | 24,304.872 | 1,488.618 | 25,793.490 | 19,070 | 120,175 |
| Mem0(api) | 61.69 | 61.69 | 68,347.720 | 4,169.909 | 72,517.629 | 6,022 | 10,445 |
| Mem0-g(api) | 60.32 | 59.48 | 69,684.818 | 4,389.147 | 74,073.965 | 6,022 | 10,926 |
backbone: qwen3-30b-a3b-instruct-2507, judge model: gpt-4o-mini & qwen2.5-32b-instruct
| Method | ACC(%) gpt-4o-mini | ACC(%) qwen2.5-32b-instruct | Memory-Con Tokens(k) Total | QA Tokens(k) total | Total(k) | Calls | Runtime(s) total |
|---|---|---|---|---|---|---|---|
| FullText | 74.87 | 74.35 | – | 60,873.076 | 60,873.076 | – | 10,555 |
| NaiveRAG | 66.95 | 64.68 | – | 4,271.052 | 4,271.052 | – | 1,252 |
| A-MEM | 56.10 | 54.81 | 16,267.997 | 17,340.881 | 33,608.878 | 11,754 | 69,339 |
| MemoryOS(eval) | 61.04 | 59.81 | 3,615.087 | 9,703.169 | 11,946.442 | 4,147 | 13,710 |
| MemoryOS(pypi) | 51.30 | 51.95 | 6,663.527 | 7,764.991 | 14,428.518 | 10,046 | 20,830 |
| Mem0 | 43.31 | 43.25 | 17,994.035 | 1,765.570 | 19,759.605 | 16,145 | 46,500 |
Details
backbone: gpt-4o-mini, judge model: gpt-4o-mini & qwen2.5-32b-instruct
| Method | Summary Tokens(k) In | Summary Tokens(k) Out | Update Tokens(k) In | Update Tokens(k) Out | QA Tokens(k) In | QA Tokens(k) Out | Runtime(s) mem-con | Runtime(s) qa |
|---|---|---|---|---|---|---|---|---|
| FullText | – | – | – | – | 54,858.770 | 25.709 | – | 6,971 |
| NaiveRAG | – | – | – | – | 3,851.029 | 19.158 | – | 1,884 |
| A-MEM | 1,827.373 | 492.883 | 7,298.878 | 1,875.210 | 10,113.252 | 57.315 | 60,607 | 6,477 |
| MemoryOS(eval) | 1,109.849 | 333.970 | 780.807 | 645.410 | 7,638.539 | 10.804 | 24,220 | 1,909 |
| MemoryOS(pypi) | 1,007.729 | 294.601 | 3,037.509 | 924.962 | 6,116.239 | 9.872 | 33,325 | 4,587 |
| Mem0 | 8,127.398 | 253.187 | 12,722.011 | 3,202.276 | 1,478.830 | 9.788 | 118,268 | 1,907 |
| Mem0(api) | \ | \ | \ | \ | 4,156.850 | 13.059 | 4,328 | 6,117 |
| Mem0-g(api) | \ | \ | \ | \ | 4,375.900 | 13.247 | 5,381 | 5,545 |
backbone: qwen3-30b-a3b-instruct-2507, judge model: gpt-4o-mini & qwen2.5-32b-instruct
| Method | Summary Tokens(k) In | Summary Tokens(k) Out | Update Tokens(k) In | Update Tokens(k) Out | QA Tokens(k) In | QA Tokens(k) Out | Runtime(s) mem-con | Runtime(s) qa |
|---|---|---|---|---|---|---|---|---|
| FullText | – | – | – | – | 60,838.694 | 34.382 | – | 10,555 |
| NaiveRAG | – | – | – | – | 4,239.030 | 32.022 | – | 1,252 |
| A-MEM | 1,582.942 | 608.507 | 9,241.928 | 4,835.070 | 17,528.876 | 82.005 | 55,439 | 13,900 |
| MemoryOS(eval) | 1,222.139 | 531.157 | 1,044.307 | 817.484 | 9,679.996 | 23.173 | 12,697 | 1,012 |
| MemoryOS(pypi) | 2,288.533 | 516.024 | 2,422.693 | 1,436.277 | 7,743.391 | 21.600 | 19,822 | 1,007 |
| Mem0 | 8,270.874 | 186.354 | 7,638.827 | 1,897.980 | 1,739.246 | 26.324 | 45,407 | 1,093 |
Performance metrics
backbone: gpt-4o-mini, judge model: gpt-4o-mini
| Method | Overall ↑ | Multi | Open | Single | Temp |
|---|---|---|---|---|---|
| FullText | 73.83 | 68.79 | 56.25 | 86.56 | 50.16 |
| NaiveRAG | 63.64 | 55.32 | 47.92 | 70.99 | 56.39 |
| A-MEM | 64.16 | 56.03 | 31.25 | 72.06 | 60.44 |
| MemoryOS(eval) | 58.25 | 56.74 | 45.83 | 67.06 | 40.19 |
| MemoryOS(pypi) | 54.87 | 52.13 | 43.75 | 63.97 | 36.76 |
| Mem0 | 36.49 | 30.85 | 34.38 | 38.41 | 37.07 |
| Mem0(api) | 61.69 | 56.38 | 43.75 | 66.47 | 59.19 |
| Mem0-g(api) | 60.32 | 54.26 | 39.58 | 65.99 | 57.01 |
backbone: gpt-4o-mini, judge model: qwen2.5-32b-instruct
| Method | Overall ↑ | Multi | Open | Single | Temp |
|---|---|---|---|---|---|
| FullText | 73.18 | 68.09 | 54.17 | 86.21 | 49.22 |
| NaiveRAG | 63.12 | 53.55 | 50.00 | 71.34 | 53.89 |
| A-MEM | 60.71 | 53.55 | 32.29 | 69.08 | 53.58 |
| MemoryOS(eval) | 61.04 | 64.18 | 40.62 | 70.15 | 40.50 |
| MemoryOS(pypi) | 55.91 | 52.48 | 41.67 | 66.35 | 35.83 |
| Mem0 | 37.01 | 31.91 | 37.50 | 38.53 | 37.38 |
| Mem0(api) | 61.69 | 54.26 | 46.88 | 67.66 | 57.01 |
| Mem0-g(api) | 59.48 | 55.32 | 42.71 | 65.04 | 53.58 |
backbone: qwen3-30b-a3b-instruct-2507, judge model: gpt-4o-mini
| Method | Overall ↑ | Multi | Open | Single | Temp |
|---|---|---|---|---|---|
| FullText | 74.87 | 69.86 | 57.29 | 87.40 | 51.71 |
| NaiveRAG | 66.95 | 62.41 | 57.29 | 76.81 | 47.98 |
| A-MEM | 56.10 | 57.45 | 43.75 | 67.90 | 27.73 |
| MemoryOS(eval) | 61.04 | 62.77 | 51.04 | 72.29 | 33.02 |
| MemoryOS(pypi) | 51.30 | 52.48 | 40.62 | 61.59 | 26.48 |
| Mem0 | 43.31 | 42.91 | 46.88 | 46.37 | 34.58 |
| Mem0(api) | 61.69 | 54.26 | 46.88 | 67.66 | 57.01 |
| Mem0-g(api) | 59.48 | 55.32 | 42.71 | 65.04 | 53.58 |
backbone: qwen3-30b-a3b-instruct-2507, judge model: qwen2.5-32b-instruct
| Method | Overall ↑ | Multi | Open | Single | Temp |
|---|---|---|---|---|---|
| FullText | 74.35 | 68.09 | 63.54 | 86.33 | 51.71 |
| NaiveRAG | 64.68 | 60.28 | 52.08 | 75.62 | 43.61 |
| A-MEM | 54.81 | 56.74 | 39.58 | 67.42 | 24.61 |
| MemoryOS(eval) | 59.81 | 63.12 | 48.96 | 70.51 | 32.09 |
| MemoryOS(pypi) | 51.95 | 55.67 | 39.58 | 61.47 | 27.41 |
| Mem0 | 43.25 | 45.04 | 46.88 | 45.78 | 33.96 |
| Mem0(api) | 61.69 | 54.26 | 46.88 | 67.66 | 57.01 |
| Mem0-g(api) | 59.48 | 55.32 | 42.71 | 65.04 | 53.58 |
⚙️ Configuration
All behaviors of LightMem are controlled via the BaseMemoryConfigs configuration class. Users can customize aspects like pre-processing, memory extraction, retrieval strategy, and update mechanisms by providing a custom configuration.
Key Configuration Options (Usage)
| Option | Default | Usage (allowed values and behavior) |
|---|---|---|
pre_compress | False | True / False. If True, input messages are pre-compressed using the pre_compressor configuration before being stored. This reduces storage and indexing cost but may remove fine-grained details. If False, messages are stored without pre-compression. |
pre_compressor | None | dict / object. Configuration for the pre-compression component (PreCompressorConfig) with fields like model_name (e.g., llmlingua-2, entropy_compress) and configs (model-specific parameters). Effective only when pre_compress=True. |
topic_segment | False | True / False. Enables topic-based segmentation of long conversations. When True, long conversations are split into topic segments and each segment can be indexed/stored independently (requires topic_segmenter). When False, messages are stored sequentially. |
precomp_topic_shared | False | True / False. If True, pre-compression and topic segmentation can share intermediate results to avoid redundant processing. May improve performance but requires careful configuration to avoid cross-topic leakage. |
topic_segmenter | None | dict / object. Configuration for topic segmentation (TopicSegmenterConfig), including model_name and configs (segment length, overlap, etc.). Used when topic_segment=True. |
messages_use | 'user_only' | 'user_only' / 'assistant_only' / 'hybrid'. Controls which messages are used to generate metadata and summaries: user_only uses user inputs, assistant_only uses assistant responses, hybrid uses both. Choosing hybrid increases processing but yields richer context. |
metadata_generate | True | True / False. If True, metadata such as keywords and entities are extracted and stored to support attribute-based and filtered retrieval. If False, no metadata extraction occurs. |
text_summary | True | True / False. If True, a text summary is generated and stored alongside the original text (reduces retrieval cost and speeds review). If False, only the original text is stored. Summary quality depends on memory_manager. |
memory_manager | MemoryManagerConfig() | dict / object. Controls the model used to generate summaries and metadata (MemoryManagerConfig), e.g., model_name (openai, ollama, etc.) and configs. Changing this affects summary style, length, and cost. |
extract_threshold | 0.5 | float (0.0 - 1.0). Threshold used to decide whether content is important enough to be extracted as metadata or highlight. Higher values (e.g., 0.8) mean more conservative extraction; lower values (e.g., 0.2) extract more items (may increase noise). |
index_strategy | None | 'embedding' / 'context' / 'hybrid' / None. Determines how memories are indexed: 'embedding' uses vector-based indexing (requires embedders/retriever) for semantic search; 'context' uses text-based/contextual retrieval (requires context_retriever) for keyword/document similarity; and 'hybrid' combines context filtering and vector reranking for robustness and higher accuracy. |
text_embedder | None | dict / object. Configuration for text embedding model (TextEmbedderConfig) with model_name (e.g., huggingface) and configs (batch size, device, embedding dim). Required when index_strategy or retrieve_strategy includes 'embedding'. |
multimodal_embedder | None | dict / object. Configuration for multimodal/image embedder (MMEmbedderConfig). Used for non-text modalities. |
history_db_path | os.path.join(lightmem_dir, "history.db") | str. Path to persist conversation history and lightweight state. Useful to restore state across restarts. |
retrieve_strategy | 'embedding' | 'embedding' / 'context' / 'hybrid'. Strategy used at query time to fetch relevant memories. Pick based on data and query type: semantic queries -> 'embedding'; keyword/structured queries -> 'context'; mixed -> 'hybrid'. |
context_retriever | None | dict / object. Configuration for context-based retriever (ContextRetrieverConfig), e.g., model_name='BM25' and configs like top_k. Used when retrieve_strategy includes 'context'. |
embedding_retriever | None | dict / object. Vector store configuration (EmbeddingRetrieverConfig), e.g., model_name='qdrant' and connection/index params. Used when retrieve_strategy includes 'embedding'. |
summary_retriever | None | dict / object. Configuration for summary-specific vector store (EmbeddingRetrieverConfig). When configured, summaries are stored in a separate collection for hierarchical retrieval. Used in StructMem mode to store and retrieve session/topic summaries independently from detailed memories. |
update | 'offline' | 'online' / 'offline'. 'offline': batch or scheduled updates to save cost and aggregate changes — this is the fully supported mode with complete functionality. 'online': reserved for future development (currently a no-op placeholder; memory will not be persisted when this mode is set). |
kv_cache | False | True / False. If True, attempt to precompute and persist model KV caches to accelerate repeated LLM calls (requires support from the LLM runtime and may increase storage). Uses kv_cache_path to store cache. |
kv_cache_path | os.path.join(lightmem_dir, "kv_cache.db") | str. File path for KV cache storage when kv_cache=True. |
graph_mem | False | True / False. When True, some memories will be organized as a graph (nodes and relationships) to support complex relation queries and reasoning. Requires additional graph processing/storage. |
extraction_mode | 'flat' | 'flat' / 'event'. Memory extraction mode: 'flat' extracts factual entries as independent units suitable for general knowledge retention; 'event' extracts event-level structures with both factual and relational components, preserving temporal bindings and causal relationships. Use 'event' for narrative-heavy or time-sensitive scenarios. |
version | 'v1.1' | str. Configuration/API version. Only change if you know compatibility implications. |
logging | 'None' | dict / object. Configuration for logging enabled. |
(Option) BoundMem Configuration:
BoundMem tag fallback is intentionally opt-in and is not enabled by BaseMemoryConfigs by default. The following are parameters related to the BoundMem plugin in the main functions, which can be added as needed:
| Function | Parameter / Behavior | Notes |
|---|---|---|
add_memory() | boundmem_tags | Tags newly created memories before insertion. Accepts a string or tag list. |
retrieve() | boundmem_tags | Filters retrieved memories by overlap with the current tags. |
retrieve() | boundmem_drop_untagged | Keeps untagged legacy memories by default; set True to drop them. |
retrieve() | returned memory text | Internal tag prefixes are stripped before results are returned. |
resolve_tags() | strategy="hard" | Uses caller-provided hard_tags. |
resolve_tags() | strategy="soft" | Uses environment_tag_fn with query, history, known_tags, and optional metadata. |
resolve_tags() | known_tags | Caller-maintained tag list; returned together with newly resolved tags. |
tag_text() / strip_tags() | string-level helpers | Add or remove the internal tag prefix for custom integrations. |
filter_by_tags() | raw retriever-result helper | Keeps memories with overlapping tags; accepts custom tag_match_fn. |
| Matching rule | default matcher | A memory is kept if it shares at least one tag with current tags. |
🏆 Contributors

JizhanFang |

Xinle-Deng |

Xubqpanda |

HaomingX |

453251 |

James-TYQ |

evy568 |

Norah-Feathertail |

TongjiCst |





